
So far we've been using just the Elements (or in Firebug, the HTML) panel of the web inspector. This is just one of the inspector's many interfaces and one that is particularly useful to web designers.
Data-seekers will get even more utility out of the network panel, which provides a way to directly examine the data and logic underneath the webpage you see.
Some webpages will be impossible to scrape with a HTML parser because they dynamically load in data through Javascript or Flash. In these cases, we need to use the network panel to examine the source of these data requests. Then we can write a program that targets these addresses, bypassing the need to scrape the webpage's HTML.
The big picture is this: A webpage and its HTML is mainly a way to display information for a web browser to render so that it's visually comprehendible to humans. However, our webscrapers don't need to "see" a pretty version of the data. And so in cases where we can find the source of the raw data before it is formatted for the webpage, it works towards our benefit as programmers.
The network panel merely makes it much easier to locate these raw data requests.
This chapter covers all the basics of using the inspector's network panel but the detailed sections are not complete. I will revisit them in a future update to this chapter.
Activate your network panel
In your web inspector, click the tab labeled Network (or Net, in Firebug). Load up any website; below is a screenshot of USA.gov:
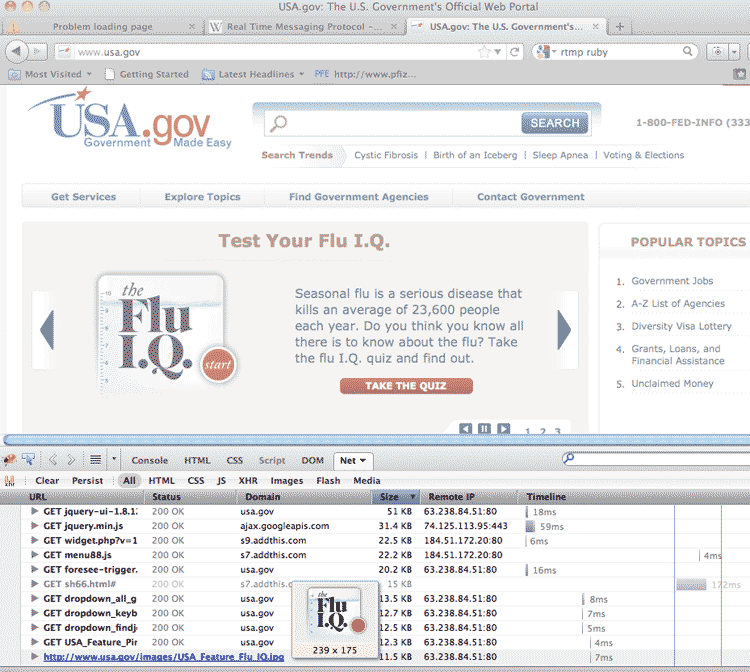
The network panel is in the bottom half of the browser. In this view, I can see a listing of every file that my browser loads when visiting USA.gov. This includes images, external Javascript files, Flash applications, and any other data files. There is information useful to developers, such as when and how long it takes for each file to load up.
For those who are interested in scraping the page, even just the file listing is useful. We saw in the last chapter that the web inspector doesn't really reveal anything about a webpage that isn't already in the HTML, it just makes it a lot easier. Likewise, its network panel provides an easy-to-read listing of all the files the webpage depends on.
But a webpage's HTML does not contain the data that is brought in after the webpage itself has loaded, i.e. anything that happens during what the web-scraping overview chapter calls Steps 5 and Steps 6. An example of this is the "infinite scroll" effect, in which new data is loaded onto the page when the user reaches the bottom (I cover Twitter's use of it later in this chapter).
Revisiting the Wikipedia search term suggester
In the web-scraping overview, I used Wikipedia's search box as a simple example of dynamic data in action. But I didn't cover how you could actually find the dynamically-loaded file yourself.
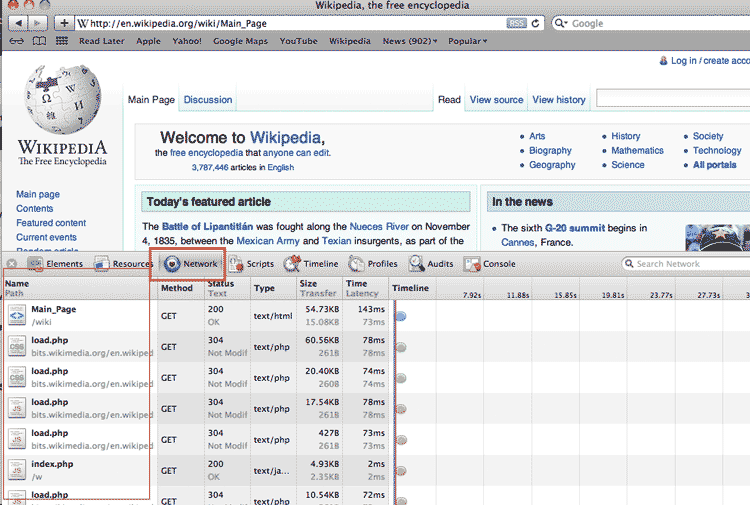
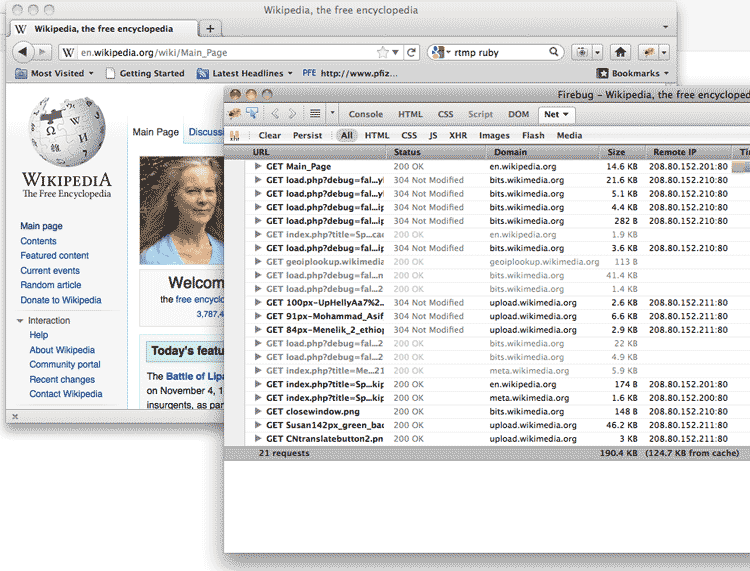
So first make sure the network panel of your web inspector is active. Then visit the Wikipedia homepage. The network panel should light up with a data table:
A quick tip: If it's hard to see everything with the inspector panel at the bottom, you can pop the inspector out into its own window: In the table below, I've highlighted the clickable hotspots that activate this:
| Safari/Chrome | Firefox + Firebug |
|---|---|
 |
 |
| |
Type into the search box
Enter a single letter into the search box in the top right. A dropdown menu of suggested terms should appear as before. Now check your inspector's network panel. You might not see any change in the file listing.

Select the XHR filter
The acronym XHR stands for XMLHttpRequest, which is the technical term for the requests made to the server by the browser. In this case, we're looking for the data request for a list of suggested search terms that begin with 'J'; this request is made by the browser to the server when we enter J into the search field:
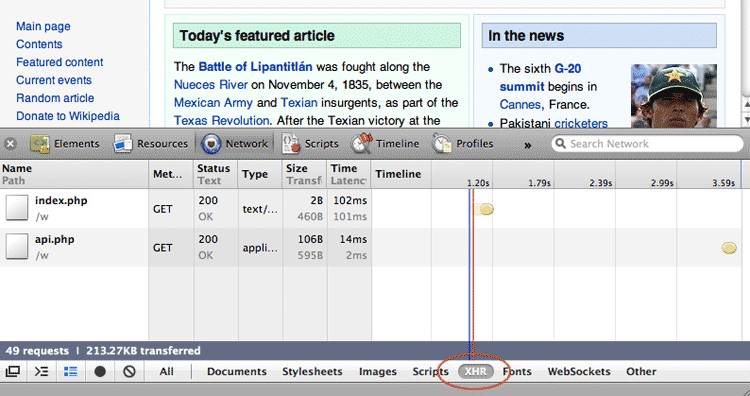
In Firebug, the filter submenu with XHR is at the top of the inspector panel
So far, it looks like two such requests were made. Before looking into these in detail, let's activate another data request now that the XHR filter is on.
Enter a second letter into search box
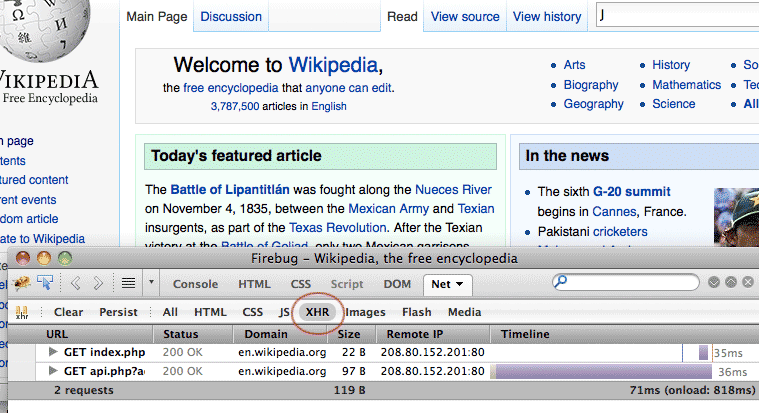
If typing one letter into the search box triggered a XHR event, let's try a second letter:
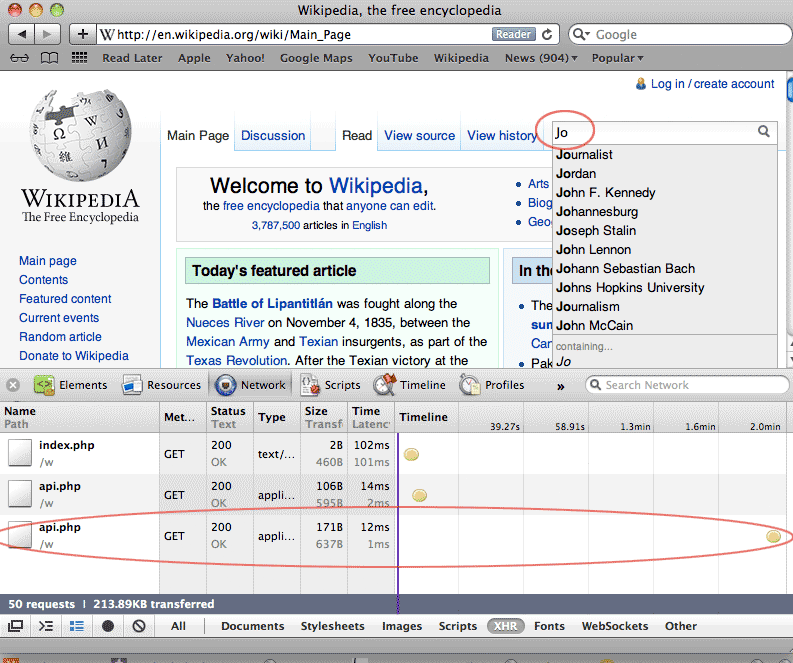
Lo and behold, a new XHR entry appears in the network panel. It appears that the request for suggested search terms uses a server-side script named api.php
View the Response/Content tab
Now click on the latest api.php entry. A new detailed view should come up; the sub-tab labeled Content – or "Response" if you're using Firebug – should be active:
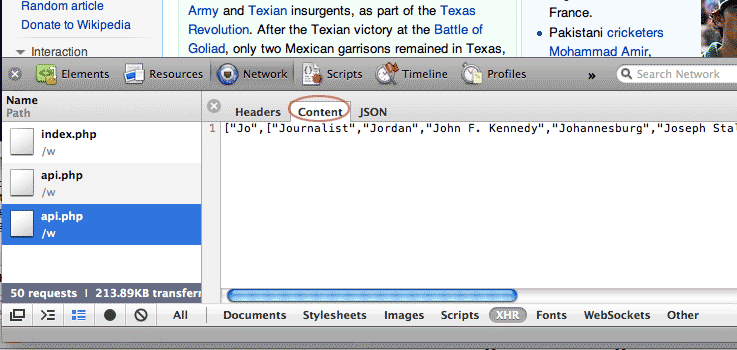
The "content" of api.php contains what we expect: a data-structure listing the search terms for the partial search
View the Headers tab
While we're examining the api.php response, click the Headers sub-tab; another detail window should come up (the following view is for Chrome/Safari):
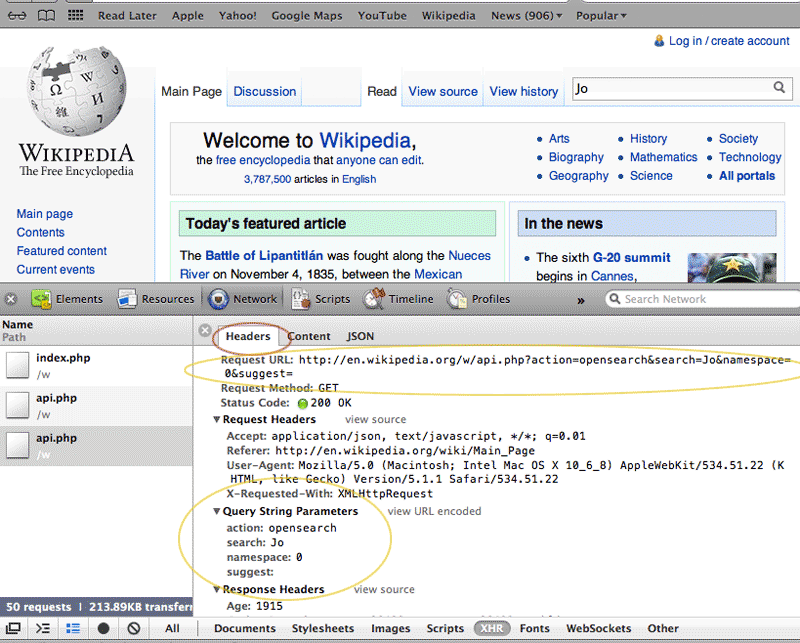
Even without knowing exactly what "Request URL" and "Query String Parameters" stand for, you can see their relation to what we typed in the search box.
Let's look at the query string parameters first:
action opensearch namespace 0 search Jo suggest
So the search parameter contains what we typed into the search box. The other parameters seem to be preset. In fact, api.php is a script for various Wikipedia functions. Setting the action parameter to opensearch is how the browser's Javascript specifies the exact function: a request for search terms. You can read more about the API here if you're interested.
Now let's examine the Request URL. In Chrome/Safari, it's listed as part of the Headers sub-tab. In Firebug, right-click on the Params subtab and pick Copy Location.
This is the Request URL:
http://en.wikipedia.org/w/api.php?action=opensearch&search=Jo&namespace=0&suggest=
Can you see how the query string parameters map to the Request URL? If you visit that URL in your browser (it may prompt you as if you were downloading a file, which you technically are), you'll see the same array of search terms as you did in the network panel. Try altering that Request URL; how would you find the suggested search terms for "Xo"?
Bypassing the Browser
We just covered a lot of steps, but let's make sure we have the big picture here. The network panel didn't reveal anything we couldn't have found with a thorough inspection of the raw HTML and Javascript files. But we're not HTML/JS experts, and even if we were, the inspector's network panel gives us an easy point-and-click interface to cut through the clutter.
One particular nicety of the network panel is that it lets us see data requests to and from the browser in real time.
Twitter's infinite scroll
For example, Twitter webpages have a feature called infinite scroll. Every time you scroll to the bottom of the page, more tweets appear. You don't even have to push a button or click a link.
If you're logged into Twitter on your browser, log out for now. Now visit a Twitter user's page and keep scrolling to the bottom of their list of tweets. Check out how your network panel updates accordingly:
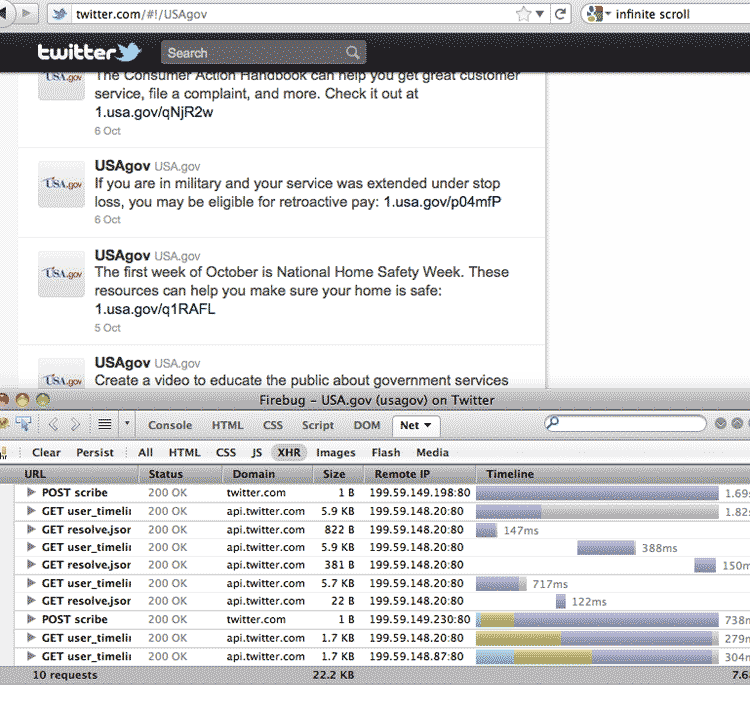
Each time new tweets are appended to the list, the network panel lists a new request for the URL:
http://api.twitter.com/1/statuses/user_timeline.json?max_id=124092248651612160&count=21&include_entities=1&include_available_features=1&contributor_details=true&pc=false&include_rts=true&user_id=14074515
Does that URL look familiar (I've bolded the important part)? It's the API call we made in the introductory chapter to tweet-fetching. Go ahead and visit the link in your browser.
Note: This may prompt you to download a text file. Also, my specific example URL may not work, because of the peculiars of the Twitter API. Use a API call brought up in your own inspector's network panel.
The contents of the text file at that visited URL are the same as in the "Response/Content" tab of your network panel:
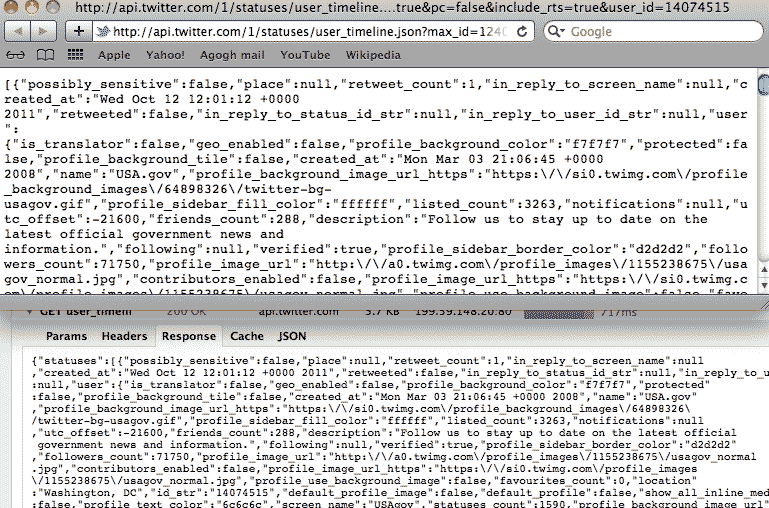
In case you're wondering, JSON is a data structure that, while native to Javascript, consists of what you would recognize as arrays and hashes in Ruby. It's one of the most common data formats due to its lightweightedness. And there are plenty of gems and libraries (including good ol' crack) that can parse it.
Getting direct to the source with Ruby
If you're reading this chapter without having gone through the programming section, you can skip this part.
How does using the network panel fit in with Ruby? Think of the panel as just a way of scouting the target. In the Wikipedia searchbox example, we were able to quickly suss out the URL of the relevant script and the needed parameters. The panel also reveals that it is a simple GET request – something you can visit in-browser, as we've seen.
We have all we need to perform a scrape. If we were interested in collecting what Wikipedia considers the most relevant suggested search terms for each letter of the alphabet, then we could run this simple script:
require 'rubygems'
require 'restclient'
require 'crack'
WURL = 'http://en.wikipedia.org/w/api.php?action=opensearch&namespace=0&suggest=&search='
('A'..'Z').to_a.each do |letter|
resp = RestClient.get("#{WURL}#{letter}", 'User-Agent' => 'Ruby')
arr = Crack::JSON.parse(resp)
puts arr.join(', ')
sleep 0.5
endWhich nets us this:
A, Animal, Association football, Australia, African American (U.S. Census), Allmusic, Arthropod, Album, Actor, Austria, American football B, Brazil, BBC, Bass guitar, Belgium, Billboard (magazine), Boston, Basketball, Berlin, Bird, Billboard Hot 100 C, Canada, Countries of the world, China, California, Census, Chordate, Catholic Church, Communes of France, Chicago, Central European Time
The particular RestClient.get call may look unfamiliar to you:
resp = RestClient.get("#{WURL}#{letter}", 'User-Agent' => 'Ruby')The get method can take in a number of arguments for headers that we want to include with our request. The headers contain information that your browser typically sends during a request. So in essence, adding headers programmatically to our get method call makes the Ruby script to seem more like a browser.
I've included the 'User-Agent' => 'Ruby' header because it seems that Wikipedia will refuse requests to scrapers that don't identify themselves. I could've claimed to be the Firefox browser, but it appears that just putting anything in that header will suffice.
Headers and GET requests are concepts related to HTTP. I'll cover them more in-depth in a later edition of this chapter. For now, check out Wikipedia's excellent reference.
Inspecting a webpage's assets
Let's return to the example of the Flickr photo page in which tricky HTML made it difficult to right-click»Save the featured photo.
Before going to the page, make sure your web inspector panel is open. Click on the Network tab (or Net tab, in Firebug) and filter for Images.
Now revisit the Flickr photo page; you may have to Shift-reload to force the site to resend files already cached by your browser.
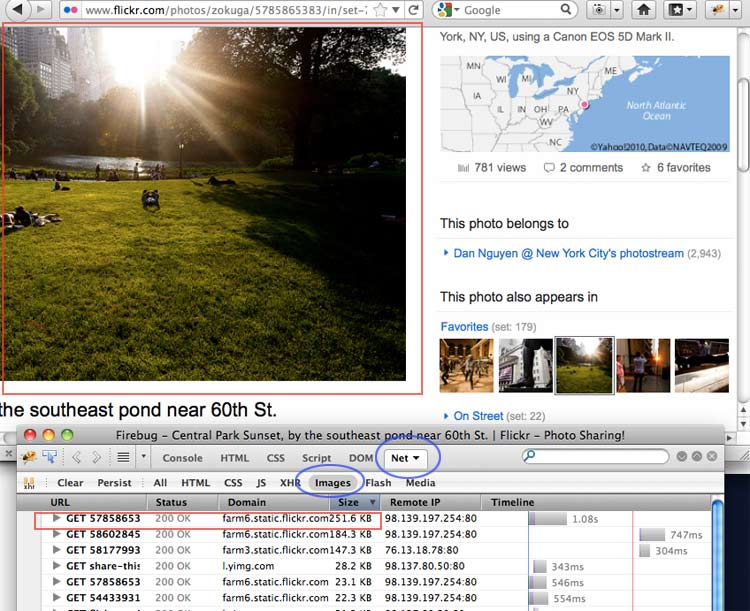
You can see that I've also clicked on the Size table header to sort the files by size in descending order. The lead image tops the list as expected. What's interesting is that even though there is only one lead image, two other images are loaded at the same size (they weigh in at 140-180 KB) but are kept hidden. These two images are actually the photos that are immediately before and after the current photo. Loading them now caches them in your browser so that they are immediately loaded whether you go forward or backwards in the photostream.
So the network panel lets us see what we saw in the last chapter: the URL of the lead image – though this is an arguably quicker way to find it. But the network panel also shows us webpage behavior that isn't evident in the raw HTML: the preloading of the images that are immediately before and after this photo.
Get past Flash
Back when I used to develop slideshows in Flash, I made the mistake of thinking that because Flash apps prevented the View Source/Right Click»Copy actions that are possible on standard web pages, that they make for an effective lockbox in preventing downloads of the actual image files.
But (depending on how they're designed), Flash apps typically load external files during their operation. And this traffic is detectable with the network panel.
Visit the Slideshow view of this Flickr photo in a Flash-enabled browser. As typical with most Flash apps, you don't have many right-click options:
However, if you open up your network panel (don't filter by Images; for some reason, the inspector doesn't classify the image loads as image file types), you can see the details of each image file – including its direct URL.
{kind=link}
Steal these images (or don't)
A sidenote on app design: The point of this exercise is to not encourage the wholesale lifting of photos from artists' sites (though you're welcome to take the ones I've used as demonstrations here; virtually all of my photos are <a href="http://creativecommons.org/licenses/by-nc/2.0/" title="Creative Commons — Attribution-NonCommercial 2.0 Generic — CC BY-NC 2.0">Creative Commons licensed). But it is worth noting that if you are a content-creator, using Flash as a delivery mechanism will not protect you from having your content copied. There are pros and cons to using Flash; copy-prevention is not a primary one.
There are ways to design Flash apps so that the images are embedded into the application itself. However, the tradeoff is that these apps will are very difficult to update because you basically have to enter the Flash environment (i.e. have your own copy of Adobe Flash) and hand-update the files yourself. This is not a fun workflow, from my experience.
In any case, this doesn't protect you from someone just doing a screen-capture of their screen's contents and cropping your photo.
However, from my observation, the vast majority of users are probably unaware of the network panel and/or basic HTML concepts. So the kind of image-URL obfuscation done by Flickr's standard photo pages will probably protect you from most casual copiers. If you really want to maintain credit for your work, you should look into some kind of watermarking scheme (which has its own ups and downs)
Reading datafiles from Flash apps
The Flash photo gallery is just a simple demo of using the network panel. We are not interested in photos, but data. And some data providers, either purposefully or inadvertently, use Flash to display tabular data. It is not possible (usually) to Highlight»Copy»Paste data in these tables.
The Recovery.gov Flash map
The following example is not meant to imply that Recovery.gov is intentionally obfuscating data (in this case, at least) by using a Flash app. The site provides a clear link to a HTML table version of the data. I'm using Recovery.gov only as a simple proof of concept.
Recovery.gov is a U.S. federal website that provides information on the progress and returns from the American Recovery and Reinvestment Act of 2009, i.e. the stimulus program. On the front page, the user is presented with an attractive Flash map of the U.S. The map displays a popup of summary data when you hover over a state with your mouse.
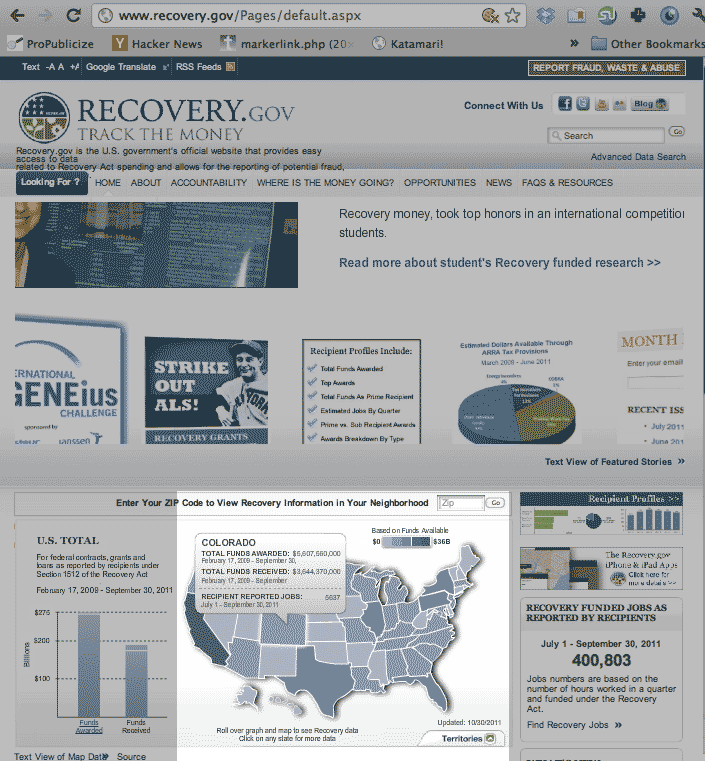
A closeup view of the map:
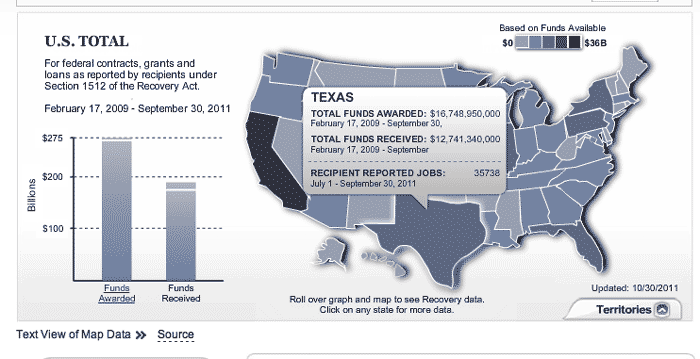
This is a case where structured data has been transformed into an attractive view. But to do a state-by-state comparison, it's better to just read the raw data directly from the structured datafile itself (again, as earlier noted, the site provides a prominent link to a text-display of the data; we're just practicing).
So open up your network panel and reload the page. You don't have to filter the results. But sort the listing by file type:
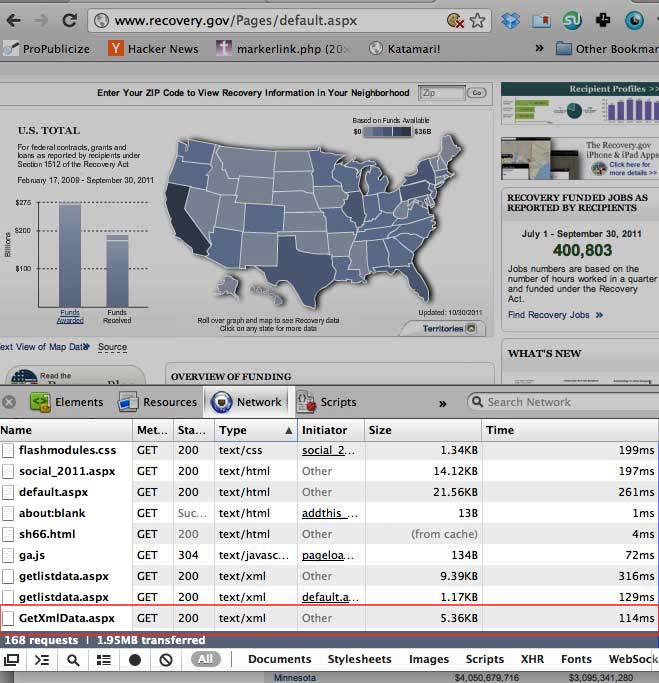
Lo and behold, the file is GetXmlData.aspx and it weighs in less than 6KB
It's easy to narrow down the candidates for the target data file. As I've mentioned before, XML and JSON are the most common data formats, and they are considered text files. When you're trying to find datafiles, it's best to start there first. Another clue will be the file size. Text files are usually pretty small. But if the Flash app contains a lot of data, then adjust your prediction accordingly. In this case, 50 entries of state summary data is not much text at all.
Click on the GetXmlData.aspx entry in your web inspector. You should see the data displayed as XML. You can also visit the actual URL in your browser's address bar and see the same thing:
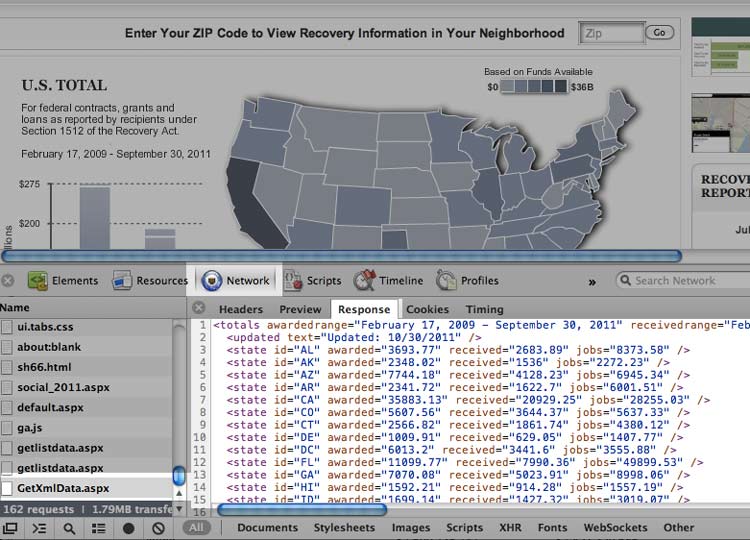
This inspection tactic works for many Flash-based data tables (I cover a real-world example dealing with corporate public data on ProPublica's data blog). However, it will not work in cases in which the data has been embedded directly into the application; in such cases, there is no external data file to catch with the inspector because the Flash app never needs to retrieve an external file.
These cases are rare, however, as data files are usually kept separate from the Flash apps so that non-Flash designers can update the data files without having to muddle with the Flash app source code itself. In cases where the data file is part of the app, it's usually the mark of a bad Flash programmer or a deliberate attempt to keep the data from being easily copied.
Parse the Recovery.gov map data with Ruby
If you're reading this chapter without having gone through the programming section, you can skip this part.
Parsing the Recovery.gov XML file is easy, using methods we've used in the past:
require 'rubygems'
require 'crack'
require 'open-uri'
URL = 'http://www.recovery.gov/pages/GetXmlData.aspx?data=recipientHomeMap'
Crack::XML.parse(open(URL).read)['totals']['state'].each do |state|
puts ['id', 'awarded', 'received', 'jobs'].map{|f| state[f]}.join(', ')
endThe output:
AL, 3693.77, 2683.89, 8373.58 AK, 2348.02, 1536, 2272.23 AZ, 7744.18, 4128.23, 6945.34 AR, 2341.72, 1622.7, 6001.51 CA, 35883.13, 20929.25, 28255.03 CO, 5607.56, 3644.37, 5637.33 CT, 2566.82, 1861.74, 4380.12 #...and so forth
Inspecting the requests
The network panel is not the only way to see a webpage's HTTP requests. The web-crawling chapter provides a working example of how the particulars of a HTTP request can be divined from the raw HTML of a webpage's form.