
In the previous chapter, we saw how to use the web inspector to intercept raw data files. This allows us to read from them directly rather than deal with the data in HTML format.
But there will be many instances when you'll need to parse raw HTML. The Ruby gem Nokogiri makes reading raw HTML as easy as crack-parsed XML and JSON.
Nokogiri
The Nokogiri gem is a fantastic library that serves virtually all of our HTML scraping needs. Once you have it installed, you will likely use it for the remainder of your web-crawling career.
Installing Nokogiri
Unfortunately, it can be a pain to install because it has various other dependences, libxml2 among them, that may or may not have been correctly installed on your system.
Follow the official Nokogiri installation guide here.
Hopefully, this step is as painless as typing gem install nokogiri. If not, start Googling for the error message that you're getting. In a later edition of this book, I'll try to go into more detail on the installation process. But for now, I'm just going to wish you godspeed on this task.
For the remainder of this section, assume that the first two lines of every script are:
require 'rubygems'
require 'nokogiri'
Opening a page with Nokogiri and open-uri
Passing the contents of a webpage to the Nokogiri parser is not much different than opening a regular textfile.
If the webpage is stored as a file on your hard drive, you can pass it in like so:
page = Nokogiri::HTML(open("index.html"))
puts page.class # => Nokogiri::HTML::Document
The Nokogiri::HTML construct takes in the opened file's contents and wraps it in a special Nokogiri data object.
The open-uri module
If the webpage is live on a remote site, like http://en.wikipedia.org/, then you'll want to include the open-uri module, which is part of the standard Ruby distribution but must be explicitly required:
require 'rubygems'
require 'nokogiri'
require 'open-uri'
page = Nokogiri::HTML(open("http://en.wikipedia.org/"))
puts page.class # => Nokogiri::HTML::Document
What open-uri does for us is encapsulate all the work of making a HTTP request into the open method, making the operation as simple as as opening a file on our own hard drive.
Using rest-client
You can also use the RestClient gem as we've done before. All the Nokogiri::HTML constructor needs is raw HTML as a string.
require 'rubygems'
require 'nokogiri'
require 'restclient'
page = Nokogiri::HTML(RestClient.get("http://en.wikipedia.org/"))
puts page.class # => Nokogiri::HTML::Document
Nokogiri and CSS selectors
CSS – Cascading Style Sheets – are how web designers define the look of a group of HTML elements. It has its own syntax but can be mixed in with HTML (the typical use case, though, is to load CSS files externally from the HTML, so that web designers can work on the CSS separately).
Without CSS, this is how you would make all the <a> elements (i.e. the links) the color red on a given webpage:
<p> You can <a color="red" href="http://apple.com">click here</a> to get to Apple's website. Click here to get to <a color="red" href="http://www.microsoft.com">Microsoft</a>. <br> Or you can visit w3.org to <a color="red" href="http://www.w3.org">learn more</a> about the World Wide Web. </p>
This is the resulting effect:
You can click here to get to Apple's website. Click here to get to Microsoft.
Or you can visit w3.org to learn more about the World Wide Web.
The use of CSS allows designers to apply a style across a group of elements, thus eliminating the need to define the styles of every HTML element. This example shows how a CSS selector targets all <a> elements in a single line:
<style>
a:link{ color:red }
</style>
<p>
You can <a href="http://apple.com">click here</a> to get to Apple's website.
Click here to get to <a href="http://www.microsoft.com">Microsoft</a>.
<br>
Or you can visit w3.org to <a href="http://www.w3.org">learn more</a> about the World Wide Web.
</p>
What do style tags have to do with web scraping? Nokogiri's css method allows us to target individual or groups of HTHML methods using CSS selectors. No worries if you're not an expert on CSS. It's enough to recognize the basic syntax.
We'll be working with this simple example webpage. If you view its source, you'll see this markup:
<html>
<head><title>My webpage</title></head>
<body>
<h1>Hello Webpage!</h1>
<div id="references">
<p><a href="http://www.google.com">Click here</a> to go to the search engine Google</p>
<p>Or you can <a href="http://www.bing.com">click here to go</a> to Microsoft Bing.</p>
<p>Don't want to learn Ruby? Then give <a href="http://learnpythonthehardway.org/">Zed Shaw's Learn Python the Hard Way</a> a try</p>
</div>
<div id="funstuff">
<p>Here are some entertaining links:</p>
<ul>
<li><a href="http://youtube.com">YouTube</a></li>
<li><a data-category="news" href="http://reddit.com">Reddit</a></li>
<li><a href="http://kathack.com/">Kathack</a></li>
<li><a data-category="news" href="http://www.nytimes.com">New York Times</a></li>
</ul>
</div>
<p>Thank you for reading my webpage!</p>
</body>
</html>
A table of syntax
Here's a convenient table that shows all the syntax I'll cover in this section. The columns describe:
- The description of the selection and the syntax to do the selection
- A visual depiction of which HTML elements are selected
Assume that this code has been run before each of the syntax calls:
require 'rubygems'
require 'nokogiri'
require 'open-uri'
PAGE_URL = "http://ruby.bastardsbook.com/files/hello-webpage.html"
| Description and Syntax | Selection results |
|---|---|
The <title> element
|
<html>
<head><title>My webpage</title></head>
<body>
<h1>Hello Webpage!</h1>
<div id="references"> |
All <li> elements |
<div id="funstuff">
<p>Here are some entertaining links:</p>
<ul>
<li><a href="http://youtube.com">YouTube</a></li>
<li><a data-category="news" href="http://reddit.com">Reddit</a></li>
<li><a href="http://kathack.com/">Kathack</a></li>
<li><a data-category="news" href="http://www.nytimes.com">New York Times</a></li>
</ul>
</div> |
The text of the first <li> element |
<div id="funstuff">
<p>Here are some entertaining links:</p>
<ul>
<li><a href="http://youtube.com">YouTube</a></li>
<li><a data-category="news" href="http://reddit.com">Reddit</a></li>
<li><a href="http://kathack.com/">Kathack</a></li>
<li><a data-category="news" href="http://www.nytimes.com">New York Times</a></li>
</ul>
</div> |
The url of the second <li> element |
<div id="funstuff">
<p>Here are some entertaining links:</p>
<ul>
<li><a href="http://youtube.com">YouTube</a></li>
<li><a data-category="news" href="http://reddit.com">Reddit</a></li>
<li><a href="http://kathack.com/">Kathack</a></li>
<li><a data-category="news" href="http://www.nytimes.com">New York Times</a></li>
</ul>
</div> |
The <li> elements with a data-category of news
|
<div id="funstuff">
<p>Here are some entertaining links:</p>
<ul>
<li><a href="http://youtube.com">YouTube</a></li>
<li><a data-category="news" href="http://reddit.com">Reddit</a></li>
<li><a href="http://kathack.com/">Kathack</a></li>
<li><a data-category="news" href="http://www.nytimes.com">New York Times</a></li>
</ul>
</div> |
The <div> element with an id of "funstuff"
|
<h1>Hello Webpage!</h1>
<div id="references">
<p><a href="http://www.google.com">Click here</a> to go to the search engine Google</p>
<p>Or you can <a href="http://www.bing.com">click here to go</a> to Microsoft Bing.</p>
<p>Don't want to learn Ruby? Then give <a href="http://learnpythonthehardway.org/">Zed Shaw's Learn Python the Hard Way</a> a try</p>
</div>
<div id="funstuff">
<p>Here are some entertaining links:</p>
<ul>
<li><a href="http://youtube.com">YouTube</a></li>
<li><a data-category="news" href="http://reddit.com">Reddit</a></li>
<li><a href="http://kathack.com/">Kathack</a></li>
<li><a data-category="news" href="http://www.nytimes.com">New York Times</a></li>
</ul>
</div>
|
The <a> elements nested inside the <div> element that has an id of "reference"
|
<h1>Hello Webpage!</h1> <div id="references"> <p><a href="http://www.google.com">Click here</a> to go to the search engine Google</p> <p>Or you can <a href="http://www.bing.com">click here to go</a> to Microsoft Bing.</p> <p>Don't want to learn Ruby? Then give <a href="http://learnpythonthehardway.org/">Zed Shaw's Learn Python the Hard Way</a> a try</p> </div> <div id="funstuff"> <p>Here are some entertaining links:</p> <ul> <li><a href="http://youtube.com">YouTube</a></li> <li><a data-category="news" href="http://reddit.com">Reddit</a></li> <li><a href="http://kathack.com/">Kathack</a></li> <li><a data-category="news" href="http://www.nytimes.com">New York Times</a></li> </ul> </div> |
The rest of this chapter explains the selectors in a little more detail. But feel free to refer back to this table. Knowing the CSS selectors is just a matter of a little memorization
Selecting an element
Simply pass the name of the element you want into the Nokogiri document object's css method:
page = Nokogiri::HTML(open(PAGE_URL))
puts page.css("title")[0].name # => title
puts page.css("title")[0].text # => My webpageThe css method does not return the text of the target element, i.e. "My webpage". It returns an array – more specifically, a Nokogiri data object that is a collectino of Nokogiri::XML::Element objects. These Element objects have a variety of methods, including text, which does return the text contained in the element:
puts page.css("title").text
# => My webpageThe name method simply returns the name of the element, which we already know since we specified it in the css call: "title".
puts page.css("title")[0].name
#=> title Note that even though there is only one title element, the method returns it as an array of one element, so we still need to specify the first element using array notation.
Get an attribute of an element
One of the most common web-scraping tasks is extracting URL's from links, i.e. anchor tags: <a>. The attributes of an element are provided in Hash form:
# set URL to point to where the page exists
page = Nokogiri::HTML(open(PAGE_URL))
links = page.css("a")
puts links.length # => 6
puts links[0].text # => Click here
puts links[0]["href"] # => http://www.google.com
Here's what that first anchor tag looks like in markup form:
<a href="http://www.google.com">Click here</a>
Limiting selectors
You'll often want to limit the scope of what Nokogiri grabs. For example, you may not want all the links on a given page, especially if many of those links are just sidebar navigation links.
Using select for a collection
In some cases, this can be done with combining the Nokogiri parser results with the Enumerable select method.If you noticed in the sample HTML code, there are two anchor tags with class attributes equal to "news". This is how we would use select to grab only those:
page = Nokogiri::HTML(open(PAGE_URL))
news_links = page.css("a").select{|link| link['data-category'] == "news"}
news_links.each{|link| puts link['href'] }
#=> http://reddit.com
#=> http://www.nytimes.com
puts news_links.class #=> Array
Select elements by attributes
So select works. But the ideal solution is to not have Nokogiri's css method pull in unwanted elements in the first place. And that requires a little more knowledge of CSS selectors.
For the above example, we can use CSS selectors to specify attribute values. I won't go into detail here, but suffice to say, it requires a tad more memorization on your part:
news_links = page.css("a[data-category=news]")
news_links.each{|link| puts link['href']}
#=> http://reddit.com
#=> http://www.nytimes.com
puts news_links.class #=> Nokogiri::XML::NodeSet
The last line above demonstrates one advantage of doing the filtering with the css method and CSS selectors rather than Array.select: you don't have to convert the Nokogiri NodeSet object into an Array. Keeping it as a NodeSet allows you to keep doing...well...more NodeSet-specific methods. The following code calls css twice – once to gather the anchor links and then to gather any bolded elements (which use the <strong> tag) that are within those links:
page.css('p').css("a[data-category=news]").css("strong")Again, this will only target <strong> elements within <a> tags that have an attribute data-category set to "news" (whew, that was a mouthful). Any other <strong> elements that aren't children of such anchor tags won't be selected.
The id and class attributes
In our sample HTML, there are two div tags, each with its own id attribute.
The class and id attributes are the most common way of specifying individual and groups of elements. There's nothing inherently special about them, they're just commonly-accepted attributes that web designers use to label HTML elements.
- id
- Only one element on a page should have a given id attribute (though this rule is broken all the time). The CSS selector used to refer to the name of an id is:
#the_id_name_here
- class
- The main difference between id and class is that many elements can have the same class. The CSS selector to select all elements of a given class is:
.the_classname_here
Nested elements
Rather than call css twice, as in this example:
page.css('p').css("a").css("strong")You can refer to nested elements with a single CSS selector:
page.css('p').css("a strong")To specify elements within another element, separate the element names with a space. For example, the following selector would select all image tags that are within anchor tags:
a img
To select all image tags within anchor tags that themselves are within div tags, you would do this:
div a img
In the sample below, I've bolded which elements the above selector would grab:
<p><a href="http://mysite.com">My Site</a></p> <div> <img src="images/picture1.jpg" alt="Image 1"/> <a href="http://images.google.com"><img src="images/picture2.jpg" alt="img 2"/></a> <img src="images/pic5.jpg" alt="img5"> <a href="http://images.yahoo.com"><img src="images/picture9.jpg" alt="img 9"/></a> </div> <a href="http://images.bing.com"><img src="images/picture11.jpg" alt="img 11"/></a>
Exercise: Select nested CSS elements
Referring back to our sample HTML, write a selector that chooses only the anchor tags in the div that has the id of "references". Print out the text within the anchor tag followed by its URL.
Solution
page = Nokogiri::HTML(open(PAGE_URL))
news_links = page.css("div#references a")
news_links.each{|link| puts "#{link.text}\t#{link['href']}"}
Given the sample HTML, my CSS selector could have been div#references p a since all the anchor tags were also within paragraph tags. I could've also done #references a, as there is only element with that particular id.
Xpath selectors
Nokogiri's css method will serve most of your needs. For webpages that require more precise selectors, you can jump into the world of XPath syntax and utilize Nokogiri's xpath method. XPath can handle certain kinds of selections more gracefully than CSS selectors.
I'll add working examples to this section in a later update. XPath is one of those mini-languages that, like regular expressions, are very useful for a specific purpose and can be learned on a need-to-know basis.
W3.org has a thorough reference. w3schools.com has a solid tutorial. JQuery creator John Resig wrote a short comparison of CSS and XPath.
Nokogiri and your web inspector
So how does the web inspector come into play? It makes it easy to find the right CSS selector.
Take a look at sample webpage again. Inspect one of the links.
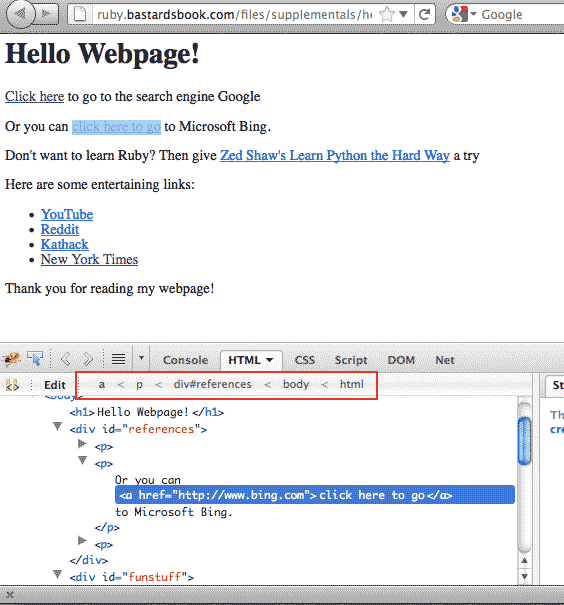
Notice that the CSS selectors that are listed below the the tabs (in Chrome/Safari, it's along the bottom of the panel). In Firebug, you can simply right-click and pick Copy CSS Path, and you have yourself the CSS selector for that link:
html body div#references p a
Exercise: Print out Wikipedia summary labels
Visit the Wikipedia entry for HTML: http://en.wikipedia.org/wiki/HTML
And highlight one of the labels in the top-right summary box, such as "Filename extension".
Use your web inspector to find the CSS selector for all the labels in the summary box. Use Nokogiri to select the elements and print out their text content.
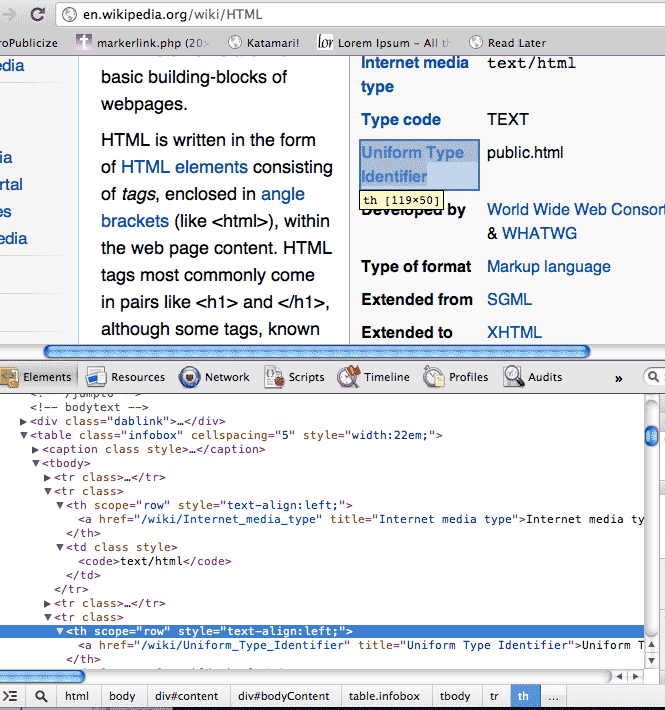
You may find Firebug's inspector to be more useful as it allows you to right-click on the CSS selector listing and copy it to the clipboard directly.
Solution
Using the web inspector, we see that the CSS selector for the category labels is:
html.client-firefox body.mediawiki div#content div#bodyContent table.infobox tbody tr th
However, this is not quite accurate for our needs. With <table> elements, browsers will often insert a <tbody> element around the table content, even if such an element does not exist in the actual source. Also, the ".client-firefox" class most likely appears only when you visit the site with Firefox, which doesn't apply when we retrieve the page using a Ruby script.
In fact, there's usually no reason to include the html or body CSS selectors, as it's a given that most content you want are between those tags.
So, using the CSS selector from the web inspector – but omitting the html, body, and tbody parts of it – we get:
require 'rubygems'
require 'nokogiri'
require 'open-uri'
page = Nokogiri::HTML(open('http://en.wikipedia.org/wiki/HTML'))
page.css('div#content div#bodyContent table.infobox tr th').each do |el|
puts el.text
end
This is the output:
Filename extension Internet media type Type code Uniform Type Identifier Developed by Type of format Extended from Extended to Standard(s)
As easy as it looks
There's not much more to scraping HTML with Nokogiri. The web inspector helps guide you to the right CSS selectors. Nokogiri's css method does the rest of the work. In the next chapter, we see how to put all of what we've learned to scrape real-world websites.