
In the previous chapters on web-scraping, we saw how scraping data from webpages doesn't require a deep knowledge of HTML. The browser's web inspector provides a point-and-click interface to see where page elements are described in the raw HTML and to examine the raw data going in and out of your browser. If the raw data isn't already in spreadsheet-ready form, the Nokogiri gem makes it especially simple to extract the data from HTML.
The next piece of the puzzle is how to program a scraper that navigates the relevant parts of a website. Sometimes it just takes a simple loop. Other times, the scraper will have to process information from one page to figure out where to go next.
There's no one kind of program that will scrape the variety of the world's websites with the specificity that you'll need to find interesting, organized data. This is why learning enough code to write your own scraper will ultimately be a better investment than any commercial ready-made web-scraper you can buy.
This chapter will list examples of the common structures for so that you'll have a general blueprint for scraping any given website.
Why not wget?
If you've had prior experience with the command-line, then you may know of wget, a powerful program that lets you mirror websites in a single line. You can find download and installation instructions at its homepage: http://www.gnu.org/s/wget/
You run wget from the command-line by specifying a target URL and options. To download a copy of the White House's homepage, including all of its visual elements, you simply type:
wget -k -p http://www.whitehouse.gov
That will launch wget into a frenzy of downloading (though, when applied to one page, it's not much different than how your browser works) the page and its assets to your hard drive:
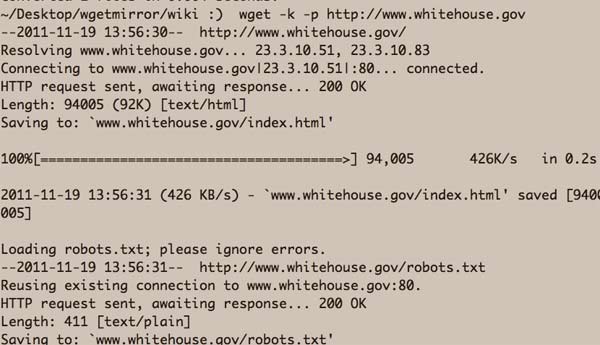
wget has many useful built-in features, including the ability to resume broken connections and mirror an entire site. That latter feature can cause your IP to be blocked, however, unless you specify a wait period so that the crawler doesn't hammer the site.
This chapter will walk through how to crawl various kinds of websites, and all of the methods will be much more complex than running wget. So why not just use wget?
For simple sites, wget will suffice, especially if your goal is to only make a local copy for later parsing. But in order to do that parsing, you'll usually have to write some code using something like Nokogiri anyway.
For more complicated scraping jobs, though, especially for sites that require user input, wget may not get everything that you need. There's quite a few tricks you can use to get the most out of wget, but at some point, that gets more complicated than just working in Ruby.
Move Link-to-Link (Wikipedia)
The most straight-forward kind of web-scraping involves moving from page-to-page based on the links that exist on each page.
Take a look at the Wikipedia entry for Nobel laureates:
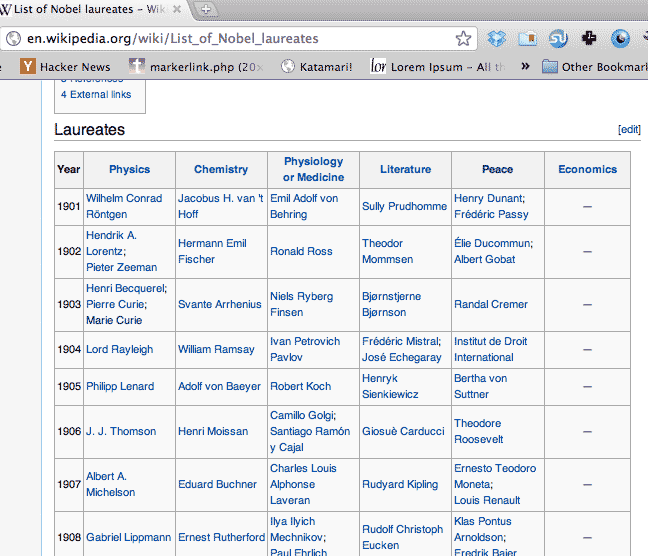
If all you needed was the data in tabular format, then there's no need for scraping. In fact, you can highlight the table and copy-and-paste it directly into Excel and then convert it to HTML. But that's not particularly helpful to readers, except to save them a trip to the Wikipedia list themselves.
Click on one of the links for any of the recipients, such as Marie Curie's':

Note how Wikipedia contributors have helpfully organized Madame Curie's information, such as country of origin, fields of expertise, and alma mater. We already know how to easily capture those from the HTML parsing chapter.
The advantages of knowing how to web-scrape should start to become clearer now. The copy-and-paster can only copy-and-paste what the Wikipedia editors have deemed useful as tabular information. Digging for an extra layer of information requires a mind-numbing amount of additional copy-and-pasting (and clicking).
But once you know a little code, scripting a scraper to visit each page and parse it is trivial in comparison. Then you can present the laureates list through different views, such as a list by nationality (as an easy example). The point is: your analyses no longer hindered by cumbersome data collection.
Here's how to write a scraper that downloads all the relevant pages.
Target the links with Nokogiri
This is just simple HTML parsing. Let's start with just finding each table row in the laureates listing. The web inspector conveniently lists the row's specific CSS selector:
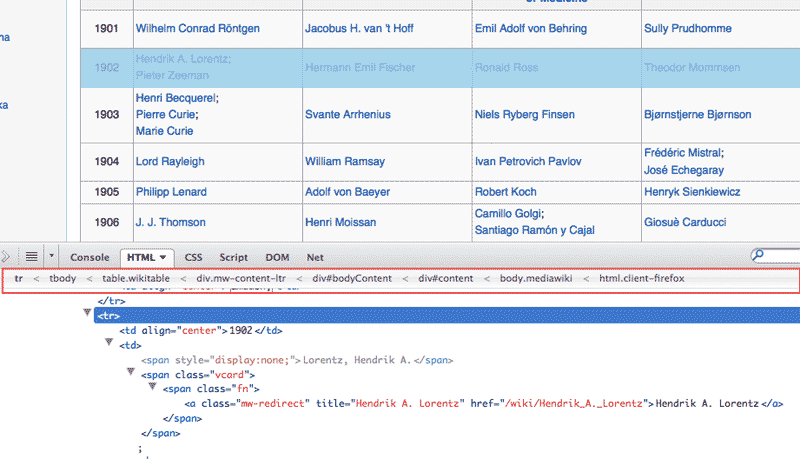
You can include as much of the CSS selector as you want. It takes a little experience to quickly see how wide to cast the net. Sometimes websites will inject new selectors or attributes that aren't present in the raw source code. For example, this is the CSS path as determined by Firefox's Firebug:
html.client-firefox body.mediawiki div#content div#bodyContent div.mw-content-ltr table.wikitable tbody tr
Wikipedia adds the .client-firefox class to the <html> element, which is an obvious reflection of us using the Firefox browser. Furthermore, I've found that the <tbody> element is sometimes inserted into HTML tables by the browser, as it's often left out by the original authors of the HTML.
Think of the web inspector's display of the provides a guideline for the CSS selector to target with Nokogiri.css, so don't follow it literally. Here's a script with a broad enough CSS selector that targets the table rows:
BASE_WIKIPEDIA_URL = "http://en.wikipedia.org"
LIST_URL = "#{BASE_WIKIPEDIA_URL}/wiki/List_of_Nobel_laureates"
page = Nokogiri::HTML(open(LIST_URL))
rows = page.css('div.mw-content-ltr table.wikitable tr')
Use your web inspector if you're still unfamiliar with how an HTML table is structured – rows and columns as <tr> and <td> tags, respectively. Your inspection should also reveal that all the relevant links have href attributes like: "/wiki/Ahmed_Zewail"
So to cycle through each row and filter for the correct kind of href, we iterate through the collection of rows and make another call to the css method:
rows[1..-2].each do |row|
hrefs = row.css("td a").map{ |a|
a['href'] if a['href'].match("/wiki/")
}.compact.uniq
hrefs.each do |href|
puts href
end
end- The css method call targets all <a> links within <td> tags.
- From each <a>, the map grabs the URL from the href attribute, but only if the URL includes "/wiki/"
- For links that don't match the "/wiki/" pattern, they will be represented as nil values in collection returned by map. We use compact to remove those nil values from the collections.
- Finally, the uniq method returns a collection with duplicate values removed.
After all that code – the vast majority of it boilerplate and constants, what do we have? A list of all the links to each recipient's page:
require 'rubygems'
require 'nokogiri'
require 'open-uri'
BASE_WIKIPEDIA_URL = "http://en.wikipedia.org"
LIST_URL = "#{BASE_WIKIPEDIA_URL}/wiki/List_of_Nobel_laureates"
page = Nokogiri::HTML(open(LIST_URL))
rows = page.css('div.mw-content-ltr table.wikitable tr')
rows[1..-2].each do |row|
hrefs = row.css("td a").map{ |a|
a['href'] if a['href'] =~ /^\/wiki\//
}.compact.uniq
hrefs.each do |href|
remote_url = BASE_WIKIPEDIA_URL + href
puts remote_url
end # done: hrefs.each
end # done: rows.each
To have the scraper download and store each page to the hard drive, I make these additions:
- Some boilerplate code to set the local directory (DATA_DIR) and filenames
- A sleep delay. The Wikipedia site is wonderfully robust but we should give it a second or two between page requests.
-
A begin/rescue block – something I cover in the exception-handling chapter. This allows us to cope with the Wikipedia site not responding as expected to our requests. The most common failure will be if the site is down or otherwise refuses to respond.
I go into further detail in the exception-handling chapter. The likely point of failure in our code is in the line that fetches the remote page (more about HEADERS_HASH in the next bullet point):
wiki_content = open(remote_url, HEADERS_HASH).readWe wrap that in a begin block. The rescue block is where the program will jump to if an error happens in the begin block. The else block is what should happen if no error is encountered in the begin block. Finally, the ensure block will always execute no matter what happens in the begin block.
I may cover error-handling in a later edition. For now, the Pragmatic Programmer's Guide does a nice job of it.
- For some pages – such as Al Gore's locked-down entry – Wikipedia will not respond to a web request if a User-Agent isn't specified. The "User-Agent" typically refers to your browser, and you can see this by inspecting the headers you send for any page request in your browser. By providing a "User-Agent" key-value pair, (I basically use "Ruby" and it seems to work), we can pass it as a hash (I use the constant HEADERS_HASH in the example) as the second argument of the method call.
Here's the Nobel laureates scraper:
require 'rubygems'
require 'nokogiri'
require 'open-uri'
DATA_DIR = "data-hold/nobel"
Dir.mkdir(DATA_DIR) unless File.exists?(DATA_DIR)
BASE_WIKIPEDIA_URL = "http://en.wikipedia.org"
LIST_URL = "#{BASE_WIKIPEDIA_URL}/wiki/List_of_Nobel_laureates"
HEADERS_HASH = {"User-Agent" => "Ruby/#{RUBY_VERSION}"}
page = Nokogiri::HTML(open(LIST_URL))
rows = page.css('div.mw-content-ltr table.wikitable tr')
rows[1..-2].each do |row|
hrefs = row.css("td a").map{ |a|
a['href'] if a['href'] =~ /^\/wiki\//
}.compact.uniq
hrefs.each do |href|
remote_url = BASE_WIKIPEDIA_URL + href
local_fname = "#{DATA_DIR}/#{File.basename(href)}.html"
unless File.exists?(local_fname)
puts "Fetching #{remote_url}..."
begin
wiki_content = open(remote_url, HEADERS_HASH).read
rescue Exception=>e
puts "Error: #{e}"
sleep 5
else
File.open(local_fname, 'w'){|file| file.write(wiki_content)}
puts "\t...Success, saved to #{local_fname}"
ensure
sleep 1.0 + rand
end # done: begin/rescue
end # done: unless File.exists?
end # done: hrefs.each
end # done: rows.each
The specified local directory should have about 850 new HTML files in it. This is the sample output to screen:
Fetching http://en.wikipedia.org/wiki/Adolf_von_Baeyer... ...Success, saved to data-hold/nobel/Adolf_von_Baeyer.html Fetching http://en.wikipedia.org/wiki/Adolf_Otto_Reinhold_Windaus... ...Success, saved to data-hold/nobel/Adolf_Otto_Reinhold_Windaus.html Fetching http://en.wikipedia.org/wiki/Adolf_Butenandt... ...Success, saved to data-hold/nobel/Adolf_Butenandt.html Fetching http://en.wikipedia.org/wiki/Adolfo_P%C3%A9rez_Esquivel... ...Success, saved to data-hold/nobel/Adolfo_P%C3%A9rez_Esquivel.html Fetching http://en.wikipedia.org/wiki/Adam_Riess... ...Success, saved to data-hold/nobel/Adam_Riess.html
Parsing the tables
Hey, this is not useful data!
Astute readers will note that my code does little more than mass download every page on the Nobel laureates page. This is something a plugin like DownloadThemAll! can do – and probably more reliably. The scraper doesn't actually get data.
This is true. In the above code snippets, I only show the basics of doing a web-crawl. With a little more configuration, we can use the structure of the Nobel laureates table to structure the data from each individual page to our liking. Such as finding the nationalities of every Chemistry prize winner, to use a cliche example.
I will do a write-up of this in the near-feature iteration of this lesson. But by now, you've learned enough to do this on your own. You may not have data yet, but you have the material from which the data can be easily extracted.
## TK How different from wget?Change URL parameters (Data.gov)
Spidering a website, link by link, as we did in the Nobel prizes Wikipedia example, will work for most websites. However, it can be kind of tedious to examine each different kind of page to figure out the link structure.
But if you do a little scouting and experimentation, you may find a pattern in the site's URL that you use to save yourself a considerable amount of time.
The most obvious examples are sites that paginate their information. The federal government's Data.gov Raw Data catalog, for example, has 3,500+ datasets but only lists 25 per page:
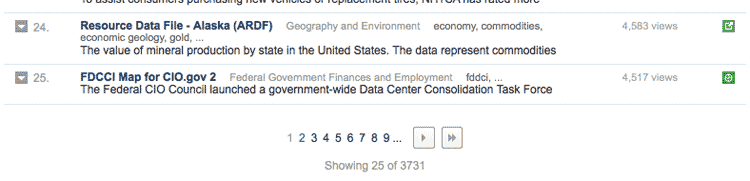
Clicking on the link for Page 2 predictably gets the page for the next 25 results. Take a look at the URL in your browser:
http://explore.data.gov/catalog/raw/?&page=2
And if you visit Page 3, the link looks like this:
http://explore.data.gov/catalog/raw/?&page=3
See a pattern? We can simply write a loop that increments the page number in the URL. We'll save each HTML page to disk, which we can later parse at our leisure.
The last page number is helpfully included in the href attribute of the » button. So parse the first page with Nokogiri to find that number. Then use a for loop to iterate through each page number:
require 'rubygems'
require 'nokogiri'
require 'open-uri'
require 'fileutils'
BASE_URL = 'http://explore.data.gov'
BASE_DIR = '/catalog/raw/?&page='
LOCAL_DIR = 'data-hold/datagov-pages'
FileUtils.makedirs(LOCAL_DIR) unless File.exists?LOCAL_DIR
# get metainfo from first page:
page = Nokogiri::HTML(open(BASE_URL+BASE_DIR + '1'))
# write the HTML for page 1 to disk
File.open("#{LOCAL_DIR}/1.html", 'w'){|f| f.write(page.to_html)}
last_page_number = page.css("a.end.lastLink.button")[0]['href'].match(/page=(\d+)/)[1].to_i
puts "Iterating from 2 to #{last_page_number}"
for pg_number in 2..last_page_number do
puts "Getting #{pg_number}"
File.open("#{LOCAL_DIR}/#{pg_number}.html", 'w') do |f|
f.write( open("#{BASE_URL}#{BASE_DIR}#{pg_number}").read )
end
end
Push it to the limit
By virtue of having scraped the Data.gov Raw Data catalog in the past, I know of an extra URL parameter that will greatly reduce the number of requests we need to make:
http://explore.data.gov/catalog/raw/?&limit=100&page=2
The limit parameter apparently tells the server the maximum number of results to send back per page. The default limit, as we've seen, is 25. So increasing the value for limit reduces the number of pages we need to loop through.
Play around with it some more. You'll see that giving it an arbitrarily large number such as 100000 won't have any effect. Once you find a maximum, change the URL in the previous scraping script to include a set limit. I was able to get the number of loop iterations to under 10.
How did I find this out? Just dumb luck from having previously scraped this site. The current design doesn't reveal the limit parameter so I just tried it out for fun, and it turns out the site designer didn't close down the use of that parameter.
In most cases, blind experimentation won't net you much. But don't underestimate the carelessness that can creep into a site design. In the following sections, I will show how your web inspector can help you suss out shortcuts and loopholes that aren't out in the open.
Detecting redirects (Defense.gov)
Here's a variation to the above change-the-page-number formula:
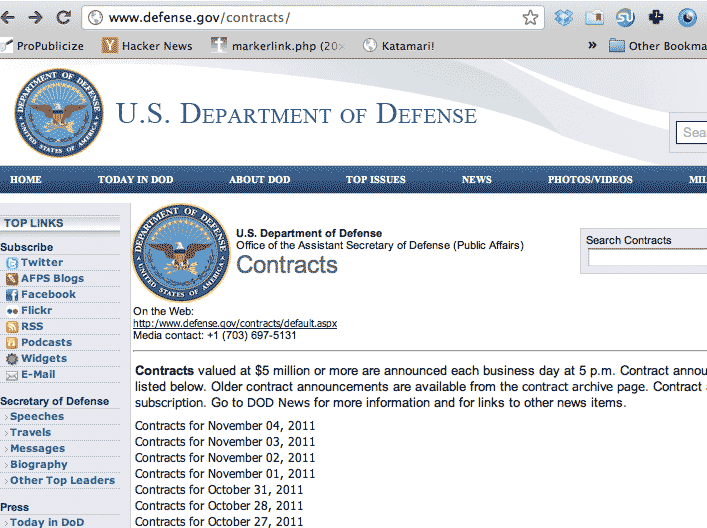
The Department of Defense publishes a daily listing of contracts at the following address: http://www.defense.gov/contracts
The default listing contains the last 30 days worth of contracts:
Each contracts list looks like this:
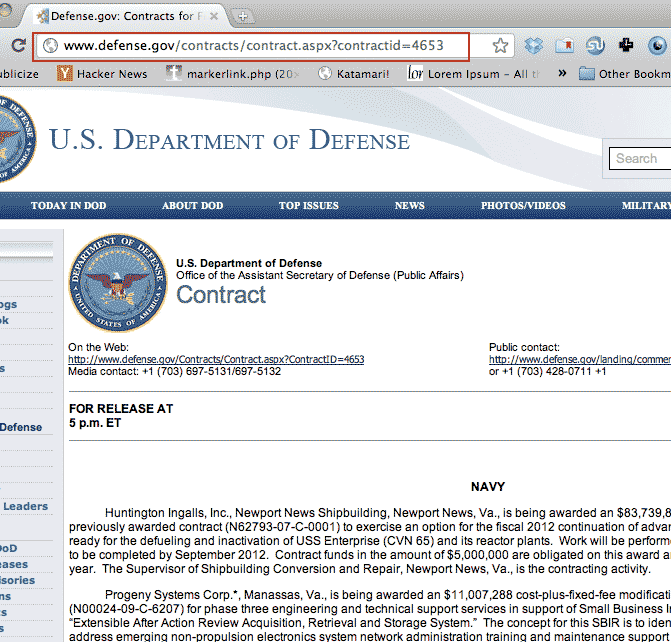
Take note of the URL:
http://www.defense.gov/contracts/contract.aspx?contractid=4653
That seems like a pretty obvious pattern. However, when you go to a URL with contractid=1, you get redirected to the Defense.gov homepage.
However, other small numbers seem to work for contractid, such as 10:
http://www.defense.gov/contracts/contract.aspx?contractid=10
So we can still loop through contract numbers. But it'll require a few modifications. Here's a working script:
require 'rubygems'
require 'nokogiri'
require 'open-uri'
require 'fileutils'
PAGES_DIR='data-hold/pages'
FileUtils.makedirs(PAGES_DIR)
BASE_URL = 'http://www.defense.gov/contracts'
S_URL = 'contract.aspx?contractid='
# Get index of most recent script:
index_page = Nokogiri::HTML(open(BASE_URL))
# scrape the homepage to find the latest index
S_C_TABLE_ID = '#ctl00_ContentPlaceHolder_Body_tblContracts'
latest_index = nil
if clinks = index_page.css("#{S_C_TABLE_ID} a")
latest_index = clinks.map{|c| c['href'].match(/contract.aspx\?contractid=(\d+)/)[1].to_i }.max
else
"In index page #{BASE_URL}, expected id #{S_C_TABLE_ID}"
end
STARTING_INDEX = 1
puts "Crawling index from #{STARTING_INDEX} to #{latest_index}"
(STARTING_INDEX..latest_index).each do |idx|
url = "#{BASE_URL}/#{S_URL}#{idx}"
puts "Getting #{url}"
retries = 2
begin
resp = Net::HTTP.get_response(URI.parse(url))
if resp.code.match('200')
fname = "#{PAGES_DIR}/#{idx}.html"
File.open(fname, 'w') do |ofile|
ofile.write(resp.body)
end
puts "Saved to #{fname}"
else
puts "\tNot a valid page"
end
rescue StandardError=>e
puts "#{idx}: #{e}"
if retries > 0
puts "Retrying #{retries.length} more times"
retries -= 1
sleep 40
retry
end
else
sleep 3.0 + rand * 3.0
end
end
The output:
Crawling index from 1 to 4662 Getting http://www.defense.gov/contracts/contract.aspx?contractid=1 Not a valid page Getting http://www.defense.gov/contracts/contract.aspx?contractid=2 Not a valid page Getting http://www.defense.gov/contracts/contract.aspx?contractid=3 Not a valid page Getting http://www.defense.gov/contracts/contract.aspx?contractid=4 Not a valid page Getting http://www.defense.gov/contracts/contract.aspx?contractid=5 Not a valid page Getting http://www.defense.gov/contracts/contract.aspx?contractid=6 Saved to data-hold/pages/6.html Getting http://www.defense.gov/contracts/contract.aspx?contractid=7 Saved to data-hold/pages/7.html Getting http://www.defense.gov/contracts/contract.aspx?contractid=8 Saved to data-hold/pages/8.html Getting http://www.defense.gov/contracts/contract.aspx?contractid=9 Saved to data-hold/pages/9.html Getting http://www.defense.gov/contracts/contract.aspx?contractid=10 Saved to data-hold/pages/10.html Getting http://www.defense.gov/contracts/contract.aspx?contractid=11 Not a valid page Getting http://www.defense.gov/contracts/contract.aspx?contractid=12 Saved to data-hold/pages/12.html
Here are the particulars:
- This script includes some basic exception handling. The Defense.gov site seems to raise a EOFError every once in awhile. This script takes a 40-second break before trying again. I cover exception handling in a separate chapter.
- Instead of using RestClient.get or OpenURI#open, we instead use Net::HTTP.get_response to request the URLs. The full explanation below:
Detecting redirects
Because not all numbers for contract_id lead to a valid contract page, we need to reject the pages that redirect to the Defense.gov homepage. Both the RestClient and OpenURI modules will automatically follow the redirect. So all we would need to do is just examine the retrieved page's <title>:
require 'rubygems'
require 'restclient'
require 'nokogiri'
for id in 1..4000
page = Nokogiri::HTML(RestClient.get("http://www.defense.gov/contracts/contract.aspx?contractid=#{id}"))
title = page.css('title').text
if title =~ /Defense.gov: Contracts for/
# download the page
else
puts "Not a valid contract page"
end
endThe above code is effective, but not efficient. Consider what happens when it hits a redirect:
- The open method asks the server (defense.gov) for http://www.defense.gov/contracts/contract.aspx?contractid=10
- The server responds with a 302 status code (a redirect) and a new destination: http://www.defense.gov
- The open method automatically asks for http://www.defense.gov
- The server sends the page at http://www.defense.gov
- Nokogiri::HTML parses the response for the <title> tags and realizes it is not a contracts page. Response is tossed
So we end up downloading two pages when we had all the info we needed in the first request (step #2 from above). Instead, we can use the get_response method from the Net::HTTP library to ask for the the HTTP status code. If the code is not in the 200s, then the URL either redirects (300s) or otherwise fails (read more about HTTP status codes here). We can skip trying to download it – and the DoD will appreciate our scraper not chewing up needless bandwidth.
If the response's code is a 200, then its body method will contain the HTML we want:
require 'rubygems'
require 'net/http'
require 'open-uri'
require 'nokogiri'
(10..15).each do |id|
url = "http://www.defense.gov/contracts/contract.aspx?contractid=#{id}"
puts "\nGetting #{url}"
resp = Net::HTTP.get_response(URI.parse(url))
if resp.code.match(/20\d/)
puts "Success:"
puts Nokogiri::HTML(resp.body).css('title').text
else
puts "\tNot a valid page; response was: #{resp.code}"
end
end
Think of Net::HTTP.get_response as a lower-level version of the open (or RestClient.get) method in that it doesn't automatically follow redirects. Otherwise, it gets us the webpage just as well as the other, higher-level methods.
POST requests (FEC.gov)
Every kind of website we've dealt so far involves pages with actual direct links (sometimes known as permalinks).
In other words, this URL:
http://www.defense.gov/contracts/contract.aspx?contractid=4653
– will always (or should always, unless the webmaster is changing things around) refer to this page of Department of Defense contracts for 10/28/2011 . If you wanted to email someone: "Hey, check out these Oct. 28, 2011 DoD contracts," you would send them that link.
However, many websites require you to fill out and submit a form. The website then directs you to a URL for a page of results. But the page at that URL depends on parameters set by that previous form. That URL does not act as a direct link. If you go to that URL directly, the page will not show you the same results.
In essence, the results page depends on the user having first visited and filled out the previous form page.
The Federal Election Commission Report Image Search
Note: It's probably a massive drain for both FEC.gov and your Internet connection to download the hundreds of thousands of image reports with this kind of scraper. that's your intention, I would recommend contacting the FEC itself. This is just a proof of concept.
The Federal Election Commission (FEC) is the clearinghouse for campaign finance information. One of its datastores includes the filing reports – as PDFs – of every campaign and committee. How useful is it to have the PDFs when the FEC already provides raw data files? I don't know; it's possible every single bit of information in the PDFs is compiled in a raw database somewhere else. Also, many of the PDFs contain poor-quality scans and handwritten answers. Parsing them is not a trivial task.
But I use their site only as an example of the type that handle POST requests. The code used here can be used on similar websites of interest.
Performing a search
Go to the FEC Report Image Search page and enter a partial search term. Click Get Listing and you'll go to a new page with the results:
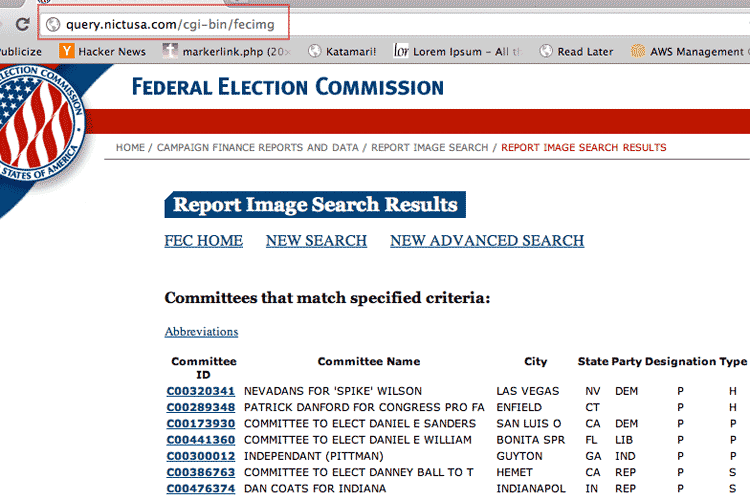
But the URL – http://query.nictusa.com/cgi-bin/fecimg – is not the address of the current results listing. It's the address of a script that depends on the previous form being submitted. If you visit the link directly, you'll see this error page:

Inspect the search page's request
Return to the search form page. Pop open your inspector's network panel (review the chapter on the network panel if you need to), submit a search term, and check out the headers for a file named fecimg:
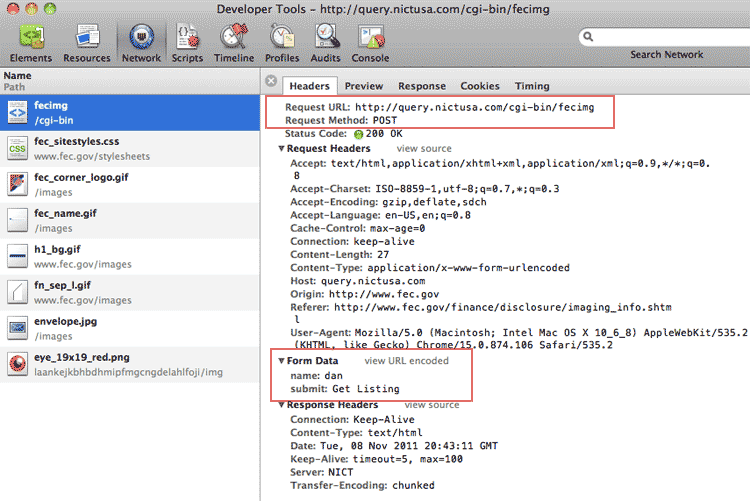
As you can see in the highlighted area bove, the search form makes what is called a POST request, which is a way for forms to submit a web request when the parameters can't fit in a URL.
Most of the HTTP requests we've executed so far have been GET-type requests, hence, the use of RestClient.get. The Wikipedia API call for suggested search terms (covered in the network panel chapter), for example, is able to fit its parameters in the URL:
http://en.wikipedia.org/w/api.php?action=opensearch&search=Dan
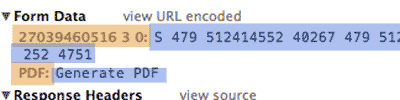
How do we see the parameters set by the FEC's image search form? The network panel reveals the parameters in the request headers. The following image is a close crop of the above photo, but cropped to the Form Data section (this is using Chrome's inspector):
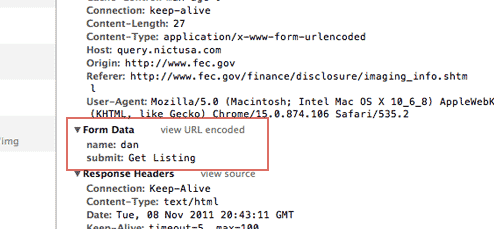
So the data sent by the search form to the script named fecimg is simply the search term and the button we pushed:
name:dan submit:Get Listing
So to programmatically download a page of results, we use RestClient.post and we submit the form data parameters as a hash:
require 'rubygems'
require 'restclient'
require 'nokogiri'
REQUEST_URL = "http://query.nictusa.com/cgi-bin/fecimg"
name_term = 'dan'
if page = RestClient.post(REQUEST_URL, {'name'=>name_term, 'submit'=>'Get+Listing'})
puts "Success finding search term: #{name_term}"
File.open("data-hold/fecimg-#{name_term}.html", 'w'){|f| f.write page.body}
npage = Nokogiri::HTML(page)
rows = npage.css('table tr')
puts "#{rows.length} rows"
rows.each do |row|
puts row.css('td').map{|td| td.text}.join(', ')
end
end The sample output:
Success finding search term: dan 479 rows CommitteeID, Committee Name, City, State, Party, Designation, Type, CandidateState, CandidateOffice C00320341, NEVADANS FOR 'SPIKE' WILSON , LAS VEGAS, NV, DEM, P, H, NV, House C00289348, PATRICK DANFORD FOR CONGRESS PRO FA, ENFIELD, CT, , P, H, CT, House C00173930, COMMITTEE TO ELECT DANIEL E SANDERS, SAN LUIS O, CA, DEM, P, P, 00, President C00441360, COMMITTEE TO ELECT DANIEL E WILLIAM, BONITA SPR, FL, LIB, P, P, 00, President C00300012, INDEPENDANT (PITTMAN) , GUYTON, GA, IND, P, P, 00, President C00386763, COMMITTEE TO ELECT DANNEY BALL TO T, HEMET, CA, REP, P, S, CA, Senate C00476374, DAN COATS FOR INDIANA , INDIANAPOL, IN, REP, P, S, IN, Senate C00364364, DANIEL K INOUYE FOR U S SENATE , HONOLULU, HI, DEM, A, S, HI, Senate C00390120, DANIEL WEBSTER FOR US SENATE , TAMPA, FL, REP, P, S, FL, Senate ...
Because we now know the name of the search script – fecimg – we don't visit the webpage with the search form. There's no need to – we know the parameters that fecimg needs through web inspection. And so we feed the fecimg script directly through our script. The search form was merely a way to fill those parameters through your web browser.
This covers the basics of making a POST request. The next two sub-sections cover the inside pages of the FEC image search site, which involves a combination of standard GET requests (for the permalinks) and a POST request to generate a PDF.
The committees list
This is pretty straightforward. All the links for each committee page can be found via this css selector:
links = npage.css('div#fec_mainContent table tr td a')Each link goes to a page that lists the given committee's filings. The links are in this format:
http://query.nictusa.com/cgi-bin/fecimg/?C00364364
This particular link goes to the filings from the principal campaign committee with U.S. Senator Daniel Inouye (D-Hawaii)
The committee's filings list
Now things get a little more interesting. Here's what a committee's filings page looks like:
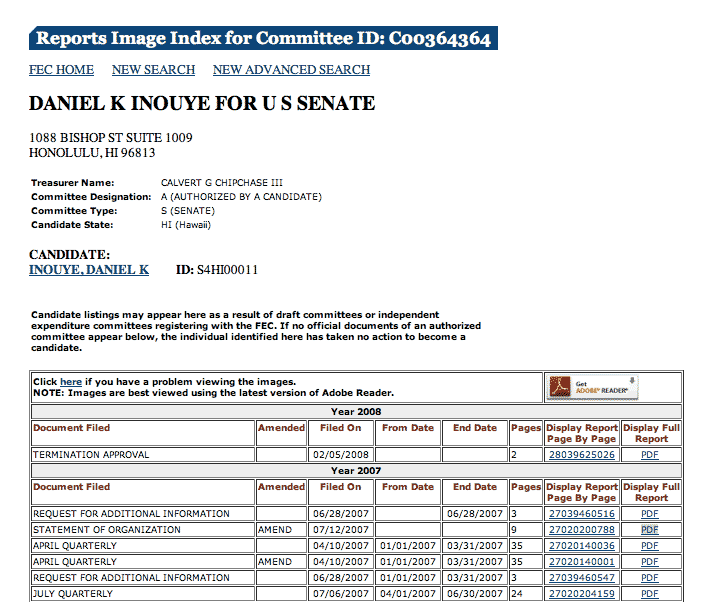
All the links for the PDF filings are conveniently in the last column of the tables. In the next-to-last column are links to page-by-page browse the PDFs, which we can ignore for now as we want the whole files for download.
For reports that were filed electronically in more recent years, the links go directly to actual PDF files, which are pretty straightforward to download. The URLs look like:
http://query.nictusa.com/pdf/026/28039625026/28039625026.pdf#navpanes=0
But then there are links to filings that look like this:
http://query.nictusa.com/cgi-bin/fecimg/?F27039460516
If you follow this sample link, it does not go to a PDF. Instead, you're directed to an intermediary page that prompts you to click a button – helpfully labeled "Generate PDF" – before dynamically generating the desired PDF:
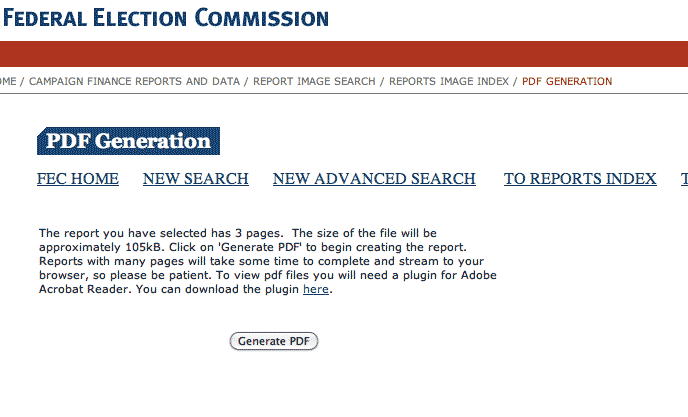
Clicking it sends you to this page
Which then sends us to a PDF to view in-browser. Note the generic URL in the browser's address bar: cgi-bin/fecgifpdf/. It doesn't have any unique identifier that would correspond to a file and so is likely not a direct link to the PDF.
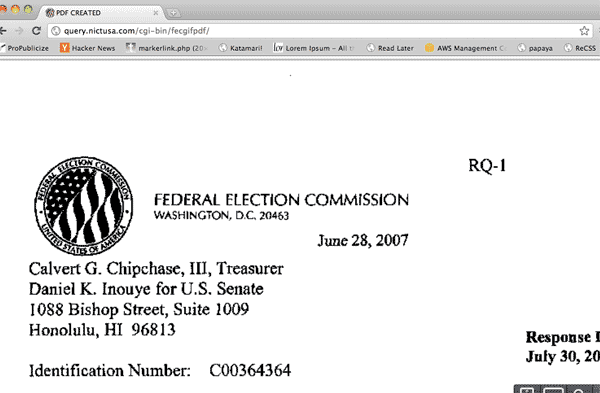
So the page created by the PDF-generation operation isn't a deep-link. But if by inspecting the source, we see that the server has sent over a webpage that basically consists of an embedded PDF:
<HTML><HEAD>
<TITLE>PDF CREATED</TITLE>
</HEAD>
<BODY>
<EMBED width=100% height=100% fullscreen=yes TYPE="application/pdf" src="http://images.nictusa.com/dataout/showpdf/6290/6290.pdf#zoom=fit&navpanes=0">
</BODY>
</HTML>
However, the URL for the embedded PDF appears to be temporary and will not work if you bookmark it later.
"Push" a button with a program
So how does our scraper "push" the button to get the server to build out those PDFs? We look for the POST request triggered by the button. So go back to the individual report page that has the "Generate PDF" button.
Activate your network panel. And click the button. The POST request may disappear before you get a chance to examine it, but it will look like this:
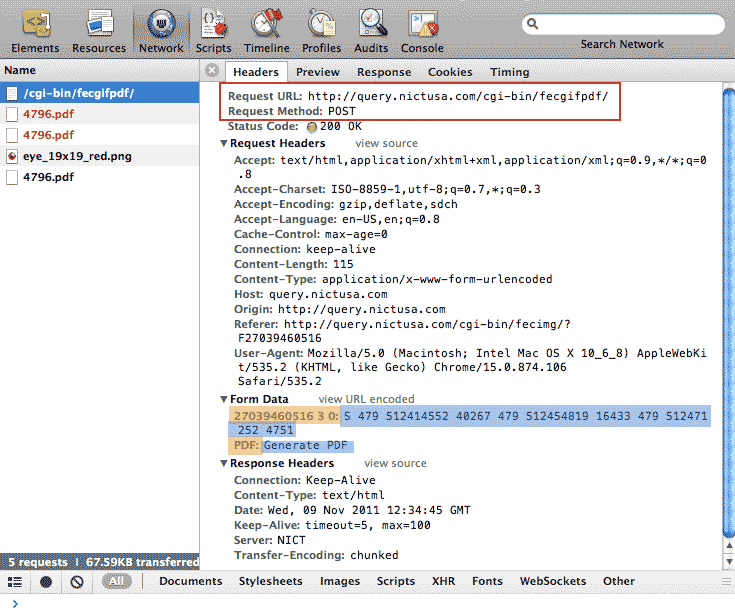
That button is actually part of an HTML form – which we will inspect in the next step. I've highlighted the two parameters: the keys are in orange and their values are in blue.
A brief primer to HTML forms
Go back to the page with the "Generate PDF" button again and now inspect the source.
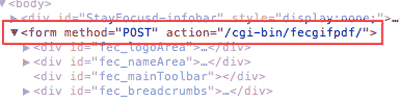
In the screenshot of the raw HTML below, I've emphasized the HTML <form> and <input> elements that correspond to the data payload we saw when inspecting the POST request headers in the network panel:
| Request headers | HTML source |
|---|---|
 |
 |
 |
 |
As we see in the above table, all of the information behind the POST request we saw in the network panel is inside the HTML <form> and <input> elements.
This means we can parse the HTML to find the needed parameters to generate the PDF. In fact, the type of request and URL of the server-side script – POST and fecgifpdf, respectively – are specified in the <form>'s attributes, method and action.
The PDF-fetching code
Here are the steps needed to programmatically download the generated PDFs:
- Retrieve the page via the direct link for the given report (these links are found in the page listing the committee's filings).
- Use Nokogiri to parse the page's HTML form to find the parameters for the POST request's data payload.
- Use RestClient.post
- The server should respond with a new HTML page.
- Parse this HTML for the <embed> element with the URL of the generated PDF.
- Write the PDF to your hard drive.
Here's the code:
require 'rubygems'
require 'restclient'
require 'nokogiri'
# This is the URL for the POST request:
CGI_URL = 'http://query.nictusa.com/cgi-bin/fecgifpdf/'
# base_url + f_id = the URL for the form page with the button
base_url = 'http://query.nictusa.com/cgi-bin/fecimg/?'
f_id = 'F26038993028'
## 1 & 2: Retrieve the page with PDF generate button
form_page = Nokogiri::HTML(RestClient.get(base_url + f_id))
button = form_page.css('input[type="hidden"]')[0]
## 3: Do POST request
pdf_resp = RestClient.post(CGI_URL, {button['name']=>button['value'],
'PDF'=>'Generate+PDF'})
## 4 & 5: A successful POST request will result in a new HTML page to parse
if embed = Nokogiri::HTML(pdf_resp).css('embed')[0]
pdf_name = embed['src']
puts "PDF found: #{pdf_name}"
## 6: Save PDF to disk
File.open("#{f_id}--#{pdf_name.match(/\d+\.pdf/)}", 'w') do |f|
f.write(RestClient.get(pdf_name))
end
endProblems with large files
I've found that with particularly large PDFs, this script will fail. I think it's a matter of choosing a lower-level Ruby HTTP library and configuring settings so that it keeps a persistent connection while awaiting the server's response. I may revisit this issue in a later update to this chapter
FEC Image Reports: The entire enchilada
The purpose of this chapter is to give you real-world examples of how to put together a scraper that can navigate a multi-level website. So this next section is just a combination of all the concepts and code we've covered so far.
Caveats
- As previously mentioned, this script does not (yet) consistently handle the dynamically-generated PDFs. I'm guessing there's just some lower-level configuration that I need to do. You'll see error messages in the output.
- This script some basic error-handling so that it doesn't die when encountering the above situation.
- Some regular expressions are used to extract committee and filing IDs
- The sample script looks at only 5 possible committees in the search results and 5 documents from each. You can easily take out the first...shuffle collection methods if you want to do a full iteration.
The structure
I've broken the code down into four pieces: the first three are custom methods that handle downloading and parsing the pages. The fourth is a main loop that invokes all of these methods and handles saving the files/pages to disk.
Note: I use a Ruby construct called a Module to namespace the method names. This is something I cover in brief in the object-oriented programming chapter. But there's nothing to it beyond just organizing the methods inside a wrapper.
Here it is, step-by-step:
Refer back to previous sections on inspecting the search page's POST request.
| Preconditions | Take in a partial search term, such as "Obama" |
| What it does | Submits a POST request to cgi-bin/fecimg with the name parameter set to "Obama" |
| What it returns | A hash containing the raw HTML of the search results and a collection of Nokogiri-wrapped links that lead to committee pages. |
The code:
module FECImages
def FECImages.search(name_term)
# prereqs: A partial search term (name_term) by which to find committees
# does: Submits a POST request to /cgi-bin/fecimg with the given `name` parameter
# returns: A Hash object containing:
# 'page'=> the raw HTML of the results page
# 'links'=> the Nokogiri::XML::Elements for each link to a committee page
request_url = "http://query.nictusa.com/cgi-bin/fecimg"
if page = RestClient.post(request_url, {'name'=>name_term, 'submit'=>'Get+Listing'})
puts "\tFECImages.search::\tSuccess finding search term: #{name_term}"
npage = Nokogiri::HTML(page)
links = npage.css('div#fec_mainContent table tr td a')
return {'page'=>page, 'links'=>links}
end
end
endRefer back to the previous section on the committees list page
| Preconditions | Takes in a URL that follows the format for committee page URLs. |
| What it does | A simple GET request for the page at that URL |
| What it returns | A hash containing the raw HTML of the search results and a collection of Nokogiri-wrapped links for each PDF report |
The code:
module FECImages
def FECImages.get_filings_list(committee_url)
# prereqs: `committee_url` goes to a committee page and follows this format:
# => http://query.nictusa.com/cgi-bin/fecimg/?COMMITTEE_CODE
# does: Retreives the page at `committee_url` and parses the HTML for links
# returns: A Hash object containing:
# 'page'=> the raw HTML of the filings page
# 'links'=> the Nokogiri::XML::Elements for each link to each PDF report
c_url_format = 'http://query.nictusa.com/cgi-bin/fecimg/?'
if !(committee_url.match(c_url_format))
# Raise an error:
raise "\tFECImages.get_filings_list::\tIncorrect committee url: #{committee_url} does not look like: #{c_url_format}"
end
begin
page = RestClient.get(committee_url)
rescue StandardError=>e
puts "\tFECImages.get_filings_list::\tCould not retrieve filings; Error: #{e}"
return nil
else
puts "\tFECImages.get_filings_list::\tSuccess in retrieving filings from #{committee_url}"
npage = Nokogiri::HTML(page)
links = npage.css('div#fec_mainContent table tr td a').select{|a| a.text.match('PDF')}
return {'page'=>page, 'links'=>links}
end
end
endRefer back to the previous sections on the filings list page and how to "push a button"
| Preconditions | A URL for a PDF that follows one of two formats: 1) An actual .pdf file or 2) a GET request to /cgi-bin/fecimg/ |
| What it does | If case #1, then just download the actual PDF file. If case #2, then retrieve the page at the URL (it's the one that contains the Generate PDF button). Parse that page to find the parameters for the POST request, submit the POST request, and then download the dynamically-generated PDF. |
| What it returns | File object containing binary data for PDF |
module FECImages
def FECImages.get_filing_pdf(pdf_url)
# prereqs: `pdf_url` follows either of the two formats:
# 1. http://query.nictusa.com/pdf/000/0000000/00000000.pdf#navpanes=0
# 2. http://query.nictusa.com/cgi-bin/fecimg/?XXXXXXXXXX
# does: if case #1, then retrieve PDF file
# if case #2, then retrieve "Generate PDF" page. Then generate the proper
# POST request. Then download dynamically generated PDF
# returns: File object containing binary data for PDF
# caution: this currently does not handle large PDF requests and will return nil
# if the server returns an error
# using a regular expression for validation
case_1_fmt = /query.nictusa.com\/pdf\/.+?\.pdf/
case_2_fmt = 'query.nictusa.com/cgi-bin/fecimg/'
pdf_file = nil
begin # sloppy (but good enough for now) error-handling
if pdf_url.match(case_1_fmt)
puts "\tFECImages.get_filing_pdf::\tDownloading actual PDF file: #{pdf_url}"
pdf_file = RestClient.get(pdf_url)
elsif pdf_url.match(case_2_fmt)
puts "\tFECImages.get_filing_pdf::\tRetrieving Generate PDF button page: #{pdf_url}"
if form_page = Nokogiri::HTML(RestClient.get(pdf_url))
button = form_page.css('input[type="hidden"]')[0]
data_hash = {button['name']=>button['value'], 'PDF'=>'Generate+PDF'}
# POST request
cgi_url = 'http://query.nictusa.com/cgi-bin/fecgifpdf/'
puts "\tFECImages.get_filing_pdf::\tSubmitting POST request: \t#{cgi_url}\t#{data_hash.inspect} ..."
pdf_resp = RestClient.post(cgi_url,data_hash)
if embed = Nokogiri::HTML(pdf_resp).css('embed')[0]
pdf_name = embed['src']
puts "\tFECImages.get_filing_pdf::\tPDF dynamically generated: #{pdf_name}"
pdf_file = RestClient.get(pdf_name)
end
end
else
raise "\tFECImages.get_filing_pdf::\tIncorrect PDF url: #{pdf_url} does not look like: #{case_1_fmt} or #{case_2_fmt}"
end
rescue StandardError=>e
puts "\tFECImages.get_filing_pdf::\tCould not retrieve PDF; Error: #{e}"
ensure
return pdf_file
end
end
endThe previous 3 code snippets were self-contained methods. This step involves writing a loop that calls these methods in appropriate order and passing the appropriate parameters to each successive step. The actual file-saving-to-disk happens here, too.
| Preconditions | Sets up variables, including the local directory to save the files and the desired search term. Also includes the module FECImages (require 'fecimg-module'), which contains the three methods for parsing. |
| What it does |
Calls each of the three previous methods. The first two return collections of links that need to be iterated through. The third method, FECImages.get_filing_pdf, returns PDF files which are to be saved to disk. |
| What it returns | Nothing. It is the main loop. |
require 'rubygems'
require 'restclient'
require 'nokogiri'
require 'fileutils'
require 'fecimg-module'
HOST_URL = 'http://query.nictusa.com'
term = "obama"
links_limit = 5
puts "Starting scrape for committees that match `#{term}`"
results_committee_listing = FECImages.search(term)
####### Save the results listing for `term`
results_local_dir = "data-hold/#{term}"
FileUtils.makedirs(results_local_dir)
File.open("#{results_local_dir}/committees_listing.html", 'w'){|f| f.write(results_committee_listing['page'])}
results_committee_listing['links'].to_a.shuffle.first(links_limit).each do |committee_link|
c_name = committee_link.text
c_href = "#{HOST_URL}#{committee_link['href']}"
puts "Retrieving filings for committee: #{c_name}"
if results_filings_listing = FECImages.get_filings_list(c_href)
puts "#{results_filings_listing['links'].length} filings found"
####### Save the filings listing for `c_name`
filings_listing_dir = "#{results_local_dir}/#{c_name}"
FileUtils.makedirs(filings_listing_dir)
File.open("#{filings_listing_dir}/filings_listing.html", 'w'){|f| f.write(results_filings_listing['page'])}
####### Now get all the PDFs
results_filings_listing['links'].to_a.shuffle.first(links_limit).each do |pdf_link|
# get the filing id: this regex should always work if the link is of correct format
pdf_href = "#{HOST_URL}#{pdf_link['href']}"
f_id = pdf_link['href'].split('/')[-1].match(/(\w+)(?:\.pdf)?/i)[1]
puts "Retrieving PDF at #{pdf_href}"
sleep(1.0 + rand)
####### Save PDF
if pdf_file = FECImages.get_filing_pdf(pdf_href)
File.open("#{filings_listing_dir}/#{f_id}.pdf", 'w'){|f| f.write(pdf_file)}
else
puts "* FAILED to get filing #{f_id}"
end
end
else # get_filings_list failed
puts "* FAILED to get filings for committee: #{c_name}"
end
endThe output
Here are the files collected:
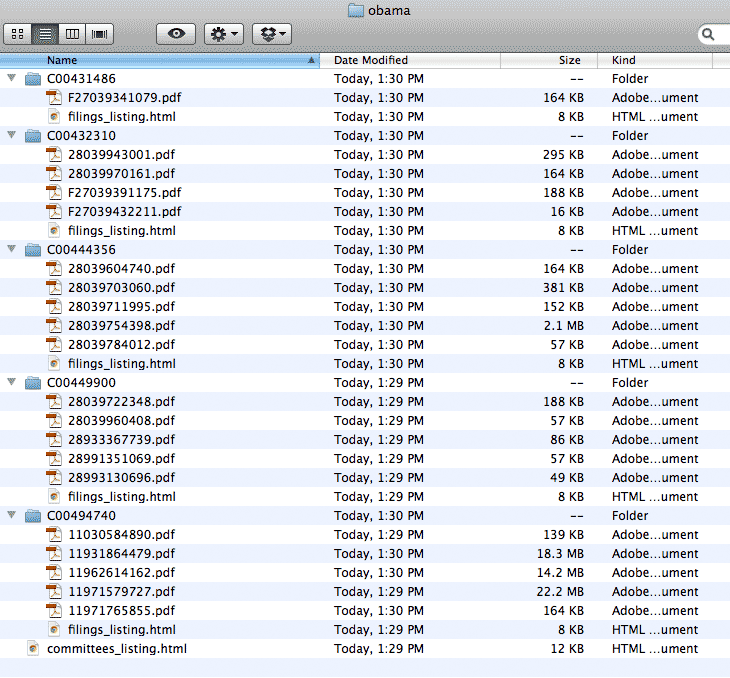
Here is the output of the program
Starting scrape for committees that match `obama`
FECImages.search:: Success finding search term: obama
Retrieving filings for committee: C00449900
FECImages.get_filings_list:: Success in retrieving filings from http://query.nictusa.com/cgi-bin/fecimg/?C00449900
5 filings found
Retrieving PDF at http://query.nictusa.com/pdf/408/28039960408/28039960408.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/408/28039960408/28039960408.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/pdf/696/28993130696/28993130696.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/696/28993130696/28993130696.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/pdf/348/28039722348/28039722348.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/348/28039722348/28039722348.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/pdf/069/28991351069/28991351069.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/069/28991351069/28991351069.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/pdf/739/28933367739/28933367739.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/739/28933367739/28933367739.pdf#navpanes=0
Retrieving filings for committee: C00494740
FECImages.get_filings_list:: Success in retrieving filings from http://query.nictusa.com/cgi-bin/fecimg/?C00494740
5 filings found
Retrieving PDF at http://query.nictusa.com/pdf/727/11971579727/11971579727.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/727/11971579727/11971579727.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/pdf/890/11030584890/11030584890.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/890/11030584890/11030584890.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/pdf/162/11962614162/11962614162.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/162/11962614162/11962614162.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/pdf/855/11971765855/11971765855.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/855/11971765855/11971765855.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/pdf/479/11931864479/11931864479.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/479/11931864479/11931864479.pdf#navpanes=0
Retrieving filings for committee: C00432310
FECImages.get_filings_list:: Success in retrieving filings from http://query.nictusa.com/cgi-bin/fecimg/?C00432310
5 filings found
Retrieving PDF at http://query.nictusa.com/pdf/161/28039970161/28039970161.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/161/28039970161/28039970161.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/cgi-bin/fecimg/?F27039450448
FECImages.get_filing_pdf:: Retrieving Generate PDF button page: http://query.nictusa.com/cgi-bin/fecimg/?F27039450448
FECImages.get_filing_pdf:: Submitting POST request: http://query.nictusa.com/cgi-bin/fecgifpdf/ {"PDF"=>"Generate+PDF", "27039450448+2+0"=>"S+478+697420439+34350+478+697454789+4871"} ...
FECImages.get_filing_pdf:: Could not retrieve PDF; Error: 500 Internal Server Error
* FAILED to get filing F27039450448
Retrieving PDF at http://query.nictusa.com/cgi-bin/fecimg/?F27039391175
FECImages.get_filing_pdf:: Retrieving Generate PDF button page: http://query.nictusa.com/cgi-bin/fecimg/?F27039391175
FECImages.get_filing_pdf:: Submitting POST request: http://query.nictusa.com/cgi-bin/fecgifpdf/ {"27039391175+5+0"=>"S+462+520087717+45345+462+520133062+39429+462+520172491+39068+462+520211559+22793+462+520234352+28315", "PDF"=>"Generate+PDF"} ...
FECImages.get_filing_pdf:: PDF dynamically generated: http://images.nictusa.com/dataout/showpdf/10484/10484.pdf#zoom=fit&navpanes=0
Retrieving PDF at http://query.nictusa.com/pdf/001/28039943001/28039943001.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/001/28039943001/28039943001.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/cgi-bin/fecimg/?F27039432211
FECImages.get_filing_pdf:: Retrieving Generate PDF button page: http://query.nictusa.com/cgi-bin/fecimg/?F27039432211
FECImages.get_filing_pdf:: Submitting POST request: http://query.nictusa.com/cgi-bin/fecgifpdf/ {"27039432211+1+0"=>"S+470+746601176+12721", "PDF"=>"Generate+PDF"} ...
FECImages.get_filing_pdf:: PDF dynamically generated: http://images.nictusa.com/dataout/showpdf/10672/10672.pdf#zoom=fit&navpanes=0
Retrieving filings for committee: C00431486
FECImages.get_filings_list:: Success in retrieving filings from http://query.nictusa.com/cgi-bin/fecimg/?C00431486
4 filings found
Retrieving PDF at http://query.nictusa.com/cgi-bin/fecimg/?F27039341079
FECImages.get_filing_pdf:: Retrieving Generate PDF button page: http://query.nictusa.com/cgi-bin/fecimg/?F27039341079
FECImages.get_filing_pdf:: Submitting POST request: http://query.nictusa.com/cgi-bin/fecgifpdf/ {"27039341079+5+0"=>"S+453+886582929+45915+453+886628844+35953+453+886664797+27136+453+886691933+16077+453+886708010+40767", "PDF"=>"Generate+PDF"} ...
FECImages.get_filing_pdf:: PDF dynamically generated: http://images.nictusa.com/dataout/showpdf/10745/10745.pdf#zoom=fit&navpanes=0
Retrieving PDF at http://query.nictusa.com/cgi-bin/fecimg/?F27039450450
FECImages.get_filing_pdf:: Retrieving Generate PDF button page: http://query.nictusa.com/cgi-bin/fecimg/?F27039450450
FECImages.get_filing_pdf:: Submitting POST request: http://query.nictusa.com/cgi-bin/fecgifpdf/ {"PDF"=>"Generate+PDF", "27039450450+2+0"=>"S+478+697459660+33430+478+697493090+4676"} ...
FECImages.get_filing_pdf:: Could not retrieve PDF; Error: 500 Internal Server Error
* FAILED to get filing F27039450450
Retrieving PDF at http://query.nictusa.com/cgi-bin/fecimg/?F27039432501
FECImages.get_filing_pdf:: Retrieving Generate PDF button page: http://query.nictusa.com/cgi-bin/fecimg/?F27039432501
FECImages.get_filing_pdf:: Submitting POST request: http://query.nictusa.com/cgi-bin/fecgifpdf/ {"PDF"=>"Generate+PDF", "27039432501+14+0"=>"S+470+753301665+22767+470+753324432+38119+470+753362551+26431+470+753388982+26907+470+753415889+41150+470+753457039+19498+470+753476537+36300+470+753512837+39206+470+753552043+34663+470+753586706+31553+470+753618259+23284+470+753641543+24437+470+753665980+7761+470+753673741+27624"} ...
FECImages.get_filing_pdf:: Could not retrieve PDF; Error: 500 Internal Server Error
* FAILED to get filing F27039432501
Retrieving PDF at http://query.nictusa.com/cgi-bin/fecimg/?F27039432437
FECImages.get_filing_pdf:: Retrieving Generate PDF button page: http://query.nictusa.com/cgi-bin/fecimg/?F27039432437
FECImages.get_filing_pdf:: Submitting POST request: http://query.nictusa.com/cgi-bin/fecgifpdf/ {"PDF"=>"Generate+PDF", "27039432437+6+0"=>"S+470+751658129+33598+470+751691727+21728+470+751713455+26706+470+751740161+30813+470+751770974+15272+470+751786246+27884"} ...
FECImages.get_filing_pdf:: Could not retrieve PDF; Error: 500 Internal Server Error
* FAILED to get filing F27039432437
Retrieving filings for committee: C00444356
FECImages.get_filings_list:: Success in retrieving filings from http://query.nictusa.com/cgi-bin/fecimg/?C00444356
5 filings found
Retrieving PDF at http://query.nictusa.com/pdf/060/28039703060/28039703060.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/060/28039703060/28039703060.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/pdf/398/28039754398/28039754398.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/398/28039754398/28039754398.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/pdf/012/28039784012/28039784012.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/012/28039784012/28039784012.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/pdf/995/28039711995/28039711995.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/995/28039711995/28039711995.pdf#navpanes=0
Retrieving PDF at http://query.nictusa.com/pdf/740/28039604740/28039604740.pdf#navpanes=0
FECImages.get_filing_pdf:: Downloading actual PDF file: http://query.nictusa.com/pdf/740/28039604740/28039604740.pdf#navpanes=0
A word about program organization
There are some design concepts here that we haven't previously covered, most notably the use of modules to namespace methods (covered in more detail in the object-oriented concepts chapter). There's no reason that I couldn't have defined my methods without them. The table below compares the two styles:
| using a module and namespacing | no module |
|---|---|
Definition
|
Definition
|
Invocation
|
Invocation
|
I chose to separate all the code into two files: one for the main loop and one ("fecimg-module.rb") that contains the module and method definitions. The file with the main loop has to require the other file.
What's the point of all this extra setup? Solely for the sake of keeping things clean. For complex projects, keeping everything in a giant code file can slow you down because you're constantly scanning for where you put what code.
Keeping separate files and using require cuts down on that constant searching. It also helps to emphasize a design pattern of encapsulation, in which methods are self-contained black boxes that do not need to be aware of each others' implementation details. Each method need only worry about its own preconditions and expected return values.
Likewise, the main loop doesn't need to be aware of how each method does its job. It just needs to know what each method takes in and returns. In fact, in the .rb file that contains the main execution loop, we shouldn't even have to require "rubygems", "restclient", or "nokogiri". Only the methods inside the FECImages module need those, so the require statements can be put there.
This example isn't a perfect example of encapsulation. But this is a relatively small project so I let myself be a little sloppy.
Use the Mechanize gem
The Mechanize gem provides an even higher-level abstraction of the HTTP transfer process. It uses Nokogiri for parsing and makes all the form manipulation pretty easy. I like it because it does away most of the annoying web inspecting work and handles some of the more complicated browser-like behavior, such as cookies and authentication. There are some sites that I have not been able to scrape without using Mechanize.
The following example shows how to programmatically submit a search term to Wikipedia's frontpage search box:
require 'rubygems'
require 'mechanize'
a = Mechanize.new { |agent|
agent.user_agent_alias = 'Mac Safari'
}
a.get('http://en.wikipedia.org/') do |page|
search_result = page.form_with(:id => 'searchform'){ |frm|
frm.search = 'U.S.'
}.submit
puts search_result.parser.css('h1').text
end
#=> United States
So why didn't we just use Mechanize from the start? It's such a high-level library that if you don't know how the web works, you won't learn anything by using Mechanize. I felt it was important to introduce you to the basics of how the web works. Also, Mechanize has more features than needed for basic web-scraping. But it's quite possible to use the Mechanize gem for all of your web-crawling needs.
I have begin writing a draft chapter on Mechanize. I use Mechanize for the California Common Surgeries scrape and for scraping the Putnam County Sheriff's jail logs.
Unscrapable sites
This section to be expanded upon later.
Not every website is scrapable with Nokogiri and network traffic examination. Sites that have all of their data and assets wrapped up in a self-contained Flash SWF, for example, have no HTML to scrape or data requests to intercept.
However, if you can see it, you can scrape it. It's just a question of how much effort you want to put into it. For a site that was using FlashPaper (essentially a PDF that acts as a Flash container) to display a spreadsheet, I jury-rigged a script that used RMagick (a Ruby gem that uses the ImageMagick graphics library) and Tesseract, an open-source OCR program, to use the spreadsheet's lines as delimiters. It wasn't fast, but it was still faster than manually copying 5,000 spreadsheet rows (it turned out to be unnecessary, as the company later distributed their data as normal PDFs).
Note: If you're building a website and think that wrapping data in a closed-format will be a safeguard, keep in mind that there is a tradeoff in that that data will be very difficult for you to edit without continuing to pay the developer a fee. Case in point: the many restaurant sites with outdated online menus and hours.
Captchas
Wikipedia has a good rundown of the various methods used to bypass captchas. Some of the rudimentary ones are probably within an average and determined programmer's ability to crack. However, if a website has implemented any kind of captchas period, it's worth asking yourself whether there are other means to get the data, such as through a public records request.
Terms and conditions
Many sites that use a captchas or other measures are probably commercial sites that do not allow web scraping. This guide does not condone breaking a site's terms of use. Furthermore, sites that are rich targets for scraping generally have systems in place to block scrapers.
Poking around
When you do enough web-scraping, you'll barely have to think about what approach to take when encountering a new website. The important part is that it is not a matter of memorizing steps, but understanding the reasons for why websites display and submit data. That is the approach I'm aiming for in this book's series of chapters on web-scraping.
Actually building a website will also give you insight to the process.
Once you understand the basics of how the web works, then it is just a matter of curiosity. What exactly is in the raw HTML? What happens if I submit nothing where the website asks for a partial name: will it return the entire list?
As I update this chapter with more examples, I will point out the times where simple guesswork helped me write the appropriate scraper.