
Note (Feb. 7, 2013): Regular expressions are such an important concept even outside the realm of programming that I've started work on a separate (small) book about them: It's free, and currently it's being distributed through the Leanpub publishing platform. It will incorporate all the concepts of this chapter with far more detail and useful exercises. Check it out while I take my very slow time in revamping the Ruby book. - Dan
Regular expressions are used to match patterns in text. And as utterly dry as that sounds, if you learn nothing else from this book, learn regular expressions. They don't require programming and they can be used right in your text editor.
I can't emphasize enough the indispensability of regular expressions. When I took computer science in college, regular expressions were just an optional chapter in the back of the textbook. I wish I had been forced to learn about them much, much earlier.
Regular expressions – regexes for short – aren't a programming fundamental, per se, because they can be used outside of a program. Here are the main reasons to get up to speed with regexes:
- They are the most useful text-related tool you can easily learn.
- They can be used without doing any programming.
- You will be using them throughout your programming career.
You've probably used your word processor's find-and-replace to do substitutions, such as:
Replace all occurrences of "NYC" with "New York City".
With a regular expression, you can do the same find-and-replace action but catch "N.Y.C", "N.Y.", "NY, NY", "nyc" and any other slight variations in spelling and capitalizations, all in one go.
That's the least you can do with a regular expression. In web development, regular expressions are used to detect if the email, phone number, city/state, etc. fields contain valid input. Likewise, they are extremely powerful for data cleaning.
Regexes involve a new syntax to memorize. But the good news is that regexes are ubiquitous. Once you know them, you can use them with any programming language or capable text-editor.
Try Regexes in Your Text Editor
You won't need the Ruby environment to get acquainted with regexes. Just open up either TextWrangler or SciTE; both editors support regexes when doing find-and-replace.
In this section, don't worry about figuring out the syntax. This is just a demonstration.
Add something to the beginning of each line
For your first regex, let's start off with a very simple example. Copy and paste the following text into your editor (there should be no spaces at the beginning of each line):
Mr. Ned Beatty Diana Christensen Mr. Max Schumacher Mr. Robert Duvall Mr. Frank Hackett Beatrice Straight Faye Dunaway Mr. Howard Beale Louise Schumacher Mr. William Holden Mr. Arthur Jensen Carolyn Krigbaum Cindy Grover Mr. Peter Finch
Open up your find-and-replace (Edit » Find/Replace or Ctrl/Cmd-F) and in the Find field, type in a single caret character:
^
In the Replace field, type in (note the space after the dot):
Ms.
There should be a checkbox with the option to use "Regular expression" or "Grep". Check it. Your text editor should something like this:
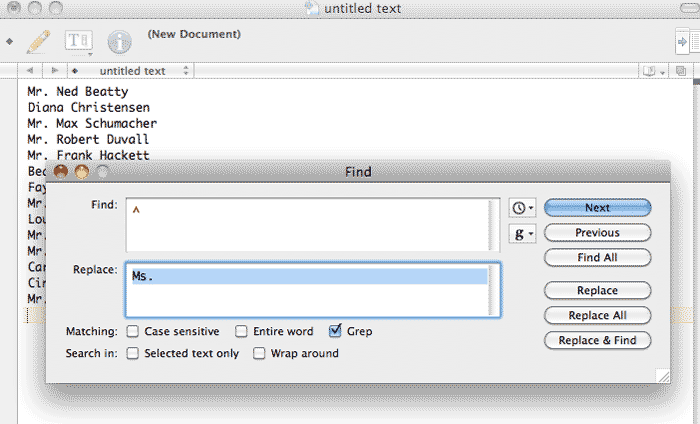
Now hit the Replace All button
Congratulations, you just ran a regular expression. The text-block should look like this:
Ms. Mr. Ned Beatty Ms. Diana Christensen Ms. Mr. Max Schumacher Ms. Mr. Robert Duvall Ms. Mr. Frank Hackett Ms. Beatrice Straight Ms. Faye Dunaway Ms. Mr. Howard Beale Ms. Louise Schumacher Ms. Mr. William Holden Ms. Mr. Arthur Jensen Ms. Carolyn Krigbaum Ms. Cindy Grover Ms. Mr. Peter Finch
Not quite what we want, but hey, we just did something that can't be done with your standard find-and-replace: insert something at the beginning of each line.
Now Undo what we just did and re-open the find-and-replace box. In the Find field, type:
^(?!Mr)
And in the Replace field, type:
Ms.
The Replace All operation should result in this:
Mr. Ned Beatty Ms. Diana Christensen Mr. Max Schumacher Mr. Robert Duvall Mr. Frank Hackett Ms. Beatrice Straight Ms. Faye Dunaway Mr. Howard Beale Ms. Louise Schumacher Mr. William Holden Mr. Arthur Jensen Ms. Carolyn Krigbaum Ms. Cindy Grover Mr. Peter Finch
That makes more sense. For the record, what we just did involved the negative-lookahead, a regex function that will only perform a substitution if the desired text to match-and-replace is not followed by a given pattern – in this case, Mr.
One more demonstration. Re-open the find-and-replace box and in the Find field, type:
(\w+) (\w+)
Notice that there is a leading whitespace at the beginning of the line.
In the Replace, type in:
\2, \1
Note: In some variations of the regex implementation, you might need to use a dollar-sign instead of a backslash, i.e:
$2, $1
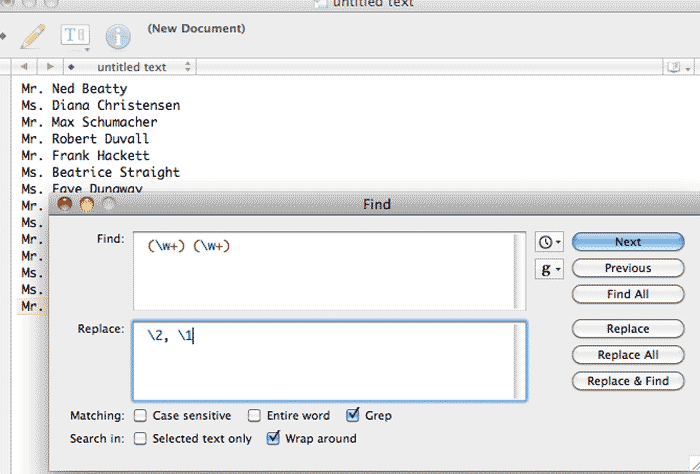
Note that the Find and Replace values both begin with a single whitespace. Doing a Replace All should result in:
Mr. Beatty, Ned Ms. Christensen, Diana Mr. Schumacher, Max Mr. Duvall, Robert Mr. Hackett, Frank Ms. Straight, Beatrice Ms. Dunaway, Faye Mr. Beale, Howard Ms. Schumacher, Louise Mr. Holden, William Mr. Jensen, Arthur Ms. Krigbaum, Carolyn Ms. Grover, Cindy Mr. Finch, Peter
This concludes a brief demonstration of how regular expressions work. Hopefully, you have an inkling of how these kinds of flexible patterns will help in actual real-world data problems.
Two key takeaways about regexes:
- At its most basic, a regex works just like a typical find-and-replace operation. There are characters represent their literal values. That is, if the pattern you want to match is simply: M then the regex is just M
- There are a few special characters, such as parentheses and carets and plus signs, that do not represent their literal values. Instead, serve a special function in a regex. Furthermore, the backslash character \ can turn a normal literal character, such as w, into a special regex character.
Introduction to regex syntax
Now that you've seen how regexes are used, let's slow down and learn some of the syntax.
Simple data cleaning
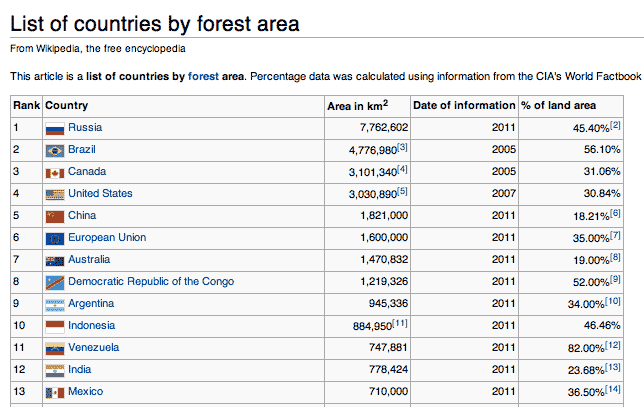
For the next few examples, I'll use data that I sloppily copied from this Wikipedia listing of countries by forest area.
Delete empty lines
I think everyone has had to do this at least once: you have a text file, and there's a bunch of annoying blank lines that shouldn't be there:
1 Russia 7,762,602 2011 45.40%[2]
2 Brazil 4,776,980[3] 2005 56.10%
3 Canada 3,101,340[4] 2005 31.06%
4 United States 3,030,890[5] 2007 30.84%
5 China 1,821,000 2011 18.21%[6]
6 European Union 1,600,000 2011 35.00%[7]
7 Australia 1,470,832 2011 19.00%[8]
8 Democratic Republic of the Congo 1,219,326 2011 52.00%[9]
9 Argentina 945,336 2011 34.00%[10]
10 Indonesia 884,950[11] 2011 46.46%
11 Venezuela 747,881 2011 82.00%[12]
12 India 778,424 2011 23.68%[13]
Here's a quick regex to clean that up:
^\s*\n
- ^
- The caret stands for the start of the line. It indicates that we are interested in a pattern from the very beginning of a given line. This is also referred to as an anchor.
- \s*
- The \s stands for any whitespace character. The asterisks * indicates that we are looking for 0 or more of these whitespaces. So the regex will work if there are no whitespaces or many whitespaces from the beginning of the line.
- \n
- This is a special character for a newline
The regex, in English, will match any line in which there is either nothing or just spaces/tabs from the beginning of the line to the line break (i.e. the end of the line). If you Replace it with nothing, all empty lines will be deleted:
1 Russia 7,762,602 2011 45.40%[2]
2 Brazil 4,776,980[3] 2005 56.10%
3 Canada 3,101,340[4] 2005 31.06%
4 United States 3,030,890[5] 2007 30.84%
5 China 1,821,000 2011 18.21%[6]
6 European Union 1,600,000 2011 35.00%[7]
7 Australia 1,470,832 2011 19.00%[8]
8 Democratic Republic of the Congo 1,219,326 2011 52.00%[9]
9 Argentina 945,336 2011 34.00%[10]
10 Indonesia 884,950[11] 2011 46.46%
11 Venezuela 747,881 2011 82.00%[12]
12 India 778,424 2011 23.68%[13]
Remove spaces from the beginning of the line
Let's make it so there isn't any leading whitespace at the start of each line. We only need the same components from the previous empty-line pattern:
^ +
- ^
- Again, this is the beginning-of-the-line anchor.
- The empty space is just a literal empty space. We could've also used \s
- +
- The plus +, known as the greedy operator, looks for one or more of the previous token, which in our example, is a whitespace.
This regex will look for one or more space characters from the beginning of the line. If you Replace that with nothing, then all leading whitespace will be deleted from the beginning of each line:
1 Russia 7,762,602 2011 45.40%[2] 2 Brazil 4,776,980[3] 2005 56.10% 3 Canada 3,101,340[4] 2005 31.06% 4 United States 3,030,890[5] 2007 30.84% 5 China 1,821,000 2011 18.21%[6] 6 European Union 1,600,000 2011 35.00%[7] 7 Australia 1,470,832 2011 19.00%[8] 8 Democratic Republic of the Congo 1,219,326 2011 52.00%[9] 9 Argentina 945,336 2011 34.00%[10] 10 Indonesia 884,950[11] 2011 46.46% 11 Venezuela 747,881 2011 82.00%[12] 12 India 778,424 2011 23.68%[13]
Remove bracketed numbers
When directly copying from Wikipedia, I also inadvertently copied the footnotes, which consists of numbers between brackets. These are only useful when looking at the actual webpage, so let's delete them. You can match them with this regex:
\[\d+\]
- \[
- Square brackets are a special character in regexes. But we don't want that special meaning. We just want a literal square bracket, so we escape it using a backslash \
- \d+
- The \d represents any numerical digit. Thus, when followed by the greedy operator +, the \d+ matches one or more numerical digits.
- \]
- This just matches the literal closing square bracket
Once again, putting that pattern as the thing to Find and entering nothing into the Replace field will result in all bracketed numbers being deleted from the text:
1 Russia 7,762,602 2011 45.40% 2 Brazil 4,776,980 2005 56.10% 3 Canada 3,101,340 2005 31.06% 4 United States 3,030,890 2007 30.84% 5 China 1,821,000 2011 18.21% 6 European Union 1,600,000 2011 35.00% 7 Australia 1,470,832 2011 19.00% 8 Democratic Republic of the Congo 1,219,326 2011 52.00% 9 Argentina 945,336 2011 34.00% 10 Indonesia 884,950 2011 46.46% 11 Venezuela 747,881 2011 82.00% 12 India 778,424 2011 23.68%
Now we're all cleaned up. If you paste the above result into Excel, Excel should recognize the tab characters and delimit accordingly:
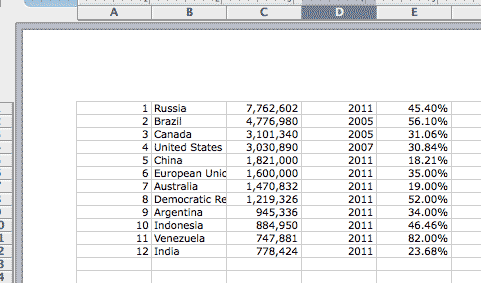
Exercise: Delete the first column of rankings
Working from the last text result, write a regular expression to remove the first column of numbers.
Solution
Find:
^\d+\s+
Replace:
[nothing]
The result:
Russia 7,762,602 2011 45.40% Brazil 4,776,980 2005 56.10% Canada 3,101,340 2005 31.06% United States 3,030,890 2007 30.84% China 1,821,000 2011 18.21% European Union 1,600,000 2011 35.00% Australia 1,470,832 2011 19.00% Democratic Republic of the Congo 1,219,326 2011 52.00% Argentina 945,336 2011 34.00% Indonesia 884,950 2011 46.46% Venezuela 747,881 2011 82.00% India 778,424 2011 23.68%
If you're an Excel expert, you might be shaking your head at this point because you can think of how you could've accomplished the same tasks in Excel. Maybe so, but those were just the very basics of regular expressions.
At one point, I think I could've done this cleaning in Excel. The advantage of regexes is that they are the same in every language and context (with a few variations in flavors) and will remain so. The Excel version that exists today, and its particular labyrinth of options, is quite different from the one I learned a few years ago.
Replacing misspelled words
The following exercises consists of how to use regex operators to match variations in spelling.
Copy and paste the following text into your editor:
Joe Smith takes care of they're property. The property of theirs includes their house, they're pool, and there dogs, of which Fido is their favorite.
There's a problem with the copy here. The writer used the wrong pronoun and meant "his" as opposed to "their". Even worse, "their" was misspelled as "they're" and its other homophones.
Open up your find-and-replace (Edit » Find/Replace or Ctrl/Cmd-F) and in the Find field, type in:
their|they're|there
Note that those are pipe-characters |, not lower-case L's. In the Replace field, enter:
his
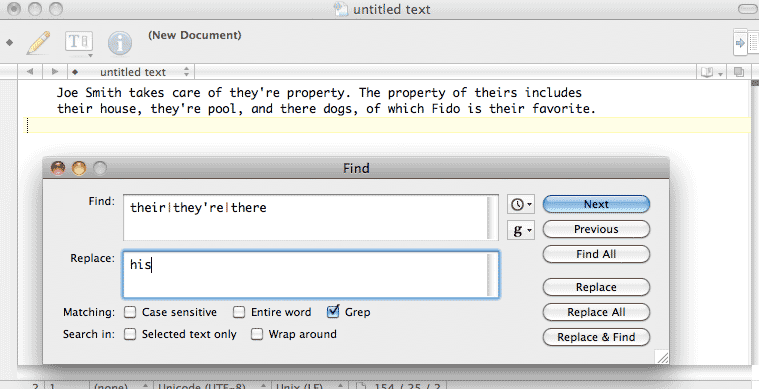
And then hit the Replace All button. The text-block should look like this:
Joe Smith takes care of his property. The property of hiss includes his house, his pool, and his dogs, of which Fido is his favorite.
In one operation, we replaced all the variations of "their" with "his". The regular expression we used – their|they're|there – includes all those variations and the use of the pipe character |
- The alphabetical letters are just treated as normal alphabetical letters. That is, their will match "their" in the text.
- The pipe character | takes on the special meaning of "OR".
So the regex we used could be read as: "their OR they're OR there".
However, our regex didn't quite finish the job: it replaced theirs with hiss.
The their in our regex only matches their – and thus, not the final s – in theirs. We can take care of that with a small alteration to our original regex, using the question mark ? operator .
Undo the previous changes to the text and run this regex:
theirs?|they're|there
That question mark ? is another special regex character. It makes optional the character that precedes it in the pattern – in this case, the s
In other words, either their or theirs will be matched by the regex.
It may seem that all this regex does is save us from doing find-and-replace three different times. We still had to type each variation in full. This is true. But we have yet to begin using the full power of regexes.
In the following expression, I take advantage of the fact that all three variations of their begin with the:
the(irs?|y're|re)
As you might guess, the parentheses change the order of operations (they also do something much more important than that, which we'll cover later). The alternation using the pipe character is solely among the latter sets of characters in the variations of "their", e.g. irs?, y're, and re (note that apostrophes are not special regex characters).
Rearranging date formats
The following is a list of dates in MONTH-DAY-YEAR format, i.e. "5/12/2010". Let's pretend that our dataset contains thousands of entries, making it a pain to fix these dates by hand.
3-10-2010
11-7-06
1-6-2007
4-14-08
7-10-2011
1-11-09
12-9-11
6-1-10
5-6-2009
Some of the years are in a two-digit format (09). We want to standardize them to four digits (2000).
How would you do this with your text-editor's find-and-replace function? Because each year begins with a hyphen, you probably would start with replacing every instance of -0 with -20. However, you miss all the years 2010 and greater, as those begin as -1.
However, if you try replacing -10 (or -11) with -20, you'll inadvertently affect the dates that have -10 as the day values, such as 7-10-2011.
Using regexes, we can gracefully fix this with a single find-and-replace action by targeting a pattern.
What pattern do we want to target? Any sequence of exactly two numerical digits at the end of each line.
Open up your editor's find-and-replace and in the Find box, type in:
-(\d{2})$
In the Replace box (your text editor's flavor of regexes may use a backslash \ instead of a dollar sign), type:
-20$1
And make sure you've checked the option to use "Regular expression" or "grep" before executing the find-and-replace operation.
Your list of dates should now have properly formatted years:
3-10-2010 11-7-2006 1-6-2007 4-14-2008 7-10-2011 1-11-2009 12-9-2011 6-1-2010 5-6-2009
How did this work? Let's break down the particular regex pattern we used in the Find box:
- -
- This is just a normal, i.e. literal, i.e. "non-special" hyphen, as we are trying to match the - that separates the day and year values.
- ()
- Parentheses are special regex characters that capture the pattern within them for later use (in the Replace field). In our current example, we want to use whatever the current year value is (e.g. 07 or 11) and prepend a 20 to it.
- \d
- A d would normally just match the letter "d". But with a backslash, this becomes a special regex character that matches any numerical digit.
- {2}
-
Curly braces allow you to specify the exact number of occurrences of the pattern preceding the braces. Therefore, the regex {2} will match whatever pattern precedes it exactly two times
Another example: the expression a{1,3} matches from 1 to 3 occurrences of the letter a.
Including a comma, but omitting the second number – e.g. a{3,} – will match three or more occurrences of the letter a.
In our example, we want a pattern of exactly two digits, because we don't want to modify the lines that already have four-year digits.
- $
- The dollar sign $ will match the end of the line. We use it in our dates example because we want only to match the last digits of each line. Otherwise, the regex would match the day values because they also begin with a hyphen (ex. 8-20-10).
Referring to captured groups
So now that we've covered the pattern we were trying to find, let's look at what we replaced it with:
20$1
The only thing special here is the $1 (again, your text editor may use backslashes instead of dollar signs, e.g. \1). Remember those parentheses we used in the Find pattern? The characters matched by the pattern they encompassed are considered a captured group. They can be retrieved for use – in this case, the Replace field – by using a dollar sign and the captured group's numerical order. .
We only had one set of parentheses, so $1 grabs the first (and only set). If we had used two sets of parentheses, $2 would retrieve the value between the second set of ()
Use a reference
As I wrote earlier, regular expressions constitute a whole new syntax to memorize. It can seem overwhelming at first. However, it is just a matter of memorization. On the whole, regexes are pretty straightforward to compose, even if they appear to be a long jumble of symbols.
In fact, I never took time to formally learn regexes. As soon as I understood what they were capable of, I printed a cheat sheet, taped it to the side of my computer, and referred to it when trying out regexes. You'd be surprised how often a regex can come up in a regular workday if your workday involves dealing with reading, parsing, or cleaning text.
As an online reference, I can't beat what's at regular-expressions.info, so bookmark and visit it frequently.
Exercise: Better find-and-replace
Let's do a quick exercise to review what we've covered so far.
In the following sample list of dates:
3-10-2010 11-7-2006 1-6-2007 4-14-2008 7-10-2011 1-11-2009 12-9-2011 6-1-2010 5-6-2009
Write the following regex patterns and replacements:
- Make the month field two-digits, so that 5-19-2011 is 05-9-2011
- Do the same for the day field.
-
Now that the dates are in MM-DD-YYYY format, change them to YYYY-MM-DD format. So 05-09-2011 should become 2011-05-09.
(This date format is commonly used in programming because sorting it alphabetically will also sort it chronologically.)
For the first step, you need to know that the caret character ^ is used to match the beginning of a line.
Solution
-
Find:
^(\d)-
This matches exactly one digit at the beginning of the line, followed by a hyphen,e.g. 3-18-2010.
Replace:
0$1-
-
Find:
-(\d)-
This matches exactly one digit in between two hyphens, e.g. 10-8-2010.
Replace:
-0$1-
-
Find:
(\d{2})-(\d{2})-(\d{4})This matches: exactly two digits, a hyphen, two more digits, another hyphen, and then four more digits.
Replace:
$3-$1-$2
Here's what the final list should look like:
2010-03-10
2006-11-07
2007-01-06
2008-04-14
2011-07-10
2009-01-11
2011-12-09
2010-06-01
2009-05-06
Ruby and regexes
Obviously, we want to use the power of regexes in our code, not just in our text-editor environment. Ruby provides a Regexp class and several handy methods. Mix these with scripting logic to make powerful data cleaning/searching tools.
The Regexp class
Regex patterns look like strings, but they have their own notation. Instead of quotation marks, regular expressions are bounded by the forward-slash character /:
my_regex = /cat/
puts my_regex.class # Regexp
puts my_regex == "cat" # false
The gsub method for strings
Substituting characters in strings is one of the most common uses for regexes in code. To do this, strings have the sub method, which is short for substitution.
The sub method takes in two arguments:
- either a String or a Regexp pattern
- a String to substitute in for the first time that the pattern (in the first argument) matches the invoking string.
puts "My cat eats catfood".sub("cat", "dog")
# => My dog eats catfood
If you passed in /cat/, you'd get the same result as above, as the letters cat match their literal values:
puts "My cat eats catfood".sub(/cat/, "dog")
# => My dog eats catfood
In most scenarios, we'll want to replace all occurrences of a pattern, not just the first one. So we use the gsub method, which is short for global substitution:
puts "My cat eats catfood".gsub("cat", "dog")
# => My dog eats dogfood
Once again, passing in the regexp /cat/ would net you the same result.
Let's try a more complicated string:
str="My cat goes catatonic when I concatenate his food with Muscat grapes"
puts str.gsub("cat", "dog")
# => My dog goes dogatonic when I condogenate his food with Musdog grapes
Here, matching just the literal string "cat" does us no good. We have to use a regex if we want to only replace "cat" as a standalone word.
Instead of using just "cat" as the matching pattern, try this regex pattern for word-boundaries: \b
The use of \b means that we are looking for a character that is not an alphabetical letter or an underscore. So to match all instances of just "cat" by itself:
str="My cat gets catatonic when I attempt to concatenate his food with Muscat grapes"
puts str.gsub(/\bcat\b/, 'dog')
=> My dog gets catatonic when I attempt to concatenate his food with Muscat grapes
String.match
The String methods match and scan are used when you not only want to target a pattern, but do something (besides substitution) with the matched string(s).
Here are two Department of Defense contracts announced in 1994. Let's assume they are among a large set of such contracts that have been read into a Ruby array:
contracts_arr =
["Hughes Missile Systems Company, Tucson, Arizona, is being awarded a $7,311,983 modification to a firm fixed price contract for the FY94 TOW missile production buy, total 368 TOW 2Bs. Work will be performed in Tucson, Arizona, and is expected to be completed by April 30, 1996. Of the total contract funds, $7,311,983 will expire at the end of the current fiscal year. This is a sole source contract initiated on January 14, 1991. The contracting activity is the U.S. Army Missile Command, Redstone Arsenal, Alabama (DAAH01-92-C-0260).",
"Conventional Munitions Systems, Incorporated, Tampa, Florida, is being awarded a $6,952,821 modification to a firm fixed price contract for Dragon Safety Circuits Installation and retrofit of Dragon I Missiles with Dragon II Warheads. Work will be performed in Woodberry, Arkansas (90%), and Titusville, Florida (10%), and is expected to be completed by May 31, 1996. Contract funds will not expire at the end of the current fiscal year. This is a sole source contract initiated on May 2, 1994. The contracting activity is the U.S. Army Missile Command, Redstone Arsenal, Alabama (DAAH01-94-C-S076)."]
Suppose from such a list of entries, we are interested in quickly finding each contract's dollar amounts. Using enumeration and match:
contracts_arr.each do |contract|
mtch = contract.match(/\$[\d,]+/)
puts mtch
end
#=> $7,311,983
#=> $6,952,821
So far, we've been familiarized with every component of that regex. The \$ matches a literal dollar sign. The [\d,] matches any character that is either a numerical digit or a comma.
The plus sign + may be new, or at least worth reviewing. This is the greedy operator and it will match the pattern that precedes it one or more times. Therefore:
[\d,]+
...will match any of the following strings:
12,000 42 912,345,200 ,,342134,,3,4,5
The greedy operator can obviously get you in trouble by being, well, too greedy. In the above example, how does it know when to stop?
Answer: When it comes across a character that is neither a digit or a comma. So, since each dollar amount in our example is surrounded by spaces, we're safe (if sloppy) here.
Exercise: Find the dates
Using the sample text and code snippet above, modify the code to print out the dates in each contract.
Hint: The special character \w can be used to match any alphanumeric character. Or if you want to be more precise in matching the month names, you can use a character set, such as [A-Za-z]
Solution
Luckily for us, in this small sample, the dates are all in a uniform format:
contracts_arr.each do |contract|
mtch = contract.match(/\w+ \d{1,2}, \d{4}/)
puts mtch
end
#=> April 30, 1996
#=> May 31, 1996
You'll note that this code only matched and found the first instances of the date pattern, even though each contract has several dates. I show several ways of dealing with this in the next sections.
The MatchData object
The object returned by match is a MatchData object, but for our purposes, it's very similar to a standard array. The first element contains the match When the regex includes capturing groups, the first element in the MatchData array-like object refers to the first capturing group, and so forth. If no matches are found in the string, then match returns nil.
Exercise: Delimit the dates
Repeat the mechanics of the previous exercise but modify the regex to use capturing groups and print out the dates delimited by month, day, and year.
Solution
contracts_arr.each do |contract|
mtch = contract.match(/(\w+) (\d{1,2}), (\d{4})/)
puts "Month: #{mtch[1]}"
puts "Day: #{mtch[2]}"
puts "Year: #{mtch[3]}"
puts ""
end
#=> Month: April
#=> Day: 30
#=> Year: 1996
#=> Month: May
#=> Day: 31
#=> Year: 1996
The contracts in our sample have several dates – for when the contract was awarded and for when the work is expected to be completed. We saw that match only returns the first instance it finds. Let's rewrite it so that it captures a few of the words that precede the date so that we can know the context. And to show how MatchData is like an array, the following code also prints the textual content and date with a delimiter:
contracts_arr.each do |contract|
mtch = contract.match(/\b(.{10,20}) (\w+ \d{1,2}, \d{4})/)
puts "#{mtch[1]} \t\t #{mtch[2]}"
end
#=> to be completed by April 30, 1996
#=> to be completed by May 31, 1996
The all-being dot
Of special note here is the dot character in the regex pattern. To find the text that precedes each date, we can't simply use \d and \w, as they would fail to match punctuation and whitespaces. For all we know, the group of characters preceding each date could have exclamation marks.
The dot character is the regex character to rule them all. It matches anything, with the exception of start and end of the line markers, and new lines (unless used with a modifier).
The combination of the be-all dot with some kind of repetition operator, such as the greedy plus sign, won't rip apart the time-space continuum. But it can lead to unwanted results. This is why in the above example, I limit it with the {10,20} so that the dot only looks for the first 10 to 10 preceding characters, whatever they may be (it is only luck that in this example, they happen to be " to be completed by")
The greedy dot
What if we wanted everything before the date, all the way to the beginning of the sentence? Then it's useful to combine the dot and the +:
.+(\w+ \d{1,2}, \d{4})
If you're wondering, "But won't those two capture everything?" Well, no, not necessarily. In the above expression, the .+, being the greedy bastard it is, has the tendency to gobble up as many characters as it can. However, it still must honor the requirement that the pattern ends with: \w+ \d{1,2}, \d{4}
So let's look at the first contract again. I've highlighted the two date patterns:
Hughes Missile Systems Company, Tucson, Arizona, is being awarded a $7,311,983 modification to a firm fixed price contract for the FY94 TOW missile production buy, total 368 TOW 2Bs. Work will be performed in Tucson, Arizona, and is expected to be completed by April 30, 1996. Of the total contract funds, $7,311,983 will expire at the end of the current fiscal year. This is a sole source contract initiated on January 14, 1991. The contracting activity is the U.S. Army Missile Command, Redstone Arsenal, Alabama (DAAH01-92-C-0260).
Remember how match captured only the first date match? If a greedy expression seeks to have everything it can, while still fulfilling the mininum requirements of the pattern, what is the most that it can grab here?
If you thought: "all the way up to January 14, 1991," you have the right idea. But you underestimated the greediness of the greedy dot. In fact, this is what the match will be:
y 14, 1991
Think about it for a second if the result confuses you. What is the bare minimum of characters that would satisfy the date pattern?
(\w+ \d{1,2}, \d{4})
The \w+ expression merely requires one or more alphanumeric characters, and then a single space. January would fit as a match.
However, so does the final y in January. That greedy dot bastard, of course, is going to prefer the latter situation. It will suck up all the letters of January up until the final y.
The lazy, greedy dot
Let's continue to personify our regular expressions. In the previous section, we dealt with a regex that consumed too much of the target string because of its greedy and indiscriminate nature.
The question mark operator adds the characteristic of laziness to a greedy pattern. We've already used the ? to designate that a pattern is optional to match, but it takes a different meaning when it comes after a +
first_contract = contracts_arr[0]
puts first_contract.match(/(.+)(\w+ \d{1,2}, \d{4})/)[2]
#=> y 14, 1991
puts first_contract.match(/(.+?)(\w+ \d{1,2}, \d{4})/)[1]
#=> April 30, 1996
So there are two differences in the resulting match from the lazy and greedy expression .+?: 1) it captured the whole date pattern, and 2) it captured the first date, April 30, 1996, rather than the latter.
What do you expect from something "lazy"? The regex wants to match a string that contains: an unspecified number of any characters and ends with something matching \w+ \d{1,2}, \d{4}. The greedy version wants every last character it can grab while meeting the latter condition, so of course it will take the latter date.
The lazy version, however, wants to grab the smallest part of the string that satisfies the pattern. So it stop at the the first of the dates. And, being lazy, it sees that it has fulfilled the first part of the overall expression (one or more of any character) it leaves the full April to the date-capturing group.
The uber-regex-reference site, regular-expressions.info, has a more thorough explanation.
Exercise: Capture date and currency
Observing that in the two sample contracts, the dollar amounts come before an occurrence of the date, write a regular expression that captures a dollar amount and a date and prints them to screen.
Solution
Use lazi-greediness to suck-up all the characters between the currency and the first date:
contracts_arr.each do |contract|
mtch = contract.match(/(\$[\d,]+).+?(\w+ \d{1,2}, \d{4})/)
puts "#{mtch[1]} \t\t #{mtch[2]}"
end
#=> $7,311,983 April 30, 1996
#=> $6,952,821 May 31, 1996
String.scan
If you want to be able to access all instances of a regex match, use scan instead of match. It returns an array of all matches in the target string:
locations = 'Alabama, AL, Alaska, AK, Arizona, AZ, Arkansas, AR, California, CA, Colorado, CO, Connecticut, CT, Delaware, DE, Florida, FL, Georgia, GA, South Dakota, SD'
puts locations.scan(/[A-Z]{2}/).join(', ')
#=> AL, AK, AZ, AR, CA, CO, CT, DE, FL, GA, SD
If your regex uses a capturing group, then scan will return an array of arrays:
locations = 'Alabama, AL, Alaska, AK, Arizona, AZ, Arkansas, AR, California, CA, Colorado, CO, Connecticut, CT, Delaware, DE, Florida, FL, Georgia, GA, South Dakota, SD'
locations.scan(/(\w[A-Za-z ]+), ([A-Z]{2})/).map{|loc| {:state=>loc[1], :city=>loc[0]} }
#=>
[{:state=>"AL", :city=>"Alabama"}, {:state=>"AK", :city=>"Alaska"}, {:state=>"AZ", :city=>"Arizona"}, {:state=>"AR", :city=>"Arkansas"}, {:state=>"CA", :city=>"California"}, {:state=>"CO", :city=>"Colorado"}, {:state=>"CT", :city=>"Connecticut"}, {:state=>"DE", :city=>"Delaware"}, {:state=>"FL", :city=>"Florida"}, {:state=>"GA", :city=>"Georgia"}, {:state=>"SD", :city=>"South Dakota"}]
The next exercise is incomplete. I'll get back to it when I figure out a better way to break down complicated regular expressions. I'm not sure the problem requires a complicated regular expression.
Exercise: Capture every proper noun in each entry
This exercise is open to interpretation and different answers. But to the best of your ability, write a script that iterates through each sample contract summary and prints out a list of the proper nouns that were in the summary.
We've already seen how to iterate and do matches by this point. The more interesting thinking involves what constitutes a proper noun, based on the sample text.
Solution
From the (tiny) sample text, I decided that the following characteristics would catch most of the proper nouns:
- The first character is a capitalized letter, preceded by 0 or more whitespaces and/or a non-alphanumeric character
- The next set of characters begins with an optional space and then consists of alphanumeric characters.
- A proper noun consists of one or more repetitions of the above pattern, for example: "New York" or "FY95 TOW"
The regex pattern I settled on was this:
(?:\s*\b([A-Z]+(?:\s*\w*)?)\b)+
It's not as complicated as it looks. But it doesn't work as well as I want it to. I will revisit this in a later update to this chapter.
For now, you can play around with this regex in a nifty interactive regex builder at gskinner.com. Click on this link to view my proposed pattern and what it would match in the sample text:
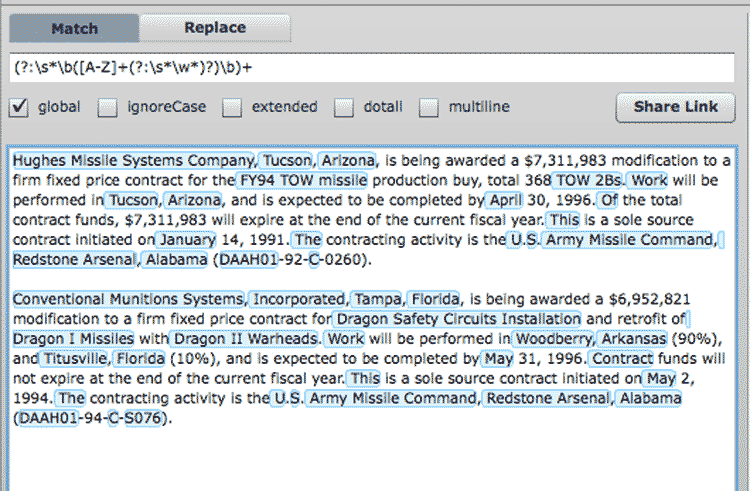
More regex patterns
At this point, I can only reiterate that becoming better at regexes is just a matter of having a reference guide and practicing. Go to regular-expressions.info, print out a cheat sheet and tape it to your monitor, and whenever you have a data-cleaning problem, attempt to do it with a regex instead of some more laborious solution.
It's the only way you'll get familiar with the syntax and become adept at it, and every minute of study will save you an hour of mind-numbing data-cleaning work in the future.
That said, I'm going to cover some common pattern examples to acquaint you with the syntax. It's up to you to practice and learn on your own time.
Collapse whitespace and convert line breaks into spaces
We learned early on that whitespace isn't particularly significant in Ruby. This is the same case for HTML, in which consecutive whitespace or linebreaks show up as just a single whitespace character.
However, when you scrape from webpages, you will be capturing all that whitespace. Sometimes you want to keep it. But if you don't want all those redundant characters, you can use a regex to collapse consecutive whitespace characters into one.
regex = /\s+/
puts " hello world
the space
is nice here! ".gsub(regex, ' ')
# => hello world the space is nice here!
Here's an explanation of those symbols:
- \s
- The backslash character with s is a pattern that captures all whitespace characters, including regular spaces, tab characters, and line breaks
- +
- The plus sign looks for a pattern that has one or more occurrences of the character preceding the +
So the script above looks for all occurrences within a string in which there is one or more whitespace characters and substitutes those with a single space. Thus, line break and tab characters are also reduced to a generic single space.
It's hard to see in the code example, but there is a single space surrounding the first and final non-whitespace characters. In many situations, you want to get rid of those. The string's strip method does that for us.
However, if you wanted to implement with a regex, you would use this pattern:
regex = /^\s+|\s+$/
puts " hello world ".gsub(regex, '')
# => hello world
Currency to number
When pulling in money-related data (payrolls, campaign finance expenditures, price listings, etc.) from a document or webpage, the dollar values will typically be in human readable format, e.g. $3,023,405.12 instead of 3023405.12
As we know, mixing up numbers with non-numeric symbols typically requires putting them into the String object. And programming languages in general will not let you add strings like numbers (e.g. "$12.00" + "$0.64" # = $12.00$0.64).
Here's a regex that will convert U.S. dollar amounts to decimal numbers:
regex = /[^\d\-.]/
puts "$156,200.98".gsub(regex, '').to_f # => 156200.98
Here's an explanation of those symbols:
- []
- Square brackets allow you to specify a set of characters to match. Read more at regular-expressions.info.
- ^
- The caret, when used inside [], acts as a negator. It signifies that we want to match the set of characters NOT defined within the brackets
- \d
- The backslash character with d represents all numerical digits. It's shorthand for [0-9], which can be read as: the set of characters from 0 through 9
- \-
- As we saw in the previous item, the hyphen is used to denote a range of characters in a bracket set. So, [f-z] would match all lowercase letters from f through z. But since I just want to match a plain hyphen (to capture negative values), I use the backslash to signify that I'm not using the hyphen as a special regex range character./dt>
- .
- The dot character is very powerful in regexes. It represents all characters. So, a pattern of .. would match everything from ab to ?* to two tab characters.
But, inside the bracket set notation, a dot is just a dot. Which is exactly what we want since we want to match decimal numbers.
So when viewed all together, you should see that we are looking to match all types of characters except for digits, decimal points, and the minus sign. Hence, the use of the square brackets [] and negation character ^.
This may seem counterintuitive until you see what method I use next: gsub. I'm matching all the non-numerical characters with the intention of replacing them with nothing, e.g. the empty string ''
And finally, I invoke the resulting string's to_f method to turn it into a proper Float. What happens if you called to_f on the string without first cutting out the non-numerical characters? Try it out:
puts "$156,200.98".to_f # => 0.0
puts "156,200.98".to_f # => 156.0
Essentially, the to_f method stops trying to convert characters to numbers upon the first non-numerical character. In the first line, it gives up at the $ sign, thus returning a value of 0.0.
Keep in mind that this pattern and method works well if all the currency strings are valid and follow the U.S. standard (i.e. empty spaces don't have significance). In many real-life situations, the challenge is to deal with input in which you have to detect invalid, human-entered values.
For example, a database may contain something like "$23,10". The regex I just demonstrated would convert it to 2310.0. But what if whoever made the typo meant the value to be "$23.10". Or "$23,100". When designing programs, you must consider the source of your information and plan for the mistakes he/she/it may have made, rather than just writing code that makes blithe assumptions.
Combining multi-line records
You asked an agency for some records. They give you a PDF. You convert it to text and what should be a nicely-ordered table like this:
| Name | Address | Street | Payment |
| Smith, John | 200 | Broadway | $1,000 |
| Jo, Sara | 1 | Main St. | $42 |
| Eisenhower, Dwight David | 90 | Dover Ave. | $140,591,495.00 |
Ends up converting to a mess like this:
Name Address Street Payment Smith, John 200 Broadway $1,000 Jo, Sara 1 Main St. $42 Eisenhower, Dwight David 90 Dover Ave. $140,591,495.00
Assuming that there is just one line break per field, we can use a regex that translates line breaks into commas and also puts double-quotes around each field so that you have a proper comma-delimited file.
We only do this for every four line breaks, which will preserve the fifth line break that separates each record as it should be:
regex = /(.+)\n(.+)\n(.+)\n(.+)/
puts str.gsub(regex, '"\1","\2","\3","\4"')
#=> "Name","Address","Street","Payment"
#=>"Smith, John","200","Broadway","$1,000"
#=>"Jo, Sara","1","Main St.","$42"
#=>"Eisenhower, Dwight David","90","Dover Ave.","$140,591,495.00"
Here's an explanation of those symbols:
- (.+)
- The all-encompassing dot character, combined with the greedy plus operator, will capture everything until the end of the line.
- \n
- This is the special escape sequence that represents a line break. However, this (annoyingly) is not the case across all platforms; read this Stack Overflow discussion for more details.
- \1
- We used parentheses in the pattern to save what we've captured. In the replacement sequence, using backslash and a number will refer to those captured groups in the numerical order that they appear in the pattern. So, \1 will refer to the first set of parentheses.
Compare that simple regex pattern to using a Ruby loop, sans regular expressions, to do the replacement:
newstr = ""
arr = nil
str.split("\n").each_with_index do |line, idx|
if idx%4==0
newstr << arr.map{|s| "\"#{s.chomp}\""}.join(',') + "\n" if arr
arr = [line]
else
arr << line
end
end
The more common situation is that the table conversion does not neatly result in one line break per field. Sometimes, particularly long fields will have an extra line break. So, instead of this:
Eisenhower, Dwight David 90 Dover Ave. $140,591,495.00
You end up with this mess:
Eisenhower,
Dwight David
90
Dover Ave.
$140,591,495.
00
So now you can't expect that every four lines constitutes a single record.
But, with a little more effort in your regex pattern, you can yet make order from this:
Note: I'm removing the headers line from str for reasons that I will explain later.
regex = /([A-Za-z, ]+)(\d+)([A-Za-z. ]+)(\$[\d,.]+)/
puts str.gsub(/\n/, '').gsub(regex, '"\1","\2","\3","\4"'+"\n")
#=> "Smith, John","200","Broadway","$1,000"
#=> "Jo, Sara","1","Main St.","$42"
#=> "Eisenhower, Dwight David","90","Dover Ave.","$140,591,495.00"
That regex looks like a doozy, but the general concept is that the four captured patterns are now more specific than .+
Here's a breakdown of each of the four captured groups:
- [A-Za-z, ]+
-
Since every record begins with a name, our first pattern captures every alphabetical letter. It also captures commas and spaces, since the name format is "LASTNAME, FIRSTNAME".
Remember that inside the square brackets, hyphens denote a range of characters, in this case, A-Z and a-z. No other kind of delimiter is needed inside []; every character and range specified in it will be captured in the pattern.
Finally, the greedy + operator will grab everything matched within the [] until it hits the next pattern.
- \d+
- The next field is the address number, which we assume to be only digits. Remember that the previous pattern looked only for alphabet letters. Once it reaches a number, the regex finishes with that group and moves onto the second, digits-only pattern.
- [A-Za-z. ]+
- The next field is the street name, which we assume will only consist of alphabet letters, spaces, and dots (e.g. "Ave."). Remember that a dot within square brackets is just a literal dot, not the regex symbol for any-character.
- \$[\d,.]+
- The previous pattern continues until it hits a dollar sign, which denotes the start of the payments field. This final pattern captures all digits, commas, and a decimal point.
If you looked closely at the code, you'll notice that we called gsub twice consecutively. The first time was to remove all line breaks:
str.gsub(/\n/, '')
Since line breaks are artificially thrown into the translated text, there's no reason to keep them. And since we have specific patterns for each field, the line breaks don't serve any kind of delimiting purpose (since it's possible that each field has been broken up into an unknown number of separate lines).
Now, there are a considerable number of caveats here. For example, the name field will likely be broader than what we specified, and we'll need to include hyphens (e.g. "Doe-Smith, Jane") and apostrophes (e.g. "O'Malley, Martin").
This pattern would be:
/([A-Za-z,'\- ]+)/
Note that the hyphen has to be escaped with a backslash for it to be a literal hyphen.
If you know that the name pattern will always be "LASTNAME, FIRSTNAME", then you should include the ", " as part of the pattern to make it even more discriminating. In fact, you may want to break it up into two captured groups, as it is always useful to have separate fields for first and last name:
The pattern for this would be:
/([A-Za-z'\- ]+), ([A-Za-z'\- ]+)/
Note that in the first captured group, that greedy + operator will gobble up everything until it hits that comma and a space. After that, it begins capturing for the second group.
For the above patterns to work, I removed the first headers row out of consideration because it consists of fields that were all alphabetical characters, which would gum up the regex matching.
The sample table I provided let us make easy assumptions. In real life, you can't assume that the street field will never have numbers, for example.
Luckily, there's way to make the patterns much more specific and complex to fit your needs (again, checkout regular-expressions.info). It can involve a bit of frustrating trial and error, but it sure beats sorting and cleaning thousands of fields by hand.
I wrote the following exercise but never quite finished it. It has cuss words and it reviews the basic syntax, so you still might find it useful.
Exercise: Write a language filter
Corralling the foul language on the Internets would be an excruciatingly tough job without the use of regular expressions, which give you the capability of catching undesirable words while not blocking out acceptable but similar words.
Working from the text provided below, write a filter that turns all instances and variations of "ass" into "a**" without obfuscating words like "pass".
Don't take my hall pass, you ass. - User 101, 7:40 AM
You are a total a$$-wipe - User 206, 7:45 AM
As I've said earlier, the document must be read assiduously in
order to assure quality - User 42 9:12 AM
You're an a55hole, kiss my ASS - User 101, 9:40 PM
Solution
Let's breakdown the problem.
Starting with the obvious, we want to catch at least "ass". What's the regex pattern for that? Easy (I'm going to bound the pattern with forward-slashes from here on out):
/ass/
The next lowest-hanging fruit would be variations in capitalization, e.g. "ASS", "Ass", "aSS". In Ruby, as well as in other languages, you can add a modifier to make the pattern case-insensitive with this syntax:
/ass/i
However, if you are just doing it in you text-editor, there should be an option to do a case-insensitive search.
If you apply this pattern to the sample text (you can do so with your text editor's find-and-replace, just don't include the forward slashes or the modifier i, as those are Ruby's way of denoting regex patterns), you'll see that the pattern is too vague. It modifies "pass" and "assure", for example.
To prevent this, we use the \b special character. This character matches word boundaries, such as whitespace and punctuation. By using \b, we specify that we don't want to match any occurrence of "ass" that precedes or follows alphabetical letters, such as "pass":
\bass\b
OK, now for the tougher part: How many ways can someone spell "ass" in such a way that doesn't use the exact characters yet still conveys the same meaning to the human brain? The letter 's' is often replaced with similar looking characters, such as 5 and $.
To catch these in our profanity filter, we use character sets. After the character 'a', we are looking to match two characters that could either be 's','5', '$' and any possible combination thereof. Character sets are denoted by square brackets and will match any of the characters inside them:
[s5$]
An important note: Inside the brackets, the normal regex syntax does not apply (I know, I sympathize with your groan). The dollar sign is typically a special regex character for end-of-line. Inside the brackets, though, it simply represents its literal value, '$'.
If we had wanted to represent a literal dollar sign outside of the brackets, we would need a backslash. Therefore, the above character set is equivalent to:
s|5|\$
However, we use character sets because they are more convenient. To specify that we want exactly two of these character sets, as we want to catch "a$$" and "as$", for example, we just repeat the character set:
\ba[s5$][s5$]\b
Kind of ugly, right? We can use the regex operator for repetition: curly braces and a number for how many repetitions of the previous character in the pattern:
/\ba[s5$]{2}\b/i
If we run this pattern, either a text-editor or in Ruby, this is how the sample text is transformed:
Don't take my hall pass, you ***. - User 101, 7:40 AM
You are a total ***-wipe - User 206, 7:45 AM
As I've said earlier, the document must be read assiduously in
order to assure quality - User 42 9:12 AM
You're an a55hole, kiss my *** - User 101, 9:40 PM
Not too bad. However, we didn't manage to grab the compound-use of the word because our regex uses the \b to restrict our matches to variations of "ass" that aren't part of a larger word. To get all the compound variations will require more fine-tuning, and then it becomes a question of how much of your time do you want to play Censor Cop?
Optional: The next part covers
For sh**s and giggles – and to learn about the highly useful lookahead operator – lets try to capture that instance of "a55hole".
First, let's breakdown the issue: what suffixes do we need to look out for? For sanity's sake, lets stick to the most obvious ones: "hole", "wipe", and "face". Using the alternation operator, we can tell the regex engine to match a set of possible patterns:
hole|wipe|face
Let's say we also want to catch all the possible substitutions, 0 for o and i and lower-case L and 1, for example. So mix in some character classes to get this:
(h[0o][il1]|w[i1l]p|fac)e
I used parentheses – which are normally used to capture groups – to limit the alternation operator to just the three three-character patterns. Since 'e' is the last character for all three patterns, I just have to include it once after grouping the alternate patterns (hol- and wip- and fac-) together.
And just to be even more complete, let's account for the possibility of a hyphen if the cuss word is compound:
-?
Putting all of this with the entire pattern so far, we get
\ba[s5$]{2}-?(\b|(h[0o][il1]|w[i1l]p|fac)e)
One more nitpicking detail. We use parentheses even though we aren't capturing any groups. To use parentheses solely for grouping, you add a question mark followed by a colon inside the parentheses, like so: (?:yourpattern). Therefore, our pattern should be (it doesn't matter, as we don't rely on captured groups anyway):
\ba[s5$]{2}-?(?:\b|(?:h[0o][il1]|w[i1l]p|fac)e)
And the result is:
Don't take my hall pass, you ***. - User 101, 7:40 AM You are a total ***wipe - User 206, 7:45 AM As I've said earlier, the document must be read assiduously in order to assure quality - User 42 9:12 AM You're an ***, kiss my *** - User 101, 9:40 PM
Get a cheat sheet
I could expand this chapter indefinitely with all the ways that regexes make life easier for data-scrounging. In fact, I'm considering making a Bastard's Book of Regexes. I hope this brief primer convinces you to at least try them out. Virtually every project this book undertakes will use regexes in some fashion.
Luckily, regexes don't require rigorous study. Print out this cheat sheet, bookmark regular-expressions.info, and keep them in mind anytime you ever have to clean messy data.
An aside: Regexes work great with my favorite data-cleaning tool, Google Refine. Here's a tutorial I wrote about using this supremely useful web-browser-based program.