
When winter comes around, I toy with picking up knitting as a hobby. Not because I want to go into the garment industry. I'd just like a warm scarf that matches whatever discount rack jacket I have.
Programming and knitting are both skills that require continual practice but aren't easily improved by doing things other than, well, actually programming or knitting.
If you're reading this part of the book, I'm assuming coding isn't your job already and that you don't have all the free time in the world to tinker for fun. This is why it's important to start thinking about what you want to make or do with code. Programming is not just an intellectual exercise but something that will serve your real-life goals.
Making a "scarf"
The good thing about programming compared to knitting a scarf is that you can experiment and mess up all you want without having to go out and buy more yarn.
So now that you have Ruby installed (hopefully), let's actually execute some code. There are a few reasons for this:
- If you've never coded before, you probably have no idea how code goes from being just text in your text-editor to becoming a program that does something.
- The abstract concepts you'll learn might be easier to get through after you've seen these concepts in action.
- Seeing how an actual program interacts with real-world data might spark ideas for data projects of your own.
Note that I said "execute" – not "write" – code. I recommend typing the code out manually, rather than just cut-and-paste. Even as an experienced coder, I'll do that to slow down and better understand someone else's code. But you're allowed to just copy-and-paste into your text-editor and run it, because we're just learning how to execute code for now.
Learning to execute code for the first time is a big deal. In lower-level languages, there's some work in setting up the environment and running compiler commands before executing a script. In Ruby and other higher-level languages, assuming you got past the installation stage, all you have to do is type some code into a text file:
puts "Hello world, again"And hit Run/Go, and it...just goes.
Virtually all the code snippets in this chapter can be copy-and-pasted from the page and executed in this fashion. Feel free to experiment and alter them if you, for example, want to download tweets from Twitter user of your choice. If you run into errors, you can just copy-and-paste the original code.
Most importantly: DON'T PANIC
First: These code snippets may look like a lot of work. But I've written them out as verbosely as possible and broken out steps that an average coder would combine into a single line. But I'm trying to spell out as much out as possible so that even if you know nothing about programming, you can see the effects of each step. As you get better at coding, you'll be able to write equivalent code in much, much fewer lines.
So the bottom line is: I don't expect you to know even the basics of programming. Therefore, I don't expect you to understand any of the details of how these code snippets work. Just cut-and-paste and follow along. And when you get bored, you can move onto the actual explanatory lessons
By the end of this chapter, hopefully you'll get a sense of what it takes to make something useful. And hopefully it'll seem like less work than you had imagined, which, from my experience, is not the case with knitting.
What this code does
Our "scarf" will be a set of scripts to fetch tweets from Twitter and analyze their content. This doesn't require you to have a Twitter account, but I'm assuming you are at least aware of the microblogging service and how it lets users broadcast 140-character-long messages across the entire Internet commons.
This won't be the most efficient or beautiful code but it will do the job. And it touches on almost all of the fundamentals covered in this book.
Before we get to the actual Twitter-copying we will practice batch downloading from Wikipedia. Downloading tweets from Twitter works just about the same as downloading from any other website.
Here's the high-level overview of what this chapter's scripts do:
- Download a single page from Wikipedia and save it as a file
- Download multiple pages from Wikipedia and save them as files
- Download a hundred tweets belonging to a single Twitter user and save them as a single file
- Download a thousand tweets belonging to a single Twitter user and save them to files
- Parse the downloaded tweet files to calculate the frequency of a user's tweeting.
- Parse the downloaded tweet files to find out the user's rate of interacting with other users.
- Parse the downloaded tweet files and analyze basic language characteristics, such as most frequently used words.
Setup your workspace
We covered all of this in the Installation chapter, so this section is just to refresh your memory.
-
Make a new folder or directory anywhere convenient on your computer. In the picture below, I'm making a folder called "rubytest"
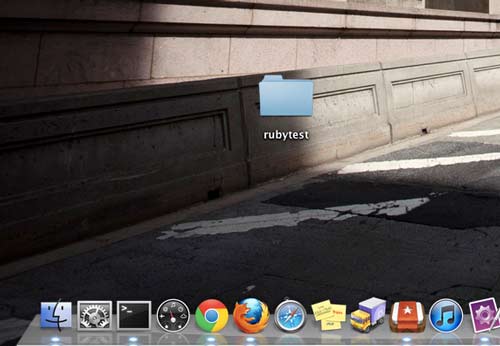
-
Open up your text editor to a blank file. Type in some code:
puts "Hello world again"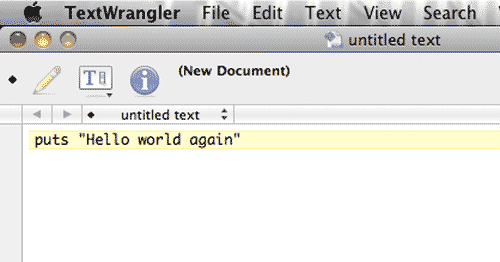
-
Save the file with whatever name you want into the folder you created in Step 1. But make its extension be: .rb
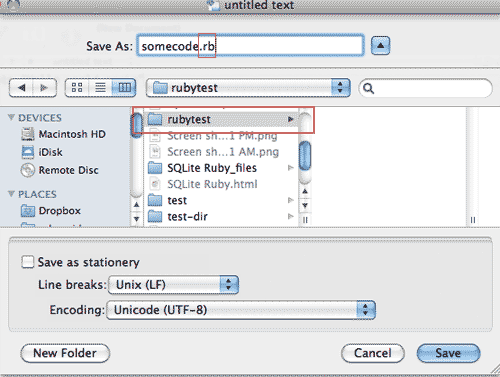
-
Now run the code. This varies depending on which text editor you're using (refer to the appropriate section in the Installation). You should see the output of your code in a new window/panel:
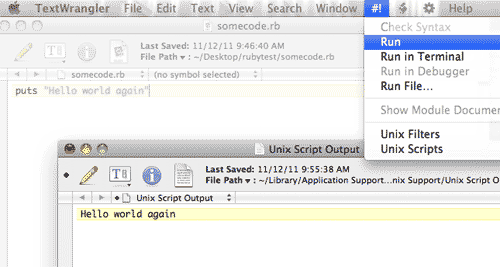
For the remainder of this lesson, you can just copy-and-paste code into this file and run it. Or you can make new files to hold each script if you want.
-
Run some code that saves a file. There are some scripts in this chapter that will save new files. They will save them relative to where your .rb file is.
Test this out by running the following code:
open("hello-world.txt", 'w')You should see a new file called "hello-world.txt" in the same directory as where you saved that script file:
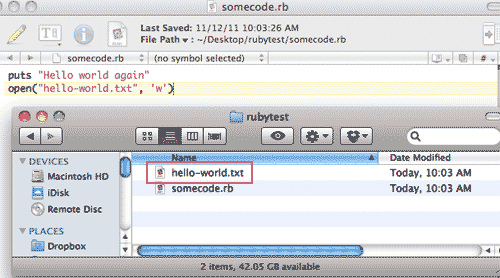
If you got through the above steps, you're good to go for this chapter. Well, you'll also need to be connected to the Internet as we'll be downloading pages from there.
Downloading Wikipedia pages
This collaborative encyclopedia is a great place to practice scraping. For one, it's a very robust site that can handle a reasonable number of requests. Two, its information is free to the world. And three, despite the best efforts of its volunteers, much of its information could be better organized for data analysis.
For our purposes, we will just walk through code that downloads the pages as files. In later chapters of this book, we'll see how to parse and make use of Wikipedia's vast information.
Download a page
Let's start off with something easy. The following two lines of code will download the Wikipedia page for Ada Lovelace and print the contents to your screen:
require "open-uri"
puts open("http://en.wikipedia.org/wiki/Ada_Lovelace").readIf you run the above snippet, you should get output that looks like:
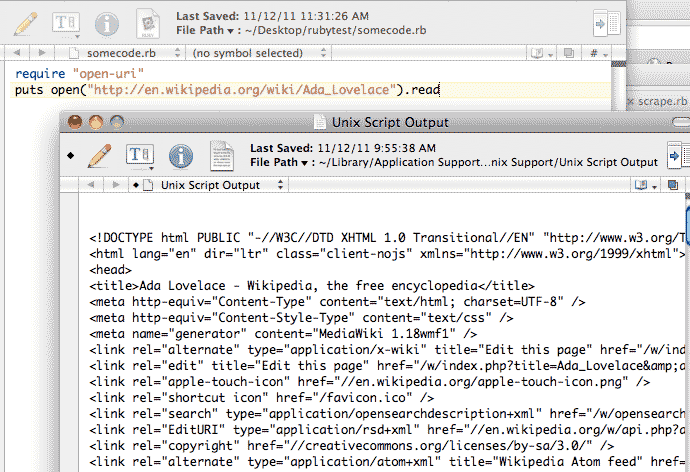
That's just the raw HTML behind the webpage at http://en.wikipedia.org/wiki/Ada_Lovelace. You can visit the link in your browser, which does the work of rendering that raw HTML code into something readable:
Strings
Let's modify that code snippet so that it will now download from the New York Times homepage:
require "open-uri"
puts open("http://www.nytimes.com").readIf you run it, you'll get raw HTML again, except from the New York Times. Can you tell what changed in the code?
require "open-uri"
puts open("http://en.wikipedia.org/wiki/Ada_Lovelace").read
require "open-uri"
puts open("http://www.nytimes.com").read
The text inside the quotation marks are of course, the URL (the addresses) for the Wikipedia and New York Times's websites.
Those quotation marks are vital; if you remove them, your program will throw an error, because it can't tell whether that text is Ruby code or something else. Keep the quote marks in, however, and the Ruby interpreter will know that the text inside is meant to be just normal text.
This Ruby object – text inside of quotation marks – is called a String. All you need to know for now is that if you alter the code examples, make sure the quotation marks are in the right place.
Variables and methods
Try out this code; it won't download anything, it'll just print something to screen:
x = "http://en.wikipedia.org/wiki"
y = "Ada_Lovelace"
z = x + "/" + y
puts x
puts y
puts z
The output should look like this:
http://en.wikipedia.org/wiki Ada_Lovelace http://en.wikipedia.org/wiki/Ada_Lovelace
This is a simple demonstration of variables. We assigned the strings "http://en.wikipedia.org/wiki" and "Ada_Lovelace" to the variables x and y, respectively. The variable z was assigned the result of combining x, a forward slash "/" and y together.
Here's a table of the assignments:
| x | "http://en.wikipedia.org/wiki" |
| y | "Ada_Lovelace" |
| z |
"http://en.wikipedia.org/wiki" + "/" + "Ada_Lovelace"
In other words: x + "/" + y |
Note how the variables x, y, and z do not have quotes. This is because they aren't meant to be evaluated as just normal letters – i.e. strings. Instead, think of them as nicknames for the strings they are assigned to. You can also think of them as pointers: x and y point to the strings "http://en.wikipedia.org/wiki" and "Ada_Lovelace"
Variable naming
You can use any combination of lower case letters and underscores for variable names, as long as they don't conflict with (the very few) special reserved Ruby words, such as do and if.
For the remainder of the chapter, instead of x, y, and z, I'll use variables with more descriptive names:
remote_base_url = "http://en.wikipedia.org/wiki"
remote_page_name = "Ada_Lovelace"
remote_full_url = remote_base_url + "/" + remote_page_nameIt makes no difference to the Ruby interpreter. But it impacts us humans in that it's harder to type but easier to read when writing longer sections of code.
The method puts
In fact, that word puts is also a pointer. But it has been preassigned to what's called a method – a block of code that does something. In this case, that "something" is printing to your screen. The fact that puts does this is something you would only know through experience, or reading the documentation.
Fetch a page from Wikipedia using variables
Let's rewrite the introductory webpage-downloading program with variables. It will end up doing the same thing as before, except with more lines of code:
require "open-uri"
remote_base_url = "http://en.wikipedia.org/wiki"
remote_page_name = "Ada_Lovelace"
remote_full_url = remote_base_url + "/" + remote_page_name
puts open(remote_full_url).read
First thing to note: the words open and read are also methods which respectively access a file on the Internet (in this case, a webpage) and reads its contents.
The only change from our first simple program is that instead of passing the entire URL as a string to the open method, as before:
open("http://en.wikipedia.org/wiki/Ada_Lovelace")– we now pass it the variable that points to that string
open(remote_full_url)Now experiment a little. Use the same code that we just executed. But modify it so that it downloads from the Wikipedia entry for Ruby.
Hint: You only need to change one string.
Here it is:
require "open-uri"
remote_base_url = "http://en.wikipedia.org/wiki"
remote_page_name = "Ruby"
remote_full_url = remote_base_url + "/" + remote_page_name
puts open(remote_full_url).read
Right now it seems like we've just added more code to no effect. But you'll see that it is necessary to break up longer values, such as URLs, so that you can modify just parts of them. Hence, the use of variables.
Writing and reading to files
So our little script so far can download a page from Wikipedia. But it hasn't been that helpful in that it prints raw HTML to the screen. Here's how to modify it so that it saves the webpage to your hard drive:
require "open-uri"
remote_base_url = "http://en.wikipedia.org/wiki"
remote_page_name = "Ada_Lovelace"
remote_full_url = remote_base_url + "/" + remote_page_name
remote_data = open(remote_full_url).read
my_local_file = open("my-downloaded-page.html", "w")
my_local_file.write(remote_data)
my_local_file.close
First, you should notice that nothing shows up in your output window. That's because I took out the call to the puts method. However, check your working folder. You should see a file named "my-downloaded-page.html".
If you open it in your browser, it will look like a broken webpage. This is because it refers to images and other files that are not on your computer (but are on wikipedia.org's servers). If you open it up in your text-editor (right-click » "Open with..."), you will see the raw HTML output as we did when we printed it to screen.
Even more variables
You may have also noticed that we added a couple more variables to the mix. Below, I modify the code to add a few more variables without changing the effect of the script. And I'll add a puts so that the output screen isn't just blank:
require "open-uri"
remote_base_url = "http://en.wikipedia.org/wiki"
remote_page_name = "Ada_Lovelace"
remote_full_url = remote_base_url + "/" + remote_page_name
puts "Downloading from: " + remote_full_url
remote_data = open(remote_full_url).read
my_local_filename = "my_copy_of-" + remote_page_name + ".html"
puts "Writing to: " + my_local_filename
my_local_file = open(my_local_filename, "w")
my_local_file.write(remote_data)
my_local_file.close
The result of this script should be a new file named "my_copy_of-Ada_Lovelace.html". And your output screen should have:
Downloading from http://en.wikipedia.org/wiki/Ada_Lovelace Writing to: my_copy_of-Ada_Lovelace.html
Are you starting to see the effect of using variables? If we hadn't used variables for the webpage and filenames, the program would've looked like this:
require "open-uri"
puts "Downloading from: http://en.wikipedia.org/wiki/Ada_Lovelace"
remote_data = open("http://en.wikipedia.org/wiki/Ada_Lovelace").read
puts "Writing to: my_copy_of-Ada_Lovelace.html"
my_local_file = open("my_copy_of-Ada_Lovelace.html", "w")
my_local_file.write(remote_data)
my_local_file.close
Sure, the code is now shorter. But look at how many times we had to repeat the components of the filename, particularly "Ada_Lovelace".
Size isn't everything. One of the main reasons to use code is to reduce repetition Another main reason is that code can do thousands of actions in a single second. The use of variables to reduce repetition and, consequently, increase reusable code, is absolutely necessary – unless you want to type the code for those thousands of actions.
Whitespace
OK, let's run a variation of that script:
require "open-uri"
remote_base_url = "http://en.wikipedia.org/wiki"
remote_page_name = "Dennis_Ritchie"
remote_full_url = remote_base_url + "/" + remote_page_name
somedata = open(remote_full_url).read
my_local_filename = "my_copy_of-" + remote_page_name + ".html"
my_local_file = open(my_local_filename, "w")
my_local_file.write(somedata)
my_local_file.close
In your working directory, you should now see a file called: my_copy_of-Dennis_Ritchie.html
What changed? Not much. We only changed the value of remote_page_name, which then affected every other variable that depended on it, such as remote_full_url and my_local_filename. Hence, why we have a new file based off of Dennis Ritchie rather than Ada Lovelace.
I also changed the name of the variable remote_data (didn't like seeing "remote" so many times) to somedata. It didn't affect the program's overall output, except that I had to change any instance in which I used remote_data to somedata.
Finally, I also added some line breaks and a tab character. This doesn't impact anything about the program's execution. I only wanted to demonstrate that extra whitespace in Ruby code, such as two or more consecutive line breaks, has no effect. The upshot is that you can space out your code if it helps you read it better.
Read from files
The following code reads another page from Wikipedia, saves it to disk, reopens that saved file, and prints its contents to your screen.
require "open-uri"
remote_base_url = "http://en.wikipedia.org/wiki"
remote_page_name = "Steve_Wozniak"
remote_full_url = remote_base_url + "/" + remote_page_name
somedata = open(remote_full_url).read
my_local_filename = "my_copy_of-" + remote_page_name + ".html"
my_local_file = open(my_local_filename, "w")
my_local_file.write(somedata)
my_local_file.close
file_for_reading = open(my_local_filename, "r")
puts file_for_reading.read
file_for_reading.close
The open method
By now you should've noticed that we're using the same word – open – to refer to three seemingly different methods:
- somedata = open(remote_full_url) This retrieves a webpage from the Internet address in remote_full_url
- open(my_local_filename, "w") This opens a file – a file on your hard drive with a filename that is equal to the variable my_local_filename – for writing into.
- open(my_local_filename, "r") Same as above, but the file is now opened for reading, not writing.
The latter two methods are easier to explain. We've given both method calls each a second string (the values passed to a method are called arguments) – either a "r" or "w". These set the kind of open operation: either the file is being opened to read from or to be written into.
The use of open with remote_full_url actually uses the open method supplied by the OpenURI library. The OpenURI library is not included for use by default, so that's why the first line of our programs so far has been:
require "open-uri"
How Ruby chooses between the open for local files and the open for Internet addresses is a subject for future study. The only thing you need to know now, as a beginner, is that without the require "open-uri", you won't be able to use open for Internet addresses, such as "http://wikipedia.org"
Note: By default, the open method goes into read mode. This is why we don't bother supplying "r" in the line:
somedata = open(remote_full_url).read
And one more thing: If you try to open a filename – for writing – that doesn't yet exist, open will create an empty file of that name.
However, if you try to read from a non-existent file, Ruby will throw an error.
Read and write, twice-over
This script will:
- Read two different webpages
- Write both to your hard drive
- Reopen those saved files
- Write the combined contents of those files into a third file
require "open-uri"
remote_base_url = "http://en.wikipedia.org/wiki"
r1 = "Steve_Wozniak"
r2 = "Steve_Jobs"
f1 = "my_copy_of-" + r1 + ".html"
f2 = "my_copy_of-" + r2 + ".html"
# read the first url
remote_full_url = remote_base_url + "/" + r1
rpage = open(remote_full_url).read
# write the first file to disk
file = open(f1, "w")
file.write(rpage)
file.close
# read the second url
remote_full_url = remote_base_url + "/" + r2
rpage = open(remote_full_url).read
# write the second file to disk
file = open(f2, "w")
file.write(rpage)
file.close
# open a new file:
compiled_file = open("apple-guys.html", "w")
# reopen the first and second files again
k1 = open(f1, "r")
k2 = open(f2, "r")
compiled_file.write(k1.read)
compiled_file.write(k2.read)
k1.close
k2.close
compiled_file.close
You should now have a file in your working directory called apple-guys.html. This file should contain the combined contents of the local files my_copy_of-Steve_Jobs.html and my_copy_of-Steve_Wozniak.html
We didn't use any new methods or techniques to combine the two files. Just different variable names that I chose at my pleasure. Note how I reuse the variable file twice:
- To open, write to, and close a file with the name pointed to by f1
- To open, write to, and close a file with the name pointed to by f2
This is totally kosher. However, by reassigning file to file = open(f2, "w"), we lose the pointer to the first file. So when reassigning variables, be sure you're done with whatever data it once pointed to.
Comments with #
What's with the pound signs? To comment (i.e. annotate) Ruby code, add a # to a line. Every character after the # is ignored by the interpreter. This is how programmers doucment their code
# this code prints "hello world"
puts "hello world"Collections and Loops
This section includes concepts covered in the chapters for collections and loops, two concepts which make programming very powerful for accomplishing repetitive (and tedious) tasks.
In the last section, we compiled downloaded two webpages and compiled them into one file. But we essentially wrote out the code for this operation twice over. That's really not any faster than visiting those two pages in our web browser and doing Select All » Copy-Paste by hand.
First, let's do a simple introduction to loops and collections:
Counting from 1 to 10
Here's a simple collection:
1..10It's a collection of the numbers from 1 through 10; in Ruby, this data object is known as a Range.
All collections, including ranges, have a method called each.
When we use a single dot operator (.), we signify that the method each belongs to a particular collection
This is how we use each with the range 1..10:
(1..10).each do |a_number|
puts a_number
endRunning that code should get you this:
1 2 3 4 5 6 7 8 9 10
Combining strings and numbers
We've seen how to add strings together with + (the technical term is concatenate). But this is the first time we've really dealt with numbers (See? You don't have to be a math genius to program). Numbers can be added together as you've done in arithmetic class:
1 + 8
#=> 9
50 * 50 + (100/2) * 42
#=> 4600
However, strings and numbers cannot be added together. They are two different data types, as far as Ruby is concerned. The following code will throw an error:
puts( 10 + "42")
The "42" may look like a number to us humans. But again, Ruby considers anything surrounded by quotation marks as a string. So "42" has more in common with "forty-two" than with 42.
However, we can use the to_s method to convert the number into a string:
puts( 10.to_s + "42")
The answer (remember, you're adding two strings together):
1042
Back to our file operations, try:
remote_base_url = "http://en.wikipedia.org/wiki"
(1..3).each do |some_number|
r_url = remote_base_url + "/" + some_number.to_s
puts r_url
end
The result:
http://en.wikipedia.org/wiki/1 http://en.wikipedia.org/wiki/2 http://en.wikipedia.org/wiki/3
All together now
Visit one of the URLs generated from our numerical loop, such as http://en.wikipedia.org/wiki/1. It's the Wikipedia entry for Year 1.
Try to see if you can write the following program based on what you've learned so far:
- Specify two numbers, representing a start and end year
- Use that range to create a loop
- Retrieve the Wikipedia entry that corresponds to each iteration of the loop
- Save that Wikipedia page to a corresponding file on your hard drive
- In a second loop, combine all those year entries into one file, with the name of "start_year-end_year.html"
This consists of nothing more than a combination of previously written code.
TextWrangler's Run in Terminal
In TextWrangler – and this may apply to other text editors – the output of the following program won't appear until everything is finished. In the previous code snippet, you'll have a long period of no feedback, even though there is a puts command to output after each loop iteration.
To see the output from the puts commands in real time, choose Run in Terminal as opposed to just Run:
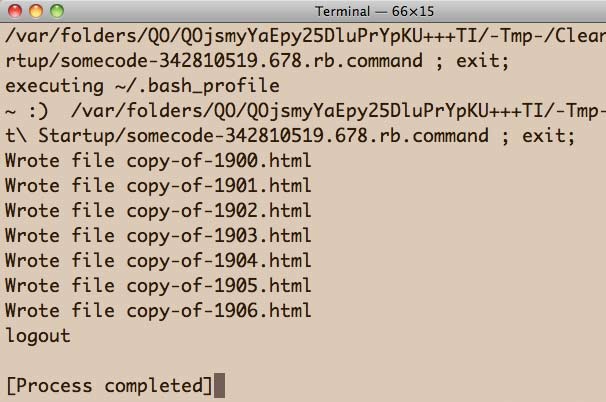
require "open-uri"
remote_base_url = "http://en.wikipedia.org/wiki"
start_year = 1900
end_year = 1906
(start_year..end_year).each do |yr|
rpage = open(remote_base_url + "/" + yr.to_s)
local_fname = "copy-of-" + yr.to_s + ".html"
local_file = open(local_fname, "w")
local_file.write(rpage.read)
local_file.close
# Optional output line:
puts "Wrote file " + local_fname
sleep 1
end
# Write to the compiled file now:
compiled_file = open(start_year.to_s + "-" + end_year.to_s + ".html", "w")
(start_year..end_year).each do |yr|
local_fname = "copy-of-" + yr.to_s + ".html"
local_file = open(local_fname, "r")
compiled_file.write(local_file.read)
local_file.close
end
compiled_file.close
If you copied and ran the above code exactly as is, you should have files for years 1900 to 1906, and a file named 1900-1906.html that is a combination of all those files:
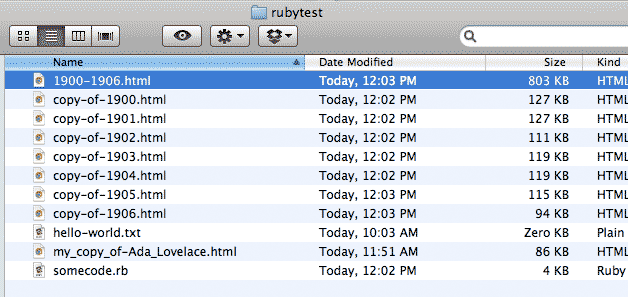
Here's an additional challenge: write the above program using just one each loop.
Ask yourself: why not perform the actions in the second loop inside of the first loop?
require "open-uri"
remote_base_url = "http://en.wikipedia.org/wiki"
start_year = 1900
end_year = 1906
compiled_file = open(start_year.to_s + "-" + end_year.to_s + ".html", "w")
(start_year..end_year).each do |yr|
rpage = open(remote_base_url + "/" + yr.to_s)
rpage_data = rpage.read
compiled_file.write(rpage_data)
local_fname = "copy-of-" + yr.to_s + ".html"
local_file = open(local_fname, "w")
local_file.write(rpage_data)
local_file.close
puts "Wrote file " + local_fname
sleep 1
end
compiled_file.close
There's one subtlety here that you wouldn't know about before studying the chapter on file reading/writing. I declare a new variable in this one-loop version:
rpage = open(remote_base_url + "/" + yr.to_s)
rpage_data = rpage.read
...
compiled_file.write(rpage_data)
local_file.write(rpage_data)
Previously, the equivalent code was:
rpage = open(remote_base_url + "/" + yr.to_s)
...
local_file.write(rpage.read)
For reasons that won't be clear until the chapter on file reading/writing, you can't call the read method twice on the same File object (in this example, rpage).
However, we can take the output of read – a string of all the raw HTML – and assign it to a different variable. We can access that variable – rpage_data – as many times as we like.
Bonus: Each time you invoke a method, it returns some kind of value. As I mentioned above, rpage.read returns a String. But what is rpage itself? It is the result of this operation:
rpage = open(remote_base_url + "/" + yr.to_s)
rpage_data = rpage.read
This can all be done in one line:
rpage_data = open(remote_base_url + "/" + yr.to_s).readTake a crack at redoing the one-loop downloader with that change. It should be just a copy-and-paste job with a slight alteration:
require "open-uri"
remote_base_url = "http://en.wikipedia.org/wiki"
start_year = 1900
end_year = 1906
compiled_file = open(start_year.to_s + "-" + end_year.to_s + ".html", "w")
(start_year..end_year).each do |yr|
rpage_data = open(remote_base_url + "/" + yr.to_s).read
compiled_file.write(rpage_data)
local_fname = "copy-of-" + yr.to_s + ".html"
puts local_fname
local_file = open(local_fname, "w")
local_file.write(rpage_data)
local_file.close
sleep 1
end
compiled_file.close
What you've learned so far
Whether you understood anything or not, by running through this Wikipedia-scraping script, step-by-step, you've covered most of practical concepts in most of the fundamentals section of this book, including:
Not bad. So don't be frustrated if none of this made sense – you just ran through the lessons covered in a first semester computer science course. It's not supposed to make sense in 15 minutes.
The point of this exercise is just to go through the motions so that when you actually read through the lessons, you have an idea of what you're aiming at.
Tweet Fetching
In this part of the lesson, we fetch and parse the tweets from a selected Twitter user's account. We take advantage of Twitter's application programming interface, or API. We will cover APIs in more detail in a later chapter. For now, think of the Twitter API, for our intents and purposes, as responding the same way as Wikipedia does when we download pages from it.
A small warning: The code snippets will be a bit larger with more moving parts from here on out. It's really no more complicated than before, but it may look like it.
The Twitter API
The main difference between downloading from twitter.com versus wikipedia.org is the URL. You can refer to the Twitter API docs for GET statuses/user_timeline for details on how things work on Twitter's end, but the main gist is that your program needs to point to this URL:
http://api.twitter.com/1/statuses/user_timeline.xml?count=100&screen_name=SOMEUSERNAME
Like the Wikipedia pages we downloaded in the previous section, you can visit a user's tweets listing in your web browser. Here are 100 of the latest tweets for user USAGov:
http://api.twitter.com/1/statuses/user_timeline.xml?screen_name=USAGov
You'll see that what you get is not a webpage, though, but raw XML:

We'll learn later how to parse that out for the useful bits of information. For now, let's just fetch the data and save it to our hard drive.
Starting from the code we've already written, try on your own to write a program that downloads and saves one page of a specific user's tweets.
require "open-uri"
remote_base_url = "http://api.twitter.com/1/statuses/user_timeline.xml?count=100&screen_name="
twitter_user = "USAGov"
remote_full_url = remote_base_url + twitter_user
tweets = open(remote_full_url).read
my_local_filename = twitter_user + "-tweets.xml"
my_local_file = open(my_local_filename, "w")
my_local_file.write(tweets)
my_local_file.close
When Twitter fails
Even if your code is totally correct, the Twitter service may respond with error messages. Most of the time, it's because you're making requests too often or during a time when the service is overloaded.
Rather then wait for it to come back up, you can direct your scripts to download archived tweets from this book's site. The base URL is:
http://ruby.bastardsbook.com/files/tweet-fetcher/tweets-data/USAGov-tweets-page-[PAGENUM].xml
The data come exactly as they did from the Twitter API. You just need to increment the page number (up to 10) variable to read from the archive pages:
http://ruby.bastardsbook.com/files/tweet-fetcher/tweets-data/USAGov-tweets-page-1.xml http://ruby.bastardsbook.com/files/tweet-fetcher/tweets-data/USAGov-tweets-page-2.xml
Download multiple pages of tweets
Again, this is no different than when we were downloading from Wikipedia, it's just a change of address. Inside the loop, I've thrown in a sleep 5 command – which pauses the program for 5 seconds – in the hopes that Twitter won't choke from quick, multiple requests.
Start from the code in our previous script that looped through multiple Wikipedia pages.
require "open-uri"
remote_base_url = "http://api.twitter.com/1/statuses/user_timeline.xml?count=100&screen_name="
twitter_user = "USAGov"
remote_full_url = remote_base_url + twitter_user
first_page = 1
last_page = 5
(first_page..last_page).each do |page_num|
puts "Downloading page: " + page_num.to_s
tweets = open(remote_base_url + twitter_user + "&page=" + page_num.to_s).read
my_local_filename = twitter_user + "-tweets-page-" + page_num.to_s + ".xml"
my_local_file = open(my_local_filename, "w")
my_local_file.write(tweets)
my_local_file.close
sleep 5
end
Parsing the Tweets
So far, we've used code to only do the kind of batch downloading that can more or less be done with downloader-plugins, such as DownloadThemAll!, or other simple-click-to-use services. The main advantage of learning how to program a batch downloader yourself is that once you get the hang of it, you can batch download just about any site with the same code with trivial modifications.
The following section demonstrates a few simple ways that we can leverage code to do custom analyses of datasets (in this case, tweets), which is the kind of functionality for which you won't easily find ready-to-use services.
The main concepts we'll be introduced to are the Array and Hash collections. These are harder to play around while being totally new to programming. So don't feel down if you run into seemingly inexplicable errors. As before, you can just go through the motions by copying my sample code as is. Or you can just move on to the formal programming chapters.
Installing the crack gem
This next step requires you to go to your command prompt – which you learned about in the installation chapter – to install a RubyGem, Ruby's way of packaging and distributing code libraries. I go into more detail in the chapter on methods and gems.
But hopefully, it's as easy as going to the command prompt and typing in:
gem install crack
Parsing XML with crack
The crack gem is just a helpful library that makes it easy to programmatically read the XML format that the tweets data comes as.
I'm assuming you know next-to-nothing about XML or how to parse it, so I'll keep the examples easy.
Here's a very simple XML document:
<?xml version="1.0" encoding="UTF-8"?>
<person>Tim Berners-Lee</person>
First: Don't worry about the first line (the <?xml...); it's just a standard header that indicates the type of XML document this is.
The XML contains just a single "person" – Tim Berners-Lee – which is bounded by opening and closing tags, <person> and <person>, respectively. Note that a closing tag has a backslash / in it.
Here's the Ruby code to read that XML. The XML content is a string (assigned to the variable xml). Also, note the two necessary require statements:
require "rubygems"
require "crack"
xml = '
<?xml version="1.0" encoding="UTF-8"?>
<person>Tim Berners-Lee</person>
'
parsed_xml = Crack::XML.parse(xml)
puts parsed_xml['person']
The output is:
Tim Berners-Lee
Nested XML
Here's a barely more complicated XML document. There are elements nested inside another element:
<?xml version="1.0" encoding="UTF-8"?>
<person>
<first_name>Tim</first_name>
<last_name>Berners-Lee</last_name>
</person>
Again, using crack to parse it:
require "rubygems"
require "crack"
xml = '
<?xml version="1.0" encoding="UTF-8"?>
<person>
<first_name>Tim</first_name>
<last_name>Berners-Lee</last_name>
</person>
'
parsed_xml = Crack::XML.parse(xml)
puts parsed_xml['person']
puts parsed_xml['person']['first_name']
puts parsed_xml['person']['last_name']
The output:
last_nameBerners-Leefirst_nameTim Tim Berners-Lee
Why does that first line of output look so messy? There isn't a defined way to convert this XML structure into text. So Crack::XML.parse just concatenates all the tags and their enclosed values together. To read each nested element specifically, we just chain together the bracket-and-string notation – e.g. ['person']['first_name'] – from the previous example.
Introduction to the Hash
What crack does so nicely for us is convert XML content into the data structure known as a Hash, which is a type of collection. So this:
<?xml version="1.0" encoding="UTF-8"?>
<person>
<first_name>Tim</first_name>
<last_name>Berners-Lee</last_name>
</person>
Becomes this:
{"person"=> {
"last_name"=>"Berners-Lee", "first_name"=>"Tim"}
}
I cover this in detail in the collections chapter. You just need to be acquainted with how to access values from the Hash data structure:
data = {"person"=> {"last_name"=>"Berners-Lee", "first_name"=>"Tim"} }
puts data["person"]["last_name"]
#=> Berners-Lee
Introduction to the Array
The crack gem, when parsing XML, also produces the Ruby collection-type known as the Array. Let's look at a more complicated XML document:
<?xml version="1.0" encoding="UTF-8"?>
<people>
<person>
<first_name>Tim</first_name>
<last_name>Berners-Lee</last_name>
</person>
<person>
<first_name>Robert</first_name>
<last_name>Cailliau</last_name>
</person>
</people>
Besides the new <people> tag and another level of nesting, do you see what the major structural difference is? There are two elements with the person tag. How do we specify one from the other?
Let's try to parse it out as we did in the previous example:
require "rubygems"
require "crack"
require "pp"
xml = '
<?xml version="1.0" encoding="UTF-8"?>
<people>
<person>
<first_name>Tim</first_name>
<last_name>Berners-Lee</last_name>
</person>
<person>
<first_name>Robert</first_name>
<last_name>Cailliau</last_name>
</person>
</people>
'
parsed_xml = Crack::XML.parse(xml)
puts parsed_xml['people']['person']['first_name']
Ruby will throw an error at that last line because there are multiple <person> tags. The structure for handling tags of the same name at the same level is not a hash, but an array.
Replace the final line of the previous code with:
puts parsed_xml['people']['person'][0]['first_name']
puts parsed_xml['people']['person'][1]['first_name']
The output should be the first_name elements of the first and second person elements, represented by the indices of 0 and 1, respectively:
Tim Robert
Parse user info from the tweets data
Here's some code to open one of the previously downloaded tweet files, parse the XML, and print out:
- The user's Twitter name
- The user's real name
- The user's account creation date
- The user's total tweet count
- The date of the first tweet in the file
- The text of the first tweet in the file
Note: You'll have to change the tweet_filename variable to point to whatever you named one of your own downloaded tweet files:
require "rubygems"
require "crack"
tweet_filename = "USAGov-tweets-page-1.xml"
tweets_file = File.open(tweet_filename)
parsed_xml = Crack::XML.parse( tweets_file.read )
tweets_file.close
tweets = parsed_xml["statuses"]
first_tweet = tweets[0]
user = first_tweet["user"]
puts user["screen_name"]
puts user["name"]
puts user["created_at"]
puts user["statuses_count"]
puts first_tweet["created_at"]
puts first_tweet["text"]
You should see output similar to this format:
USAgov USA.gov Mon Mar 03 21:06:45 +0000 2008 1560 Sun Oct 23 18:01:06 +0000 2011 Celebrate Pink Ribbon Sunday to raise awareness about breast cancer. Learn how you can participate at http://t.co/5dgvtnOh
In your text editor, Open up any one of the tweet files you've downloaded and examine the XML.
The general structure goes like this:
<?xml version="1.0" encoding="UTF-8"?>
<statuses type="array">
<status>
<user>
fields for username, id, profile pic, date started, etc
</user>
fields for content of the tweet, date, number of times retweeted, etc.
</status>
<status>
<user></user>
</status>
<status>
<user></user>
</status>
etc...
</statuses>
The XML consists of:
- An overarching <statuses> element
- <statuses> contains a set of <status> elements
- Each <status> contains the metadata and content of a single tweet.
- Also inside each <status> is a <user> element
- Each <user> contains a set of elements with the user's information. The <user> is the same in every <status> element (i.e tweet)
Here's the XML for a single tweet:
<status>
<created_at>Sun Mar 20 17:22:56 +0000 2011</created_at>
<id>49521314461007872</id>
<text>Spring is here! Today marks the Vernal Equinox, the official start of the spring season.</text>
<source><a href="http://app.measuredvoice.com/" rel="nofollow">Measured Voice</a></source>
<truncated>false</truncated>
<favorited>false</favorited>
<in_reply_to_status_id></in_reply_to_status_id>
<in_reply_to_user_id></in_reply_to_user_id>
<in_reply_to_screen_name></in_reply_to_screen_name>
<retweet_count>38</retweet_count>
<retweeted>false</retweeted>
<user>
<id>14074515</id>
<name>USA.gov</name>
<screen_name>USAgov</screen_name>
<location>Washington, DC</location>
<description>Follow us to stay up to date on the latest official government news and information.</description>
<profile_image_url>http://a0.twimg.com/profile_images/1155238675/usagov_normal.jpg</profile_image_url>
<profile_image_url_https>https://si0.twimg.com/profile_images/1155238675/usagov_normal.jpg</profile_image_url_https>
<url>http://USA.gov</url>
<protected>false</protected>
<followers_count>70372</followers_count>
<profile_background_color>f7f7f7</profile_background_color>
<profile_text_color>6c6c6c</profile_text_color>
<profile_link_color>022945</profile_link_color>
<profile_sidebar_fill_color>ffffff</profile_sidebar_fill_color>
<profile_sidebar_border_color>d2d2d2</profile_sidebar_border_color>
<friends_count>288</friends_count>
<created_at>Mon Mar 03 21:06:45 +0000 2008</created_at>
<favourites_count>0</favourites_count>
<utc_offset>-21600</utc_offset>
<time_zone>Central Time (US & Canada)</time_zone>
<profile_background_image_url>http://a3.twimg.com/profile_background_images/64898326/twitter-bg-usagov.gif</profile_background_image_url>
<profile_background_image_url_https>https://si0.twimg.com/profile_background_images/64898326/twitter-bg-usagov.gif</profile_background_image_url_https>
<profile_background_tile>false</profile_background_tile>
<profile_use_background_image>false</profile_use_background_image>
<notifications></notifications>
<geo_enabled>false</geo_enabled>
<verified>true</verified>
<following></following>
<statuses_count>1560</statuses_count>
<lang>en</lang>
<contributors_enabled>false</contributors_enabled>
<follow_request_sent></follow_request_sent>
<listed_count>3233</listed_count>
<show_all_inline_media>false</show_all_inline_media>
<default_profile>false</default_profile>
<default_profile_image>false</default_profile_image>
<is_translator>false</is_translator>
</user>
<geo/>
<coordinates/>
<place/>
<contributors/>
</status>
Print out the content of all tweets in a file
Here's some code that loops through and parses each tweet in one of the files we've previously downloaded.
require "rubygems"
require "crack"
tweet_filename = "USAGov-tweets-page-1.xml"
tweets_file = File.open(tweet_filename)
parsed_xml = Crack::XML.parse( tweets_file.read )
tweets = parsed_xml["statuses"]
tweets.each do |tweet_xml|
puts "Created at: " + tweet_xml['created_at']
puts "Text: " + tweet_xml['text']
puts "Retweet count: "+ tweet_xml['retweet_count']
puts " - "
end
tweets_file.close
Think of the tweets variable as holding a collection of tweet XML objects. This is why we use .each to loop through each tweet.
The output should look something like this:
Created at: Tue Sep 13 17:01:04 +0000 2011 Text: September is National Preparedness Month. Find out how you can prepare for emergencies at http://t.co/uHj5fNF Retweet count: 15 - Created at: Mon Sep 12 22:55:12 +0000 2011 Text: September is National Ovarian Cancer Awareness Month. Learn about the risk factors and stay informed: http://t.co/83pfLOE Retweet count: 19 - Created at: Mon Sep 12 18:01:08 +0000 2011 Text: Hospital patients can now choose their own visitors and who can make end of life decisions. Learn more at http://t.co/JqORLBw Retweet count: 18 - Created at: Mon Sep 12 17:01:06 +0000 2011 Text: Create a video to help answer common questions about government benefits and services and you could win $1,000: http://t.co/rWWCGel Retweet count: 21
Loop through all the downloaded tweets
This uses the same technique for looping through the files you downloaded and then using the parsing code from the previous script.
You should end up with a program that contains two each loops, one inside the other:
require "rubygems"
require "crack"
tweet_basename = "USAGov-tweets-page-"
first_page = 1
last_page = 10
(first_page..last_page).each do |pg_num|
tweet_filename = tweet_basename + pg_num.to_s + ".xml"
tweets_file = File.open(tweet_filename)
parsed_xml = Crack::XML.parse( tweets_file.read )
tweets = parsed_xml["statuses"]
tweets.each do |tweet_xml|
puts "Created at: " + tweet_xml['created_at']
puts "Text: " + tweet_xml['text']
puts "Retweet count: "+ tweet_xml['retweet_count']
puts " - "
end
tweets_file.close
endThe result should be the parsed content of 1,000 tweets (or however many pages you downloaded).
Tweet Analysis
This next section contains some ways to count our collected data. I'm keeping the methods basic and just wanted to demonstrate how easy it is to loop through everything and perform any kind of analysis we want.
Daily tweeting rate, based on one page
In our requests to the Twitter API to download tweets, we set the tweets-per-page parameter to 100:
http://api.twitter.com/1/statuses/user_timeline.xml?count=100&screen_name=SOMEUSERNAME
But we can programmatically count the tweets by parsing the XML and getting an array of tweets, and then calling that array's length method:
require "rubygems"
require "crack"
tweet_filename = "USAGov-tweets-page-1.xml"
tweets_file = File.open(tweet_filename)
parsed_xml = Crack::XML.parse( tweets_file.read )
tweets = parsed_xml["statuses"]
puts tweets.length
The result:
100
Each tweet has a created_at field. So to find the tweeting rate over time – for a single page, at least –, we extract the created_at timestamp for the first and last tweets, convert them to time units (i.e. seconds), and divide the number of tweets by the difference in time between the first and last tweets:
require "rubygems"
require "crack"
tweet_filename = "USAGov-tweets-page-1.xml"
tweets_file = File.open(tweet_filename)
parsed_xml = Crack::XML.parse( tweets_file.read )
tweets = parsed_xml["statuses"]
total_tweet_count = tweets.length
# tweets are listed in chronological order, most recent first
most_recent_tweet = parsed_xml["statuses"].first # same as array[0]
earliest_tweet = parsed_xml["statuses"].last
most_recent_time = Time.parse(most_recent_tweet['created_at'])
earliest_time = Time.parse(earliest_tweet['created_at'])
puts "most recent time: " + most_recent_time.to_s
puts "earliest time: " + earliest_time.to_s
tweets_per_second = total_tweet_count / (most_recent_time - earliest_time)
tweets_per_day = tweets_per_second * 60 * 60 * 24
puts "Tweets per day: " + tweets_per_day.to_s
The results:
most recent time: Sun Oct 23 14:01:06 -0400 2011 earliest time: Fri Sep 09 13:01:50 -0400 2011 Tweets per day: 2.27060336028273
Daily tweeting rate based on all downloaded tweets
#Same thing, keep a counter of total tweets
require "rubygems"
require "crack"
tweet_basename = "USAGov-tweets-page-"
first_page = 1
last_page = 10
total_tweet_count = 0
earliest_tweet = 0
most_recent_tweet = 0
(first_page..last_page).each do |pg_num|
tweet_filename = tweet_basename + pg_num.to_s + ".xml"
tweets_file = File.open(tweet_filename)
parsed_xml = Crack::XML.parse( tweets_file.read )
tweets = parsed_xml["statuses"]
total_tweet_count = total_tweet_count + tweets.length
if pg_num == first_page
most_recent_tweet = tweets.first
end
if pg_num == last_page
earliest_tweet = tweets.last
end
end
puts "Total tweets collected: " + total_tweet_count.to_s
most_recent_time = Time.parse(most_recent_tweet['created_at'])
earliest_time = Time.parse(earliest_tweet['created_at'])
puts "most recent time: " + most_recent_time.to_s
puts "earliest time: " + earliest_time.to_s
tweets_per_second = total_tweet_count / (most_recent_time - earliest_time)
tweets_per_day = tweets_per_second * 60 * 60 * 24
puts "Tweets per day: " + tweets_per_day.to_sThe results (in my case, it was fewer than 1,000 because we didn't download the retweets):
Total tweets collected: 994 most recent time: Sun Oct 23 14:01:06 -0400 2011 earliest time: Tue Sep 29 15:56:13 -0400 2009 Tweets per day: 1.31844217383975
Number of replies to other users
Interested in something else besides number of tweets? Once you've figured out how to parse a data source, it's trivial to change what you're looking for.
In the following script, we check the <in_reply_to_screen_name> node of each tweet. If there is something in it, we push the name onto an Array. At the end of the script, we print out the number of names collected (using the array's length method), the number of unique names, and then just the entire list of names:
require "rubygems"
require "crack"
tweet_basename = "USAGov-tweets-page-"
first_page = 1
last_page = 10
tweeters_replied_to = []
(first_page..last_page).each do |pg_num|
tweet_filename = tweet_basename + pg_num.to_s + ".xml"
tweets_file = File.open(tweet_filename)
parsed_xml = Crack::XML.parse( tweets_file.read )
tweets = parsed_xml["statuses"]
puts "On page: " + pg_num.to_s
tweets.each do |tweet|
nm = tweet['in_reply_to_screen_name']
if nm.nil?
# do nothing, the field is empty
else
tweeters_replied_to.push(nm)
end
end
end
unique_tweeters_replied_to = tweeters_replied_to.uniq
puts "There were replies to " + tweeters_replied_to.length.to_s + " Tweeters"
puts "The number of unique names is: " + unique_tweeters_replied_to.length.to_s
puts "--"
puts unique_tweeters_replied_to
The results:
There were replies to 49 Tweeters The number of unique names is: 46
Tweet text analysis
For the purposes of this novice introduction, I'm only demonstrating the simplest ways to examine the tweets data we've collected. Using the same core of code from previous exercises, here are other simple aggregations we can do over the dataset:
- The total number of characters used
- A list, including the number of occurrences, of every word used (we can use regular expressions to count only strings of alphabetical characters used in a sentence, and not things like hashtags)
- The most frequently-used words
- The most frequently-used words having more than 4 characters
- The longest word used
The code is not any more conceptually complex than what we've already run through. But I'm not going to explain the details at length and I expect much of it to be unfamiliar to you. If you've come this far, it's a better use of your time for you to move on to the explanatory lessons to learn what's going on at a deeper level, rather than have me try to come up with oversimplified explanations.
So again, you're not expected to understand it if you're new to programming. I include it just to let you experiment with for fun. You'll probably recognize the same patterns we've been using in our code.
require 'rubygems'
require 'crack'
tweet_basename = "USAGov-tweets-page-"
first_page = 1
last_page = 10
total_tweet_count = 0
total_chars_in_tweets = 0
word_list = {}
(first_page..last_page).each do |pg_num|
tweet_filename = tweet_basename + pg_num.to_s + ".xml"
tweets_file = File.open(tweet_filename)
parsed_xml = Crack::XML.parse( tweets_file.read )
tweets = parsed_xml["statuses"]
puts "On page: " + pg_num.to_s
# A running total of tweets
total_tweet_count += tweets.length
tweets.each do |tweet|
# The tweet text, in lowercase letters
txt = tweet['text'].downcase
# A running total of total tweet length in characters
total_chars_in_tweets += txt.length
# Regular expression to select any string of consecutive
# alphabetical letters (with optional apostrophes and hypens)
# that are surrounded by whitespace or end with a punctuation mark
words = txt.scan(/(?:^|\s)([a-z'\-]+)(?:$|\s|[.!,?:])/).flatten.select{|w| w.length > 1}
# Use of the word_list Hash to keep list of different words
words.each do |word|
word_list[word] ||= 0
word_list[word] += 1
end
end
end
puts "\nTotal tweets:"
puts total_tweet_count
puts "\nTotal characters used:"
puts total_chars_in_tweets
puts "\nAverage tweet length in chars:"
puts(total_chars_in_tweets/total_tweet_count)
puts "\nNumber of different words:"
puts word_list.length
puts "\nNumber of total words used:"
puts word_list.inject(0){|sum, w| sum += w[1]}
# sort word_list by frequency of word, descending order
word_list = word_list.sort_by{|w| w[1]}.reverse
puts "\nTop 20 most frequent words"
word_list[0..19].each do |w|
puts "#{w[0]}:\t#{w[1]}"
end
puts "\nTop 20 most frequent words more than 4 characters long"
word_list.select{|w| w[0].length > 4}[0..19].each do |w|
puts "#{w[0]}:\t#{w[1]}"
end
puts "\nLongest word:"
puts word_list.max_by{|w| w[0].length}[0]
The output of the analysis:
Total tweets:
994
Total characters used:
116128
Average tweet length in chars:
116
Number of different words:
1781
Number of total words used:
9080
Top 20 most frequent words
http: 774
the: 367
to: 277
learn: 276
at: 193
and: 187
you: 183
find: 164
of: 154
for: 143
your: 142
if: 95
from: 94
is: 88
in: 86
on: 64
how: 62
get: 61
this: 58
today: 57
Top 20 most frequent words more than 4 characters long
learn: 276
today: 57
about: 52
national: 50
these: 35
summer: 30
happy: 28
check: 27
government: 24
there: 23
federal: 19
follow: 18
information: 18
credit: 18
video: 18
school: 17
health: 17
season: 17
create: 16
people: 16
Longest word:
annualcreditreport
Granted, it's nothing too exciting. But I tried to use the most basic methods for this introductory chapter. Once you have a decent grasp on programming concepts, it's easy to do much more useful calculations.
On to the theory
As much fun as it is to get things done by just doing the copy-and-paste and push-the-Run-button procedure, the intent of this book is to teach you to write your own programs, not to just run pre-written code.
Hopefully this chapter gives you an idea of what a little code can accomplish and how easy it is to execute it. Every concept here is covered in the Fundamentals section of this book.