
In the book's introduction, I described how I wrote a scraper for the local county jail's website so I could analyze the characteristics of the inmate population, including types of crime committed. But I recently checked and saw that the sheriff's website seems to have taken the online listing down.
However, many other jurisdictions keep such information online and public. For demonstration purposes, I've chosen the Putnam County Sheriff's Office (PCSO) of Florida, which keeps both a current listing and a three-year archive.
This project will use everything we covered in this book's four chapters on web-scraping. The search form uses POST parameters and a little session-tracking trick to make things difficult. Because life is short, I opted to use the Mechanize gem (briefly described in this chapter), which handles the submission form and its hidden variables.
Scraping with Mechanize
I'm making the data collected from the Putnam site available for download as a SQLite database. However I have set the birthdate days to 01 and truncated the first names. Yes, this is public information. But this is a programming lesson, not a live mirror of the sheriff's data and thus will not reflect any recent updates that the official site might make.
You can still follow along in the examples with the redacted version of the database. Email me if you're interested in using the data for research purposes.
As in previous scraping examples, we'll start out by downloading every page of data to the hard drive to parse later.
In the case of the Putnam County jail archive, there are two steps in the downloading phase:
- Download each list page. Each page lists links for 25 bookings. The list goes on for nearly 600 pages. There is no direct link to result pages, so we'll use the Mechanize gem to make the crawl easier.
- Download each booking page. The results pages include direct links to each booking page. The booking pages contain the details of the inmates' charges, bail and release date.
Scrape the history lists
The Putnam County jail archive can be accessed at this address: http://public.pcso.us/jail/history.aspx
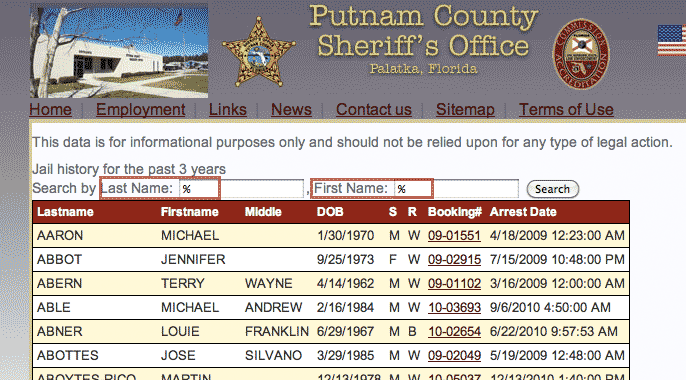
There are two search fields for first and last name. The functionality of the query is generous: if you enter % as a wildcard, you can return the entire archive (paginated with 25 entries per page).
At the bottom of each results page are links to the next 10 pages:
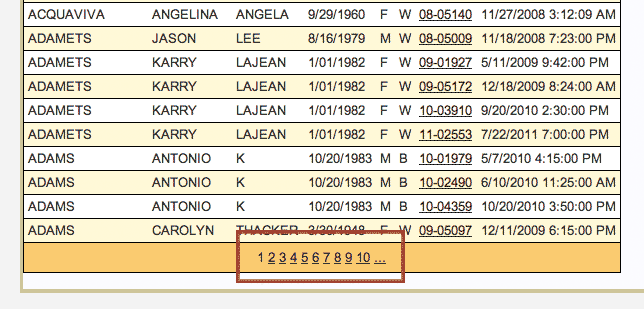
Unfortunately, the site does not have any deep links to the results. In fact, if you inspect the links with your web inspector (you did read that chapter, right?), you'll see that the links don't contain actual URLs. Instead, they contain JavaScript code:
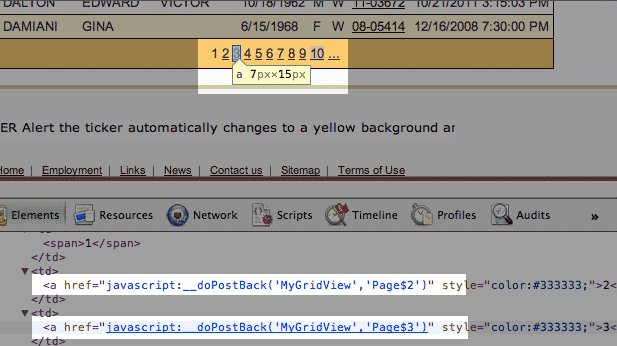
I've highlighted the relevant part of the link; the href attribute:
<a style="color:#333333;" href="javascript:__doPostBack('MyGridView','Page%247')">7</a>
When a link is clicked, the JavaScript inside its href attribute specifies that a method called __doPostBack. The webpage's already-loaded JS knows to expect this method call, which triggers a process that generates the server request for the next page.
To refresh your memory, in my big picture guide to web-scraping, this JS processing is Step #2. But remember that it's not worth poring over JS files (to figure out what __doPostBack actually does) when instead, you can use your web inspector to see the request sent by the browser after the JS does its magic (Step #3)
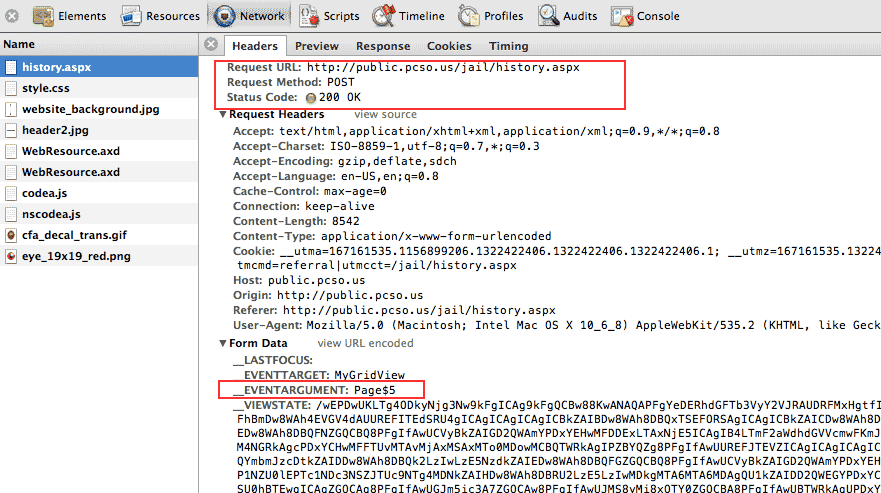
Looks pretty straightforward, right? That Page$5 attribute clearly comes from the JavaScript inside a given link. Can we just iterate through every integer from 1 to whatever?
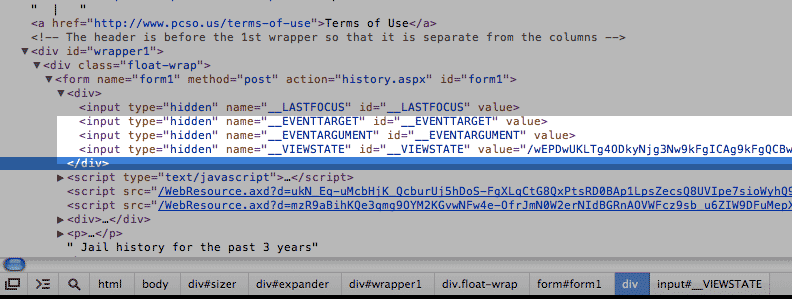
Unfortunately not. The sheriff's search form has some tricky fields to deal with. I've highlighted them in the screenshots below.
You can even see that there are <input> tags where the type is "hidden". The data values stored here are not visible in the browser-rendered page. Take special note of the hidden field with the id of __VIEWSTATE:
__VIEWSTATE becomes a sizeable parameter in the POST request:
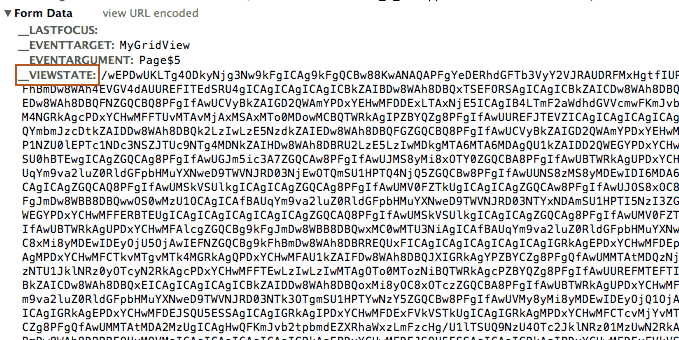
Session-tracking with hidden variables inside the form
This Putnam County site uses a search form with hidden variables to keep track of the user session. Because the search form submits the user's search terms with a POST request, there's no ability to directly-link to results.
This type of session-tracking, as described by Wikipedia:
Another form of session tracking is to use web forms with hidden fields. This technique is very similar to using URL query strings to hold the information and has many of the same advantages and drawbacks; and if the form is handled with the HTTP GET method, the fields actually become part of the URL the browser will send upon form submission. But most forms are handled with HTTP POST, which causes the form information, including the hidden fields, to be appended as extra input that is neither part of the URL, nor of a cookie.
The upshot for us is that the sheriff's webserver knows the page number we're currently accessing and uses this to limit how far we can jump ahead in the results list. If we have requested page 12 of the results, it will only let us access pages 10, 11, and 13 through 21. Submitting Page$300 as a parameter for page 300 will be rejected.
I'm not an expert on backend design. But my guess is that the those gibberish values in the hidden field of __VIEWSTATE are used by the server as a simple form of authentication. Each page's form has a unique value and so the backend script can tell if you're submitting an out-of-bounds page request.
It should be easy to wrap up the form values in a hash and submit using RestClient.post. But maybe my guess is wrong and the sheriff's website is detecting state through cookies. Rather than spend 15 minutes trying to satisfy my curiosity, I've decided to just use Mechanize, which handles all the details of acting like a browser, including properly submitting forms, clicking buttons, and consuming cookies.
I've started writing a chapter on Mechanize, yet to be finished. I try to use it as a last-resort because I like figuring out website operations on my own. But if time and blood pressure levels are a consideration, go with Mechanize.
Here's the scraping code in its entirety. I can't do a better job of explaining Mechanize's methods than its homepage, so I'll leave it to you to read the documentation if you're curious about its range of functionality.
The one hack I use is to keep track of the farthest results page I've visited to prevent an infinite loop when the scraper reaches the 590th-or-so page.
require 'rubygems'
require 'mechanize'
require 'fileutils'
REGEX = /javascript:__doPostBack\('MyGridView','(Page\$\d+)'\)/
TARGET = 'MyGridView'
SUBDIR = "data-hold/_pcsojail" #TK changedir
FileUtils.makedirs(SUBDIR)
URL = 'http://public.pcso.us/jail/history.aspx'
agent = Mechanize.new()
agent.get(URL)
agent.page.forms[0]['txtLASTNAME'] = '%'
agent.page.forms[0]['txtFIRSTNAM'] = '%'
agent.page.forms[0].click_button
#puts agent.page.links.map{|t| t.href}
page_links = agent.page.links.map{ |link|
if (k = link.href.match(REGEX)) #&& k[1].text.strip =~ /\d+/
k[1]
end
}.compact
# edge case: the first page of results
puts "Writing first page of results"
File.open("#{SUBDIR}/1.html", 'w'){|f| f.write(agent.page.parser.to_html)}
max_page_val_visited = 1
while (page_val = page_links.shift)
p_num = page_val.match(/\d+(?=$)/)[0].to_i
if max_page_val_visited >= p_num
# already visited this page, do nothing. Kind of a sloppy way to avoid
# infinite loop on last page. Oh well - Dan
elsif max_page_val_visited < p_num
max_page_val_visited = p_num
puts page_val
agent.page.forms[0]['txtLASTNAME'] = '%'
agent.page.forms[0]['txtFIRSTNAM'] = '%'
agent.page.forms[0]['__EVENTTARGET'] = TARGET
agent.page.forms[0]['__EVENTARGUMENT'] = page_val
agent.page.forms[0].submit
sleep 1
File.open("#{SUBDIR}/#{p_num}.html", 'w'){|f| f.write(agent.page.parser.to_html)}
if page_links.empty?
page_links = agent.page.links.map{|link| k = link.href.match(REGEX); k[1] if k }.compact[1..-1]
end
end
end
#__EVENTTARGET:MyGridView
#__EVENTARGUMENT:Page$30
Download the detail pages
This is much more straightforward. The results page contains direct-links to each detailed booking page. So RestClient.get will do the job.
As I've done in past web-scraping examples, I just download all the relevant pages and then parse them on my hard drive.
require 'rubygems'
require 'rest-client'
require 'nokogiri'
BASE_URL = 'http://public.pcso.us/jail/'
local_pages = Dir.glob('data-hold/*.html').sort_by{|p| p.match(/\d+/)[0].to_i}
count = 0
local_pages.each do |pgnum|
puts pgnum
page = Nokogiri::HTML(open(pgnum))
links = page.css('#MyGridView td a[target="_blank"]')
links.each do |link|
url = "#{BASE_URL}#{link['href']}"
puts url
r_page = RestClient.get(url)
fn = link.text.strip
File.open("data-hold/pages/#{fn}.html", 'w'){|file| file.write(r_page)}
sleep rand
end
count += links.length
end
puts count
Parsing the data
This is fairly straightforward. Open up the directory in which you've downloaded the 14,000+ pages and read each file.
The parsing-and-database-storing code creates two tables: bookings and charges (as well as two text files of the data). All of the information is drawn from the detail page. Here's an illustrated diagram:
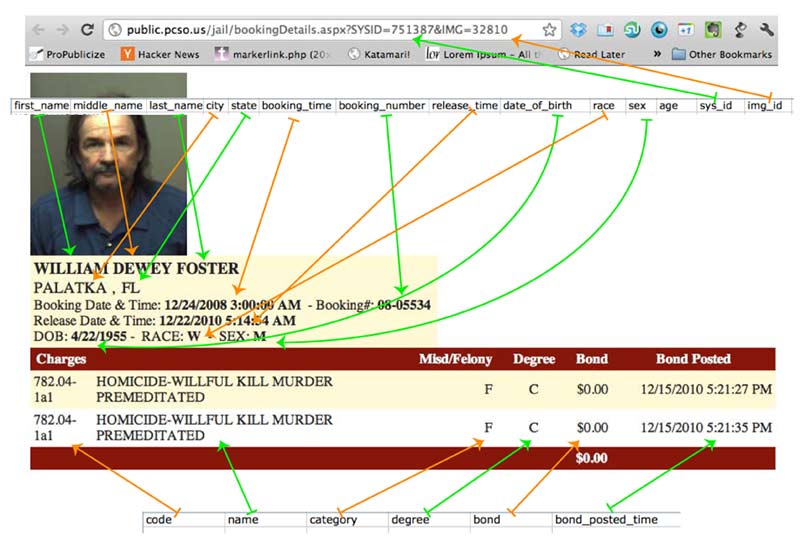
Screenshot and arrest information courtesy of the Putnam County Sheriff Department. William D. Foster was convicted of first-degree murder in 2010 and sentenced to life in prison for his role in a murder-for-hire scheme.
A couple of things I noticed on the booking pages of Mr. Foster's and his accomplice, Clint Horvatt, also convicted and sentenced to life for hiring Foster to kill his wife:
- They are both listed as each facing two charges of murder. It's possible some kind of revision to the charges data was made and the entries duplicated.
- The Bond Posted field in the charges table lists a type of posting not normally associated with bail bondsmen, as neither Horvatt or Foster were released on bail (as far as I can tell).
So when analyzing the data, be aware of the possibilities for inaccuracies. The sheriff's system with accurate listings may not feed directly to the historical archive. As the Putnam website states: "This data is for informational purposes only and should not be relied upon for any type of legal action."
Here's the ugly code I wrote one late night to just get it into SQLite3. It isn't worth mimicking (I may clean it up in a later update). There's a lot of repetition and there's a lot of constants-setting code, such as:
BIRTH_DATE_IDX = BOOKING_SPAN_LBLS.index{|a| a[1]=='date_of_birth'}This would be important if the website had the tendency to re-order its data-fields. But in our controlled environment of downloaded static files, a lot of the boilerplate material could be cleaned up.
A few other notes:
- I use the chronic gem, which provides better parsing of date strings. I'm not sure it's necessary as the date and time fields are pretty standard, but it's a nice gem to use out of habit.
- The sheriff's department only provides dates of birth, so the age field is something we derive ourselves. Moreover, we want the age at the time of the booking, so age is calculated by:
age = (Time.parse(_booking_date).to_i - Time.parse(_birth_date).to_i) / 60 / 60 / 24 / 365The Time object, when converted to an integer, is expressed in units of seconds. The division operations are used to convert it into years.
- code_short is also a derived field and is an attempt to create a more broad categorization of the penal codes used.
class String
def h_strip
self.gsub(/(?:\302\240)|\s|\r/, ' ').strip
end
end
require 'rubygems'
require 'nokogiri'
require 'sqlite3'
require 'chronic'
lists_dir = "data-hold"
pages_dir = "#{lists_dir}/pages"
bookings_table = "bookings"
charges_table = "charges"
DBNAME = "#{lists_dir}/pcso-jail-archive.sqlite"
CHARGES_LBLS = %w(code name category degree bond bond_posted_time)
BOOKING_SPAN_LBLS = [["DataList1_ctl00_FIRSTLabel", "first_name"], [ "DataList1_ctl00_MIDDLELabel", "middle_name"], [ "DataList1_ctl00_LAST_NAMELabel", "last_name"], [ "DataList1_ctl00_CITYLabel", "city"], [ "DataList1_ctl00_STATELabel", "state"], [ "DataList1_ctl00_COMMIT_DATELabel", "booking_time"], [ "DataList1_ctl00_PINLabel", "booking_number"], [ "DataList1_ctl00_Label1", "release_time"], [ "DataList1_ctl00_BIRTHLabel", "date_of_birth"], [ "DataList1_ctl00_RACELabel", "race"], [ "DataList1_ctl00_SEXLabel", "sex"]]
BOOKING_COLS = BOOKING_SPAN_LBLS.map{|col| col[1]} + ['age', 'sys_id', 'img_id']
CHARGES_COLS = CHARGES_LBLS + ["booking_number", 'code_short']
BIRTH_DATE_IDX = BOOKING_SPAN_LBLS.index{|a| a[1]=='date_of_birth'}
BOOKING_DATE_IDX = BOOKING_SPAN_LBLS.index{|a| a[1]=='booking_time'}
BOOKING_NUMBER_IDX = BOOKING_SPAN_LBLS.index{|a| a[1]=='booking_number'}
BOOKING_DATE_IDXES = BOOKING_SPAN_LBLS.select{|a| a[1] =~ /date|time/ }.map{|a| BOOKING_SPAN_LBLS.index(a)}
CHARGE_CODE_IDX = CHARGES_LBLS.index('code')
CHARGES_DATE_IDXES = CHARGES_COLS.select{|a| a =~ /date|time/ }.map{|a| CHARGES_COLS.index(a)}
BOOKING_SQL = "INSERT INTO #{bookings_table}(#{BOOKING_COLS.join(',')}) VALUES(#{BOOKING_COLS.map{'?'}.join(',')})"
CHARGES_SQL = "INSERT INTO #{charges_table}(#{CHARGES_COLS.join(',')}) VALUES(#{CHARGES_COLS.map{'?'}.join(',')})"
######## boilerplate stuff
## Building database
File.delete(DBNAME) if File.exists?(DBNAME)
DB = SQLite3::Database.new( DBNAME )
DB.execute("DROP TABLE IF EXISTS #{bookings_table};")
DB.execute("DROP TABLE IF EXISTS #{charges_table};")
DB.execute("CREATE TABLE #{bookings_table}(#{BOOKING_COLS.join(',')})");
DB.execute("CREATE TABLE #{charges_table}(#{CHARGES_COLS.join(',')})");
## Creating textfiles with headers
BOOKINGS_FILE = File.open("#{lists_dir}/sums/bookings.txt", 'w')
CHARGES_FILE = File.open("#{lists_dir}/sums/charges.txt", 'w')
CHARGES_FILE.puts(CHARGES_COLS.join("\t"))
BOOKINGS_FILE.puts(BOOKING_COLS.join("\t"))
Dir.glob("#{pages_dir}/*.html").each_with_index do |inmate_pagename, count|
puts "On booking #{count}" if count % 500 ==1
detail_page = Nokogiri::HTML(open(inmate_pagename))
sysid,img = detail_page.css("#form1")[0]["action"].match(/SYSID=(\d+)(?:&IMG=(\d+))?/)[1..-1]
booking_cols = detail_page.css('table#DataList1 span').map{|span| span.text.h_strip}
booking_cols.each_with_index{ |a, i| booking_cols[i] = Chronic.parse(a).strftime("%Y-%m-%d %H:%M") if BOOKING_DATE_IDXES.index(i) && !a.empty?}
age = (Time.parse(booking_cols[BOOKING_DATE_IDX]).to_i - Time.parse( booking_cols[BIRTH_DATE_IDX]).to_i) / 60 / 60 / 24 / 365
booking_number = booking_cols[BOOKING_NUMBER_IDX]
booking_data_row = booking_cols + [age, sysid,img]
BOOKINGS_FILE.puts( booking_data_row.join("\t"))
DB.execute(BOOKING_SQL, booking_data_row)
if charges_rows = detail_page.css('table#GridView1 tr')[1..-2]
charges_rows.each do |charge_row|
cols = charge_row.css('td').to_a.map{|td| td.text.h_strip}
cols.each_with_index do |a,i|
cols[i] = Chronic.parse(a).strftime("%Y-%m-%d %H:%M") if CHARGES_DATE_IDXES.index(i) && !a.empty?
end
code_short = cols[CHARGE_CODE_IDX].match(/^\d+(?:\.\d+)?/).to_s
charges_data_row = (cols << [booking_number, code_short])
CHARGES_FILE.puts( charges_data_row.join("\t"))
DB.execute(CHARGES_SQL, charges_data_row)
end
end
end
DB.execute "CREATE INDEX booking_index ON #{bookings_table}(booking_number)"
DB.execute "CREATE INDEX booking_index_k ON #{charges_table}(booking_number)"
DB.execute "CREATE INDEX code_index ON #{charges_table}(code)"
DB.execute "CREATE INDEX name_index ON #{charges_table}(name)"
DB.execute "CREATE INDEX code_short_index ON #{charges_table}(code_short)"
Data normalization
I kind of threw this section together and realized that there are a lot of ways I can expand on it. I may significantly revise it in a future update.
In the SQL chapter, the section on table joins has another applied demonstration of normalization.
If you're new to database-building, the data normalization principle here is relatively simple: Don't repeat data.
A flat textfile in which an inmate's name and information is repeated for each of his/her charges is a violation of data normalization principles. In the sample spreadsheet below, the cell-shading differentiates between each booking entry, and the text-color indicates columns in which the bookings data is repeated:
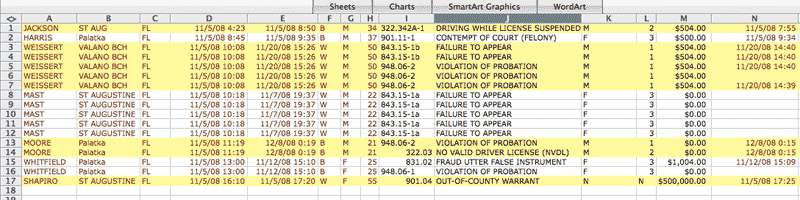
Why is this duplication a bad thing? It adds complexity to the maintenance of the data. If it turns out that John A. Doe was actually born in 1977 instead of 1960, the code that keeps the database up-to-date must make sure all of Doe's associated records reflect the correction. This seems easy enough in theory, but systems can grow in complexity faster than our ability to anticipate.
Create two tables
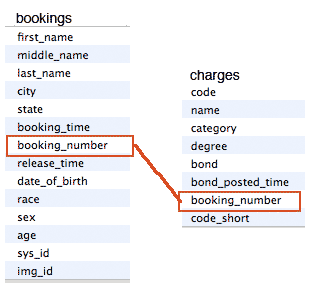
To reduce duplication, we create two tables: one for each booking and one for every charge.
The bookings table contains the identifying information of the inmate, including name, age, and city of origin, as well as the information about the booking procedure, such as the time and date of the booking.
The charges table contains information only pertinent to each individual charge: its penal code, its human-readable name, its severity, and the bond posted (as it turns out, bond does not seem to be broken out by individual charge).
Pick a unique key to link the records
The main impact of having two tables is that both tables share as little information as possible between associated records. But how do we keep track of the association? By creating a key field that is unique to each record in the parent table.
What's the "parent" table? The charges table has a many-to-one relationship with bookings: more than one charge can be associated with each a given booking entry. Likewise, many children can be associated with one parent (well, for asexual species at least). Therefore, bookings is the parent table.
The jail site's record structure already gives us a unique record key: the booking number. So when building the database, we just make sure that each charges record is associated with a booking_number as it is entered into the table.
How much normalization is necessary?
In this example, we don't normalize as much as we could. A cursory examination of the jail records reveals that:
- There are charges in which the criminal_code values are the same. For example, all first-degree murder charges have a code of: "782.04-1A1".
- There are people who have been booked more than once.
- In bookings, there is more than one person per city.
Therefore, our database could include at least three more tables:
- penal_codes – containing the actual code, the description, and possibly severity
- people – containing name, age, sex, race, hometown and mugshot
- cities – containing city name and state
In the case of bookings, there are codes in the jail data that are inconsistently labeled, e.g. "782.04-1A1" and "782.04 - 1a1" for first-degree murder. These may be obviously the same to a human reader. But to a computer, these entries are completely different unless you've written a program that specifically accounts for differences in capitalization and spacing.
So having a table for penal_codes allows us to keep a canonical list of codes. A table of people would make it easier to keep tract of distinct people whose names vary in the booking records. But maintaining a canonical list of records requires a data-cleaning phase, which is itself a whole different task and one that I leave for another day. My use of the code_short field, which only deals with numbers, is a quick and dirty way of making a canonical list.
Reducing duplication isn't a big deal in our use case because we aren't keeping a live up-to-date version of the jail log. But it's just a good habit to keep. And in cases where you make a serious effort towards data-cleaning, you will care more about normalization because it will reduce the amount of data-cleaning you have to do.
In one of the analyses examples below, we will see how not normalizing would have helped us.
Sample analyses and visualizations
For reasons that will be clearer later, the Putnam County Sheriff's jail data is interesting but has enough quirks in it that it's hard to analyze. This section contains simple queries and how to do them in SQL and to create visualizations with the Google Charts API.
SQL and Google Charts have been covered in other chapters, such as the project on California's surgeries data, so I won't spend much time discussing the code.
SQL queries
The following is just SQL practice in asking basic questions of the Putnam County jail data. I'm using the Firefox SQLite Manager plugin to enter in queries and test them out. You can, of course, run them in Ruby with the SQLite3 gem.
In the scraping code, we created a column called code_short that was a truncated version of code, e.g. "112" instead of "112.02c" Let's GROUP by that to find the most common types of alleged crimes. I also use the GROUP_CONCAT command to print out the list of crime names that fall under a given code_short:
SELECT COUNT(1) as code_count, code_short, group_concat(DISTINCT name), category
FROM charges
GROUP BY code_short, category
ORDER BY code_count DESC
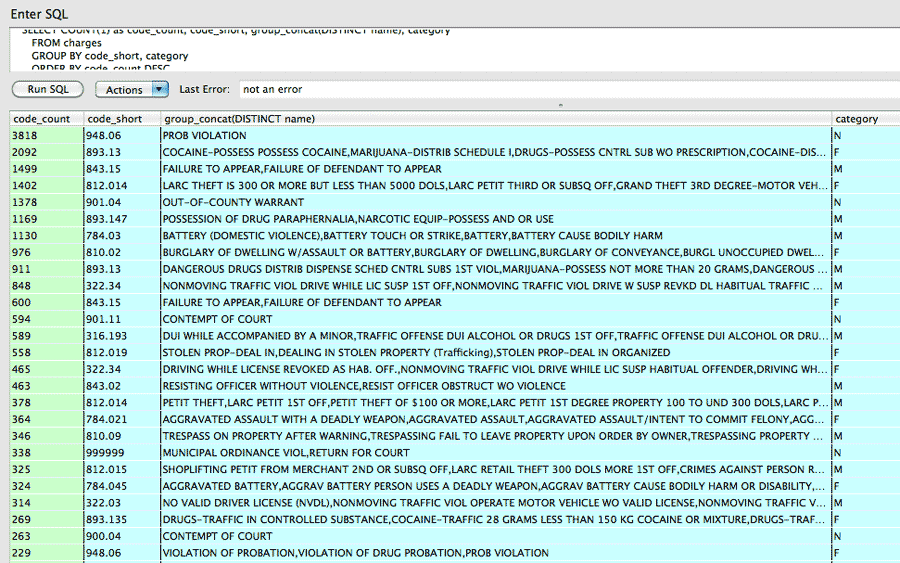
Unsurprisingly, probation violations are the most common reason for spending time in jail. The most common felonies are drug-related.
Getting a list of crimes by type is a handy reference to seeing what code corresponds to what kind of crimes. Here's a simple query to find allegations under the homicide category:
SELECT * FROM bookings
JOIN charges on bookings.booking_number = charges.booking_number
WHERE code_short LIKE "782%"
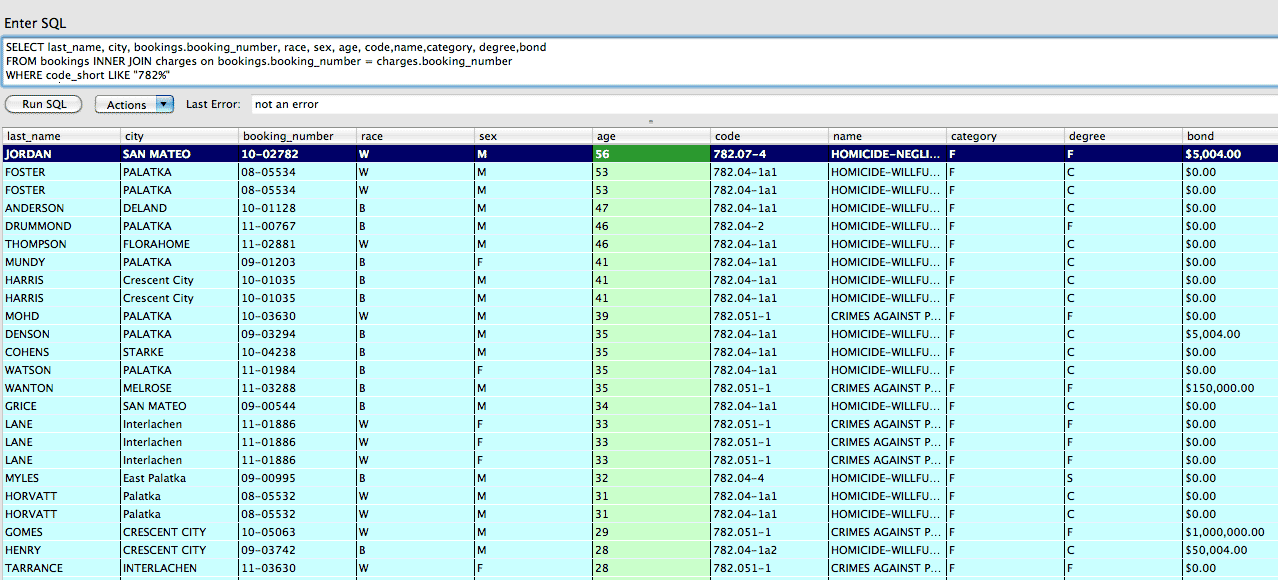
It's safe to assume that $0 for bail means that the inmate is not eligible for it, though we don't know if $0 is a valid amount for other kinds of circumstances.
It's also seem strange that the oldest of the accused – Mr. Jordan, 53 – has a bond of $5,004 for his homicide-related charge. Or that so many of the amounts include $4, but I don't have much insight to Florida's penal code and it doesn't have a published bail schedule (here are schedules from Los Angeles and Utah).
Let's do a quick sorted query to find the highest bail amounts in the last 3 years at Putnam County:
SELECT name, code, category, degree, bond FROM charges
ORDER BY bond DESC LIMIT 50
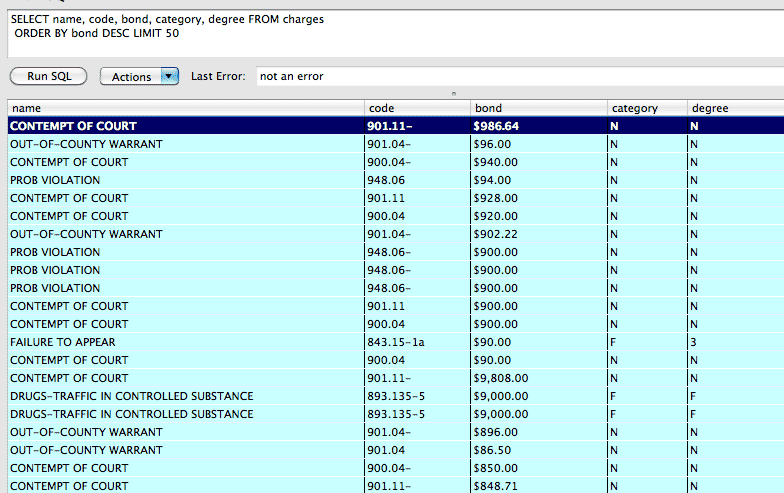
Whoops! Since we didn't typecast the bond column, the SQLite engine treats it as text, which is not at all helpful for numerical sorting.
Try this hack instead: sort by two attributes; the LENGTH of the string – as $200,000 will come before $90,000 – and the string itself, so that $900,000 comes before $200,000:
SELECT name, code, category, degree, bond FROM charges
ORDER BY LENGTH(bond) DESC, bond DESC LIMIT 50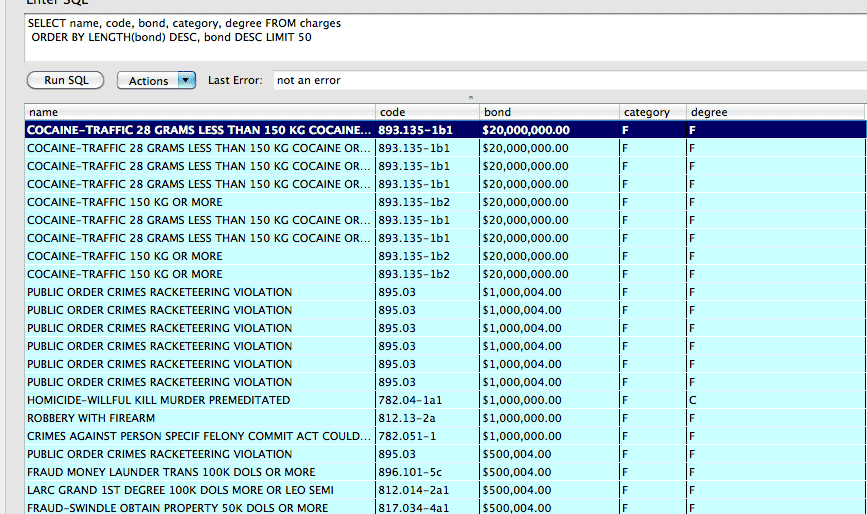
Using first and last names, as well as birth dates, we can do a reasonably accurate GROUP query to find the people who have had the most repeat visits to the Putnam County jail:
SELECT COUNT(1) AS b_count, first_name, last_name, booking_number, booking_time
FROM bookings
GROUP BY first_name, last_name, date_of_birth
HAVING b_count > 1
ORDER BY b_count DESC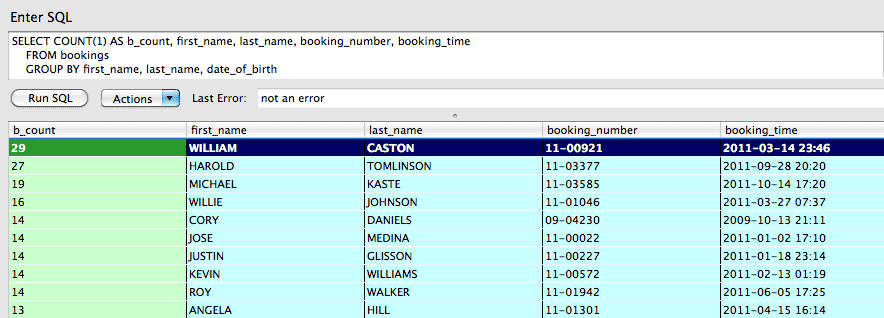
What this simple query doesn't show, though, are the list of charges per person. And this is where normalization would have helped us.
Remember when I said that we didn't need to go the full normalization route, which would have included making a table for people, so that each person would have multiple bookings? The simple query that we just tried above; it effectively created a table of unique people (or at least ones with differing first and last names and birthdates).
Had we instead built a people table to begin with, we wouldn't have to paste in the above query as a subquery. Which is what we have to do below in this triple-join query (the main SELECT and two actual JOIN statements):
/* Table 1: */
SELECT m_bookings.b_count, bookings.booking_time, bookings.first_name, bookings.last_name,
m_bookings.date_of_birth,
code, charges.name, category, degree, bond, bookings.booking_number
FROM bookings
/* Table 2 */
/* joining upon our original query as a subquery */
JOIN
(SELECT COUNT(1) AS b_count, first_name, last_name, booking_number, date_of_birth
FROM bookings
GROUP BY first_name, last_name, date_of_birth
HAVING b_count > 1
ORDER BY b_count DESC) AS m_bookings
ON
m_bookings.first_name = bookings.first_name AND
m_bookings.last_name = bookings.last_name AND
m_bookings.date_of_birth = bookings.date_of_birth
/* Table 3 */
JOIN charges
ON bookings.booking_number = charges.booking_number
ORDER by b_count DESC, m_bookings.last_name, m_bookings.first_name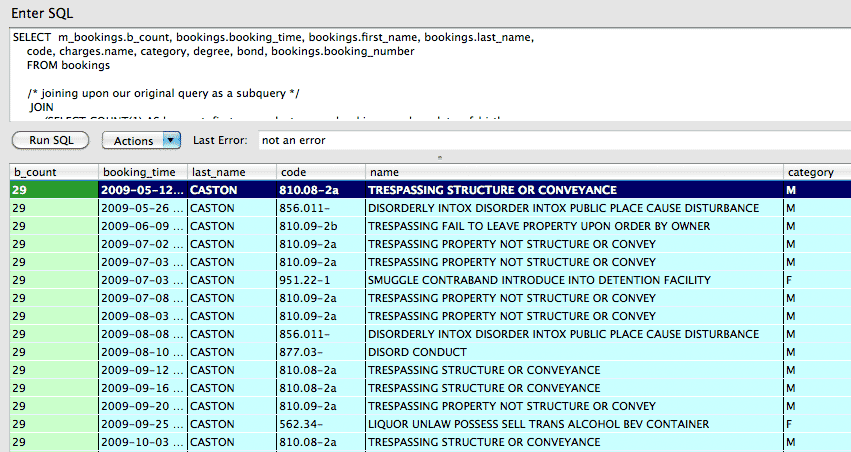
So that looks pretty convoluted, and to be honest, it took me a few tries to figure out why I wasn't getting all of the expected results. But the logic is simple to explain.
It's easiest to start from the bottom, with the very last JOIN between charges and bookings. Remember that charges have a many-to-one relationship to bookings – each inmate has one or more allegations against him/her. And the booking_number column exists in both tables to link the relationships.
Here's a simplified version of the charges and bookings, color-coded to show which charge matches to which booking record:
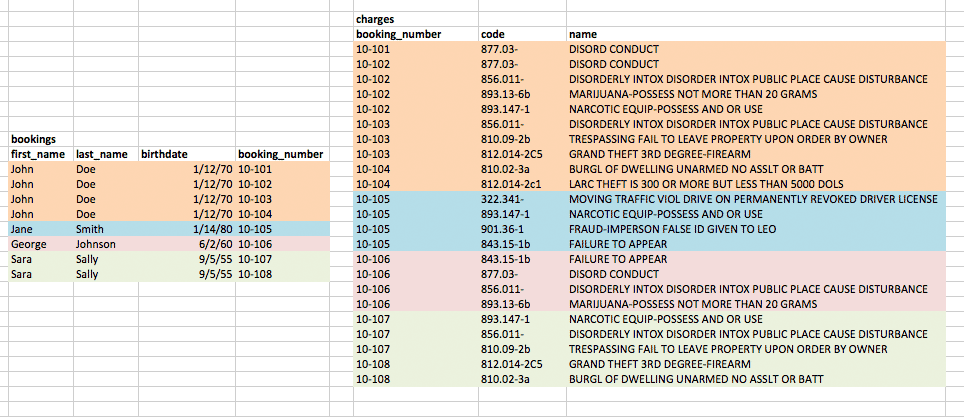
But this isn't quite right. Remember that we don't want every booking row. We want only the bookings from people who have been booked more than once. To find the people who meet this condition, we run our initial query that GROUPed by name and birthdate. The diagram below illustrates the effect of this query, in which the table is grouped into rows per unique names and birthdays:

By JOINing this subquery's result – think of it as a temporary table of people – to the entire table of bookings, we are getting a new result set in which we keep only the bookings that belonged to the people who have more than one booking.
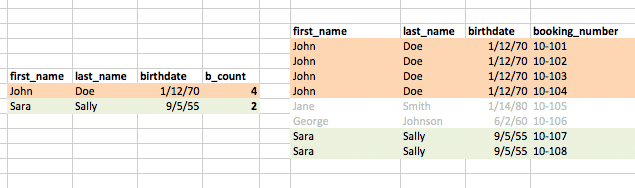
So the combination of this triple-join are the charges that match up to the booking_numbers of the people who each have more than one bookings:
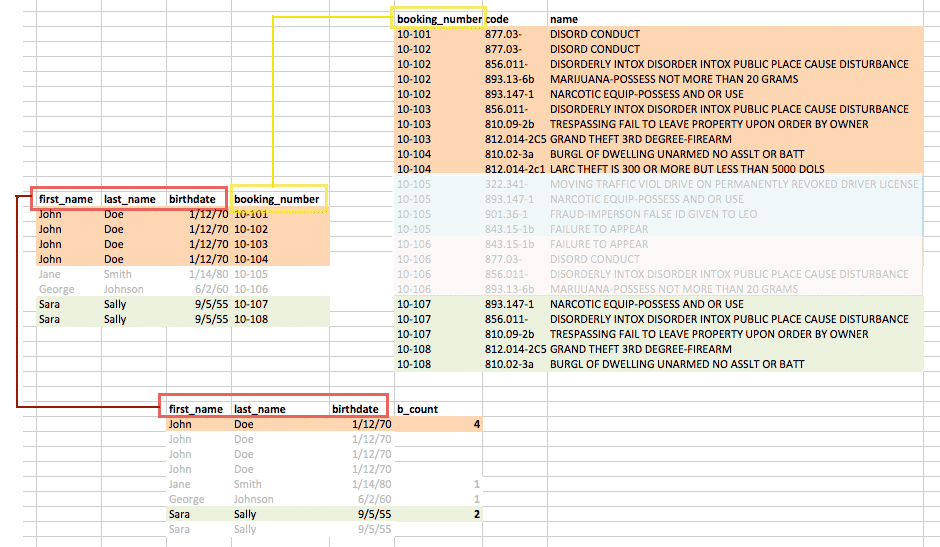
If this query confused you, don't worry, I was stumped for awhile because I thought there was a way to do it with just two JOINs (there probably is, but with commands that are even more confusing to think about).
There are some analyses that we could attempt here. For example, if we assign a certain severity "score" to types of crime, we could look at whether or not people were getting jailed for more serious charges with each subsequent visit to jail. I wasn't sure if three years was a long enough timespan to get a good sample, but as I've said before, statistics is not my strength.
Some caveats and notes
When doing the GROUPings, we see that there appears to be 7,714 unique persons in the PCSO jail archive and 2,989 of them show up twice is interesting, though keep in mind that some people may have arrests in another jurisdiction and so their full criminal history wouldn't be reflected in the PCSO archive.
And we don't know for sure if the records really reflect everyone who has ever been arrested and brought to the Putnam jail. If arrestees are allowed to post bail right away for certain crimes, they may not show up in the jail log.
Visualizations
This next section contains simple queries and Ruby code to generate Google Chart graphics.
Here's a Ruby script that does a GROUP BY race query, prints the rows, and then generates the URL for the appropriate Google chart:
require 'rubygems'
require 'sqlite3'
DBNAME = "../data-hold/pcso-jail-archive.sqlite"
DB = SQLite3::Database.new( DBNAME )
q = "SELECT race, COUNT(1) AS count FROM bookings GROUP BY race"
rows = DB.execute(q)
rows.each{|r| puts r.join(', ')}
_chl = rows.map{|r| r[0]}.join('|')
_chd = rows.map{|r| r[1]}.join(',')
puts "https://chart.googleapis.com/chart?cht=p&chs=350x200&chds=a&chd=t:#{_chd}&chl=#{_chl}"The output:
B, 5185 W, 9140 https://chart.googleapis.com/chart?cht=p&chs=350x200&chds=a&chd=t:5185,9140&chl=B|W
As you can see, either the PCSO jail population has a remarkably binary racial distribution, or there is some kind of error on their site in recording/displaying the racial categories.
Same steps with race, but using the sex column:
require 'rubygems'
require 'sqlite3'
DBNAME = "../data-hold/pcso-jail-archive.sqlite"
DB = SQLite3::Database.new( DBNAME )
q = "SELECT sex, COUNT(1) AS count FROM bookings GROUP BY sex"
rows = DB.execute(q)
rows.each{|r| puts r.join(', ')}
_chl = rows.map{|r| r[0]}.join('|')
_chd = rows.map{|r| r[1]}.join(',')
puts "https://chart.googleapis.com/chart?cht=p&chs=350x200&chds=a&chd=t:#{_chd}&chl=#{_chl}"F, 3469 M, 10856 https://chart.googleapis.com/chart?cht=p&chs=350x200&chds=a&chd=t:3469,10856&chl=F|M
require 'rubygems'
require 'sqlite3'
DBNAME = "../data-hold/pcso-jail-archive.sqlite"
DB = SQLite3::Database.new( DBNAME )
q = "SELECT age, COUNT(1) AS count FROM bookings GROUP BY age ORDER BY age ASC"
rows = DB.execute(q).inject([[], []]) do |arr, row|
arr[0] << row[0]
arr[1] << row[1]
arr
end
data = rows.map{|vals| vals.join(',')}.join('|')
puts "http://chart.googleapis.com/chart?cht=bvs&chxt=x,y&chds=a&chs=300x200&chbh=2,2&chxr=0,#{rows[0].min},#{rows[0].max},10&chd=t:#{data}"
require 'rubygems'
require 'sqlite3'
DBNAME = "../data-hold/pcso-jail-archive.sqlite"
DB = SQLite3::Database.new( DBNAME )
q = "SELECT STRFTIME(\"%H\", booking_time) as hour, COUNT(1) as booking_count
FROM bookings
GROUP BY hour ORDER BY hour"
rows = DB.execute(q).inject([[], []]) do |arr, row|
arr[0] << row[0]
arr[1] << row[1]
arr
end
data = rows.map{|vals| vals.join(',')}.join('|')
puts "http://chart.googleapis.com/chart?cht=bvs&chxt=x,y&chds=a&chs=450x300&chbh=10,6&chd=t:#{data}" The strftime function in SQLite3 (Ruby's Time class also has this method) can take the %w modifier if you want the one-digit representation for day of the week, with 0 representing Sunday and 6 representing Saturday.
require 'rubygems'
require 'sqlite3'
DBNAME = "../data-hold/pcso-jail-archive.sqlite"
DB = SQLite3::Database.new( DBNAME )
q = "SELECT COUNT(1) as booking_count, STRFTIME(\"%w\", booking_time) as weekday
FROM bookings
GROUP BY weekday
ORDER BY weekday"
rows = DB.execute(q).inject([[], []]) do |arr, row|
arr[0] << row[0]
arr[1] << row[1]
arr
end
data = rows.map{|vals| vals.join(',')}.join('|')
puts "http://chart.googleapis.com/chart?cht=bvs&chxt=x,y&chds=a&chs=300x300&chbh=20,10&chd=t:#{data}"This code snippet does two types of queries:
- Finds every DISTINCT year represented in the data
- Iterate through each year (in Ruby) and SELECT all bookings that took place during that year
require 'rubygems'
require 'sqlite3'
DBNAME = "../data-hold/pcso-jail-archive.sqlite"
DB = SQLite3::Database.new( DBNAME )
# get all years
q_y = "SELECT DISTINCT STRFTIME(\"%Y\", booking_time) AS year FROM bookings ORDER by year"
DB.execute(q_y).each do |yr|
rows = DB.execute("SELECT COUNT(1) as booking_count, STRFTIME(\"%m\", booking_time) AS month FROM bookings WHERE STRFTIME(\"%Y\", booking_time) = ? GROUP BY month ORDER BY month", yr)
_chd = rows.map{|vals| vals[0]}.join(',')
_chxl = rows.map{|vals| vals[1]}.join('|')
puts "http://chart.googleapis.com/chart?cht=bvs&chtt=Year+#{yr}&chxt=x,y&chds=a&chs=400x200&chd=t:#{_chd}&chxl=0:|#{_chxl}"
end
These are of course the simplest of visualizations. I may update this section as time permits.
Limitations of the data
As we've seen while inspecting the data, there are some questions about its accuracy, such as whether everyone who has been arrested is only either black or white and how (or if) the charge records are updated if something changes in the legal proceedings for a given inmate.
These kinds of apparent data inconsistencies aren't unusual in a public database. They just require knowledge of the entity and some actual reporting.
It's also important to recognize what we can't know, even if the public dataset is 100% correct and complete. I mentioned before that we can't know whether a given inmate had ever been jailed in another jurisdiction or even if he/she had been arrested for a previous incident but was able to post bail right away – something to remember when analyzing recidivism. The jail also probably doesn't record incident data, that is, when the alleged crime is thought to have actually happened. The arrest and booking time may differ substantially from the booking
And most importantly, jail logs don't typically keep track of the charges' legal disposition, whether the accused went to trial and faced the same charges they were booked for, and whether they were acquitted or found guilty.
No single dataset can completely capture every aspect of a jurisdiction's performance and activities, so researchers need to be resourceful and creative in gathering the sets of criminal justice data that are available. While this particular example with Putnam County may not yield any definitive conclusions, hopefully it gives you ideas on how the general approach for using code to collect data.