Editor's note: This chapter is a leftover from a previous iteration of this book. However, I've left it in as the conclusion of the Fundamentals section. The code is a little clunky and boring but still relevant to what we've covered.
At the beginning of the Fundamentals section, I promised that you would learn enough Ruby to understand the tweet-fetching script.
Let's put the lessons to the test. You may even improve upon what I wrote.
The Code
Refer to the Twitter API docs for GET statuses/user_timeline for details on how things work on Twitter's end.
On our end, here's the full code, cruft and all. I'll break it down piece by piece.
require 'rubygems'
require 'restclient'
require 'crack'
# Twitter only allows you to go back 3,200 tweets for any given user
MAX_NUMBER_OF_TWEETS = 3200
# The maxmimum number of tweets you can get per request is 200
NUMBER_OF_TWEETS_PER_PAGE = 200
# Here is where we set the user whose tweets we want to get
TARGET_USERNAME = 'StephenAtHome'
# This is the directory where we want to store the tweet collection
DATA_DIRECTORY = "data-hold"
Dir.mkdir(DATA_DIRECTORY) unless File.exists?(DATA_DIRECTORY)
GET_USERINFO_URL = "http://api.twitter.com/1/users/show.xml?screen_name=#{TARGET_USERNAME}"
GET_STATUSES_URL = "http://api.twitter.com/1/statuses/user_timeline.xml?screen_name=#{TARGET_USERNAME}&trim_user=true&count=#{NUMBER_OF_TWEETS_PER_PAGE}&include_retweets=true&include_entities=true"
user_info = RestClient.get(GET_USERINFO_URL)
if user_info.code != 200
# Did not get a correct response from Twitter. Do nothing.
puts "Failed to get a correct response from Twitter.
Response code is: #{user_info.code}"
else
# successful response from Twitter
File.open("#{DATA_DIRECTORY}/userinfo-#{TARGET_USERNAME}.xml", 'w'){|ofile|
ofile.write(user_info.body)
}
# The total number of a user's tweets is the value
# in the "statuses_count" field
statuses_count = (Crack::XML.parse(user_info)['user']['statuses_count']).to_f
puts "#{TARGET_USERNAME} has #{statuses_count} status updates\n\n"
# Calculate the number of pages by dividing the user's
# number of Tweets (statuses_count) by the maximum number of past
# tweets that Twitter allows us to retrieve (max_number_of_tweets = 3200)
number_of_pages = ([MAX_NUMBER_OF_TWEETS, statuses_count].min/NUMBER_OF_TWEETS_PER_PAGE).ceil
puts "This script will iterate through #{number_of_pages} pages"
File.open("#{DATA_DIRECTORY}/tweets-#{TARGET_USERNAME}.xml", 'w'){ |outputfile_user_tweets|
(1..number_of_pages).each do |page_number|
tweets_page = RestClient.get("#{GET_STATUSES_URL}&page=#{page_number}")
puts "\t Fetching page #{page_number}"
if tweets_page.code == 200
outputfile_user_tweets.write(tweets_page.body)
puts "\t\tSuccess!"
else
puts "\t\t Failed. Response code: #{tweets_page.code}"
end
sleep 2 # pause for a couple seconds
end
} # closing outputfile_user_tweets File handle
end # end of if user_info...The output to screen will look like:
StephenAtHome has 1947.0 status updates
This script will iterate through 10 pages
Fetching page 1
Success!
Fetching page 2
Success!
Fetching page 3
Success!
Fetching page 4
Success!
Fetching page 5
Success!
Fetching page 6
Success!
Fetching page 7
Success!
Fetching page 8
Success!
Fetching page 9
Success!
Fetching page 10
Success!
Initializing gems and variables
The first lines include the gems rest-client and crack to give us methods for calling the Twitter API and parsing its response, respectively. (Chapter: Methods Part II)
(I've removed the comments and extraneous whitespace)
require 'rubygems'
require 'restclient'
require 'crack'
The next lines establish the constants:
- The maximum number of tweets that the Twitter API will return for any user is 3,200.
- Only 200 tweets will be returned per API call. You can increment the page parameter (documented in the Twitter API) to get to next 200 tweets.
- To keep things a little organized, we specify a directory on our hard drive (relative to where this script runs) to save the tweets to.
- And finally, a constant for the Twitter account name that we want to archive.
MAX_NUMBER_OF_TWEETS = 3200
NUMBER_OF_TWEETS_PER_PAGE = 200
DATA_DIRECTORY = "data-hold"
TARGET_USERNAME = 'StephenAtHome'
We use the Dir class to make DATA_DIRECTORY if it doesn't already exist.
Dir.mkdir(DATA_DIRECTORY) unless File.exists?(DATA_DIRECTORY)
Following Twitter's API
An API is basically a set of conventions established by a data-provider – Twitter, in this case – for a third-party – you – to efficiently request their services – a list of tweets.
We will be using two types of calls in the Twitter API: users/show to retrieve user info and statuses/user_timeline to retrieve a list of a user's tweets.
You can view the call to users/show in your web browser: http://api.twitter.com/1/users/show.xml?screen_name=StephenAtHome
We covered the basics of APIs in the Methods Part II chapter.
Initialize constants
Let's initialize constants for the URLs we'll use to call the Twitter API, with the appropriate parameters as required. We use string interpolation to insert the values for the account name and number of tweets.
GET_USERINFO_URL = "http://api.twitter.com/1/users/show.xml?screen_name=#{TARGET_USERNAME}"
GET_STATUSES_URL= "http://api.twitter.com/1/statuses/user_timeline.xml?screen_name=#{TARGET_USERNAME}&trim_user=true&count=#{NUMBER_OF_TWEETS_PER_PAGE}&include_retweets=true&include_entities=true"
GET with RestClient
Your web browser makes pulling up a webpage a one-click maneuver, hiding the complicated protocols needed for two computers to transfer data across the Internet.
The RubyGem rest-client performs this kind of abstraction and ease-of-use for our Ruby scripts as we covered in the Methods Part II chapter.
Getting users/show with RestClient.get
user_info = RestClient.get(GET_USERINFO_URL)
This is a request to the Twitter API's GET users/show call, which contains information about a user account, including number of followers and tweets.
The RestClient.get method returns a RestClient-wrapped data object that includes the content of Twitter's response, among other properties, as you can see in ( RestClient's docs)
Finding the HTTP status with code
To determine whether or not get was a success, we use the rest-client method named code, which returns the HTTP status code of the response.
200 means it was a nice, normal response. Other status codes don't necessarily mean failure, but if the response is other than 200, we should stop the script because something might have changed in Twitter's service.
if user_info.code != 200
puts "Failed to get a correct response from Twitter.
Response code is: #{user_info.code}"
Using File.open
We covered file reading and writing in the File Input/Output chapter
If we received a 200 success code, then we're good to go and can save the XML response as a file in DATA_DIRECTORY with a name based on TARGET_USERNAME.
We use the form of File.open that accepts a code block and automatically closes the opened file at the end. This saves us from having to call the close method.
else
File.open("#{DATA_DIRECTORY}/userinfo-#{TARGET_USERNAME}.xml", 'w'){ |ofile|
ofile.write(user_info.body)
}
The file referenced by ofile is closed when the script reaches the end of the block (denoted by the closing curly brace } )
Use crack to read the XML response
Here's what the XML response looks like for http://api.twitter.com/1/users/show.xml?screen_name=StephenAtHome
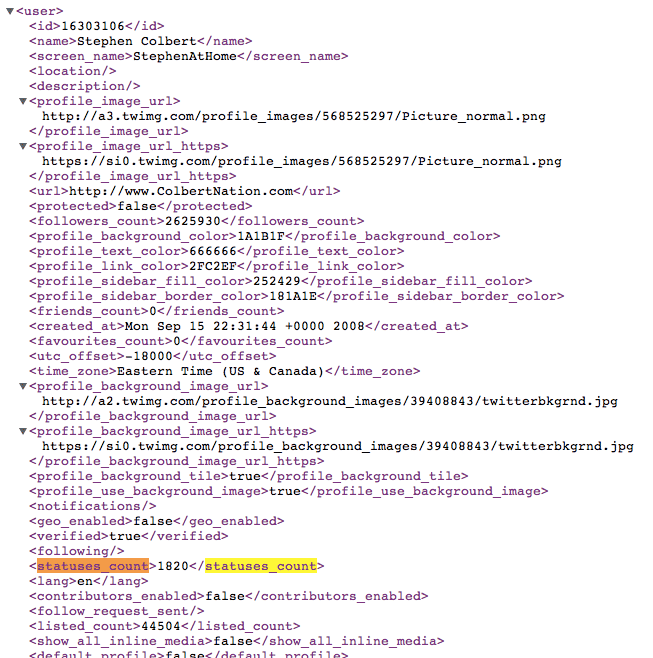
Hash and crack
I've highlighted what we're interested in: the statuses_count element, which itself is inside the user element. The crack gem turns an XML file into a Hash object, allowing us to grab the statuses_count value with bracket notation:
statuses_count = (Crack::XML.parse(user_info)['user']['statuses_count']).to_f
puts "#{TARGET_USERNAME} has #{statuses_count} status updates\n\n"
We store the number of tweets as indicated in XML file in the statuses_count variable. I also convert it to a decimal number with the to_f method, which will make sense in the next line.
Division and min
Basic math: if Twitter will return only the last 3,200 tweets of a user and 200 tweets per API call, then we need to make 16 (3200/12) calls. But if a user has made fewer than 3,200 tweets, then we might make fewer than 16 API calls.
So I put the two values – MAX_NUMBER_OF_TWEETS and the value in statuses_count – in an Array and use its min method to get the least of the two numbers.
number_of_pages = ([MAX_NUMBER_OF_TWEETS, statuses_count].min/NUMBER_OF_TWEETS_PER_PAGE).ceil
puts "This script will iterate through #{number_of_pages} pages"
The result of the min method – the lesser value among 3,200 and the total number of the user's tweets – is then divided by NUMBER_OF_TWEETS_PER_PAGE (200). If the user has made fewer than the maximum number of tweets that can be returned – and statuses_count is not evenly divisible by 200, then we get a decimal number that needs to be rounded up with the ceil method. If we hadn't converted statuses_count to a Float, we wouldn't get that partial number from the division operation (as we learned in the Numbers chapter)
For example, if the user has had only 500 tweets, 500/200 will return 2, as Ruby returns only an integer in an operation between two integers (i.e. Fixnum). Two calls only returns 400 tweets. We need a third call to get the final 100, so this is why we force Ruby – by converting one of the numbers in the division operation to a Float – to return a partial number that is rounded up with the method ceil
Request the Tweets, Repeat
The final code block has nothing unfamiliar. We just open a new textfile and for each page, we use RestClient.get to call Twitter's user_timeline service, getting 200 tweets at a time and writing to the just-opened textfile.
With each iteration, we use the sleep method to pause execution for 2 seconds. I've found that the Twitter API will sometimes refuse requests when they're made too quickly in succession:
File.open("#{DATA_DIRECTORY}/tweets-#{TARGET_USERNAME}.xml", 'w'){ |outputfile_user_tweets|
(1..number_of_pages).each do |page_number|
tweets_page = RestClient.get("#{GET_STATUSES_URL}&page=#{page_number}")
puts "\t Fetching page #{page_number}"
if tweets_page.code == 200
outputfile_user_tweets.write(tweets_page.body)
puts "\t\tSuccess!"
else
puts "\t\t Failed. Response code: #{tweets_page.code}"
end
sleep 2 # pause for a couple seconds
end
} # closing outputfile_user_tweets File handle
There's a gem for that
At this point, astute readers might have wondered: Accessing the Twitter API seems like a very common task...is there a gem for this?
Yes, in fact Ruby developers do contribute gems to simplify specific APIs. Here is one for Twitter: the appropriately named twitter gem, by John Nunemaker
It's up to you to decide whether it's easier to learn the specific conventions of someone else's gem or to use the more general-use gems, such as rest-client and crack. If you plan on doing a lot of work with Twitter, then learning the twitter gem may be worth your time. Another factor to consider is how well-maintained the gem is – which can partly be determined by the date of its last update.
I chose to access the Twitter API with rest-client and crack because we can use these gems for pretty much any other API.
Fundamentals and more
Congratulations on finishing the Fundamentals section of the book. As I mentioned in the introduction, this is my loose interpretation of the minimum amount of programming for a novice to grok before he/she can start doing writing some useful scripts.
But this is the minimum from my vantage as someone who studied computer engineering and does web development and data-gathering for a job. I have a decent grasp of what I use in my day-to-day work and what book-learned concepts I haven't used since my college finals.
However, the fundamentals that I've skipped for this book may be knowledge that is essential, but that I've taken for granted. So this section is still under development and while I revise and improve it, I encourage you to check out the many other programming guides (even in other languages) to fill in the gaps.
Moving on
One of my main motivations for writing this book was to show both experienced programmers and programers-in-training examples of data-related projects. The remainder of this book and the majority of its future additions will be devoted to these real-world comprehensive examples. I do some hand-holding in the beginning, but the projects have been written under the assumption that you've made an attempt to understand the fundamentals.
I use the verb "understand" rather than "master" because the best way to master programming is to practice it. The projects will hopefully help you become an experienced programmer. My hope is that by going through them, you'll also realize how much you've learned by persevering through the fundamentals.
There are a few other high-level concepts that aren't "fundamental", per se, but are essential to sanely accomplishing real-world programming tasks. These are covered in the Supplementals section.