
"If all you have is a hammer, everything looks like a nail."
I learned Excel back in junior high and since then, I haven't become any better at using it. For most situations, I need something that supports regexes, complex queries, and also, not having the annoying tendency to auto-convert data in a way that eliminates the original data.
So I haven't kept up with learning Excel (and all of its design overhauls) because it's not flexible enough for me. On the other hand, Excel handles day-to-day data work very well and it's often the most convenient format for entering in and visualizing data among non-programmers. Just as it is wrong to shoehorn Excel into doing what it isn't designed to do, it's also wrong to completely forsake it.
This is where it is smarter to adopt a "if you can't beat 'em, join 'em" attitude. This chapter covers examples of how to use Ruby to play with external programs so that you're not reinventing the wheel.
Besides, we've effectively been using other people's programs since we first learned about Ruby methods and gems: You take someone else's code library, send in some input, and then get back the output. All without having to know the exact details.
This is the same concept when writing Ruby to execute non-Ruby software, just on a higher level.
I regret to say that this was the very last chapter that I decided to tack onto this book's initial release. Not only is it just a skeleton article at the moment, the code has only been tested in the Mac's UNIX environment. Obviously, your experience will vary depending on your success at installing the third-party packages.
Path-related errors
When running programs from your text editor, you might run into an error in which the interpreter can't find python or tesseract, or whatever external program you're trying to access.
The likely cause is that your text editor isn't configured correctly to read from the system path. For example, ruby may be installed at this path:
/Users/dairy/.rvm/rubies/ruby-1.8.7-p330/bin/ruby
If your system's PATH variable includes /Users/dairy/.rvm/rubies/ruby-1.8.7-p330/bin/, this allows you to run Ruby by simply invoking ruby.
This is the kind of bug that will require a little searching on Google or StackOverflow.
Ruby, Excel, and Google Docs
This book already covers ways to handle data and do visualizations through other APIs (such as Google Charts and SQLite). But Excel and other spreadsheet programs will still be faster for common kinds of charts and data-sorting.
So where can Ruby fit in? It handles the hard and often bespoke work of collecting and organizing non-structured data, including web-scraping. There's no reason why we can't combine the strengths of Ruby and a dedicated statistical/spreadsheet program.
The roo gem
The helpful gem allows you to read from Excel (.xls and .xlsx formats), OpenOffice, and Google spreadsheets. As of version 1.2.3, roo does not yet allow writing to Excel.
Unfortunately, the homepage doesn't have a strong tutorial. Your best bet is to check out the project's documentation page, which includes basic usage and row/cell access examples. Here's an abridged version
require 'rubygems'
require 'roo'
# creates an Excel Spreadsheet instance
s = Excel.new("myspreadsheet.xls")
# first sheet in the spreadsheet file will be used
s.default_sheet = s.sheets.first
# returns the content of the first row/first cell in the sheet
s.cell(1,1)
# this also works:
s.cell('A',1)
s.first_row # the number of the first row
s.last_row # the number of the last row
s.first_column # the number of the first column
s.last_column # the number of the last column
Downloading and parsing Excel sheets
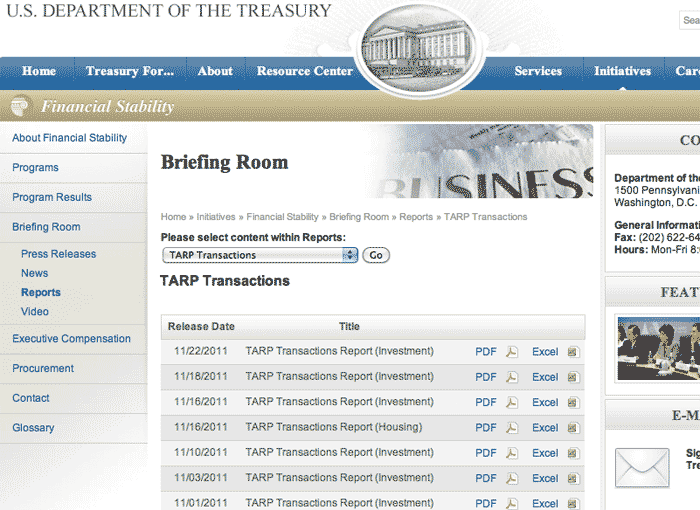
The following code snippet collects all the Excel spreadsheet links on this U.S. Treasury homepage, downloads the files, and spits out the data using the roo gem:
require 'rubygems'
require 'roo'
require 'nokogiri'
require 'open-uri'
TREAS_BASE = "http://www.treasury.gov"
TREAS_URL = "#{TREAS_BASE}/initiatives/financial-stability/briefing-room/reports/tarp-transactions/Pages/default.aspx"
xlsx_links = Nokogiri::HTML(open("#{TREAS_URL}", {"User-Agent"=>'Ruby'})).css("a").select{|a| a['href'] =~ /xlsx/}.map{|a| a['href']}
xlsx_links.each do |link|
puts link
xls = Excelx.new(URI.encode("#{TREAS_BASE}#{link}"))
((xls.first_row)..(xls.last_row)).each do |row|
puts ((xls.first_column)..(xls.last_column)).map{ |col| xls.cell(row, col)}.join("\t")
end
endRuby and Google Spreadsheets
This section isn't written yet. However, the roo gem includes an interface with Google Spreadsheets, and allows you to login to your Google Account and read and write to documents. Google also offers an API for document management, including document creation and access control; I'm not sure that roo or any of the other spreadsheet gems support it.
Google Spreadsheets are great for collaborative data projects. It has limitations similar to Excel, but there's no easier way to do group data-entry and editing. Being able to write a Ruby script that automatically pulls data from the cloud makes things even easier.
You can read more at the roo homepage. You can also try the google_spreadsheet gem.
Ruby and the Command Line
The rest of this chapter will show how to call command-line operations with a Ruby script.
By accessing the command line (also referred to as the "shell"), a Ruby script can execute non-Ruby programs, wait for them to finish, and then read their output. This isn't much different to how we use Ruby methods without understanding their source code. Using command-line programs is the same way – though with little to no ability to edit the programs if needed – focus on understanding their input and output.
This section is unpolished and the number of examples might make things seem more complicated than they are. Basically, all you need to know for now is the backtick method:
In Windows, executing the following command inside a Ruby script will get you the directory listing:
`dir`The equivalent command in Mac/Unix:
`ls`"Hello shell"
In both Windows and Mac/Unix command-shells, the echo command repeats the text given to it.
Open the command line shell and type in: echo "Hello shell":
The backtick

The easiest way to run a shell program is by enclosing the command with the backtick character: `
Don't confuse it with an apostrophe character. On most keyboards, the backtick is on the same key as the tilde character ~
Now go into irb and enter the echo command surrounded with backticks:
`echo "Hello shell"`The output, as seen from the Mac Terminal window:
Standard output
In the case of echo, the result of the command is printed onto the screen.
When a program has output data, it writes it to an output stream known as standard output. By default, standard output is your terminal screen.
The backtick is a Kernel class method. It returns the standard output of the command that it executed.
So when echo is called via the backtick method, the return value is what was "echoed":
As you should know by now, the Ruby puts method also prints to screen. But as a method, it returns nil. This section involves running Ruby from the command-line inside of another Ruby script. And that's as confusing as it sounds, so you'll have to pay extra attention to when you're doing something inside the Ruby script and when you're executing a command-line operation.
Print the directory's listing with a shell command
Using your operating system's command for listing a directory (dir and ls for Windows and Mac/Unix, respectively), read the result into a Ruby array and print the list sorted alphabetically.
Solution
The directory listing command outputs to screen, i.e. standard output. Assign the output to a Ruby variable, split by the newline \n character, sort and then puts:
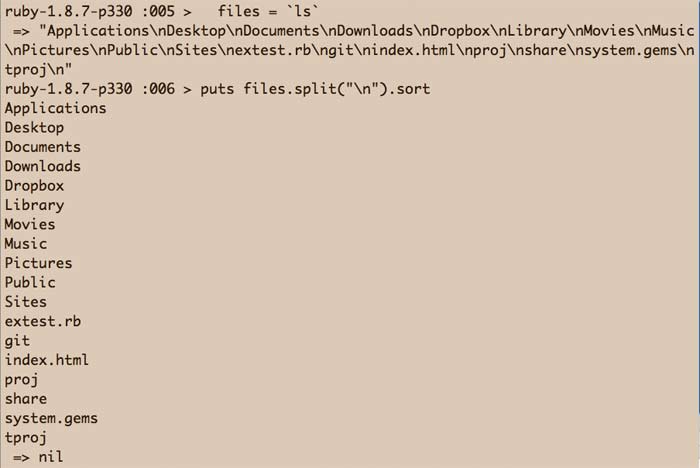
# use 'dir' for Windows systems
files = `ls`
puts files.split("\n").sortThe output:
Opening a pipe with popen
The backtick method works well if you're only running programs that don't need any user input throughout their execution. For example, doing a directory listing with ls or dir requires no extra input after you've executed the command.
If you are running programs in which you need to feed commands – also referred to as standard input – you can use IO.popen.
What's a command-line program that takes in standard input? How about the Ruby interactive shell, i.e. irb?
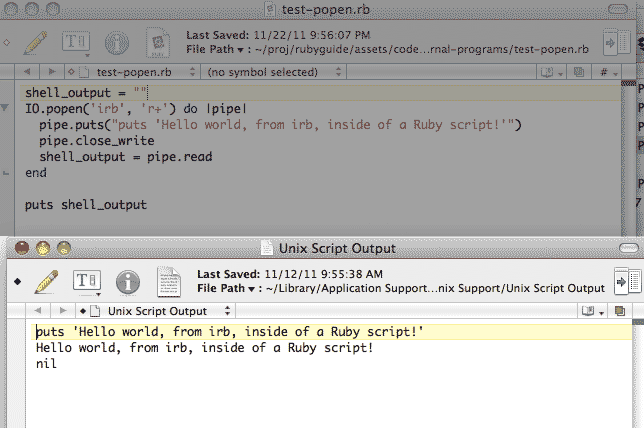
shell_output = ""
IO.popen('irb', 'r+') do |pipe|
pipe.puts("puts 'Hello world, from irb, inside of a Ruby script!'")
pipe.close_write
shell_output = pipe.read
end
puts shell_output
If you save the above code to file and then execute it, you'll get output like:
One more example – the following script does these actions:
- Changes its working directory using Dir.chdir('some_directory')
- Prints to screen its working directory using Dir.pwd
- Opens a new pipe to irb
- Inside of irb: Changes to a different working directory and also executes Dir.pwd
- Closes the pipe, exits irb, and stores the irb output into the variable irb_output
- Prints to screen the last line of irb_output, which is the result of Dir.pwd as called from inside irb
- And finally, prints to screen the current working directory of which is the result of Dir.pwd as called from the original script
# change to my Desktop directory
Dir.chdir("/Users/dairy")
puts "The parent script starts off directory: #{Dir.pwd}"
irb_output = ""
IO.popen('irb', 'r+') do |pipe|
# inside of irb, changing to a different directory
pipe.puts('Dir.chdir("/Users/dairy/Downloads")')
pipe.puts('Dir.pwd')
pipe.close_write
irb_output = pipe.read
end
# output what *irb* had in its final command: Dir.pwd
irb_pwd = irb_output.split("\n")[-1]
puts "irb had a working directory of: #{irb_pwd}"
puts "The parent script finishes inside the working directory: #{Dir.pwd}" Because the second Dir.chdir command happened inside the irb program, the original script's working directory is not affected:
The parent script starts off directory: /Users/dairy irb had a working directory of: "/Users/dairy/Downloads" The parent script finishes inside the working directory: /Users/dairy
Confused much?
If this has you more confused than Christopher Nolan's movie "Inception" about dreams-within-a-dream, it's OK. There's only one key concept to understand here: the IO.popen method creates a subprocess in which to run the irb program. This subprocess largely executes (don't know if this is technically correct) in a universe independent of the script that spawned it.
Short overview of IO.popen
- IO.popen(cmd, 'r+')
- This opens up a input/output pipe. The program specified in the first argument, cmd, is executed. The second argument – 'r+' in this case – indicates that we want to read and write to this pipe.
- {|pipe| #...block }
- If you pass a block into IO.popen, the object pipe is of the IO class (note that pipe is just my arbitrarily chosen name for it).
- pipe.puts("some string with a command")
- Just as file_object.puts("some string") will print the given string to a file, pipe.puts sends the string to pipe with a newline character at the end. Remember that in programs such as irb, hitting Enter – which creates a newline character – executes the current line of code.
- pipe.close_write
- This closes the pipe from any more write (including puts) operations.
- pipe.read
- This reads any output by the program.
Broken pipes
There are many aspects of input and output streams that I have neglected to cover. Suffice to say, if you aren't well versed in these details, you will be confused by this kind of behavior:
IO.popen("irb", "r+") do |obj|
obj.puts("Hello world from irb")
obj.close_write
end/Users/dairy/.rvm/rubies/ruby-1.8.7-p330/lib/ruby/1.8/irb.rb:141:in `write': Broken pipe (Errno::EPIPE)
In this case, Ruby expects you to read the contents of the pipe (named obj, in this example) before exiting the block:
IO.popen("irb", "r+") do |obj|
obj.puts("Hello world from irb")
obj.close_write
obj.read
endHowever, in the use cases so far described, do not attempt to read before the pipe has been closed to writing. The following will result in a non-responsive program loop:
IO.popen("irb", "r+") do |obj|
obj.puts("Hello world from irb")
obj.read # this is bad
obj.close_write
endHere's what it looks like when I try to execute something similar from my text editor:
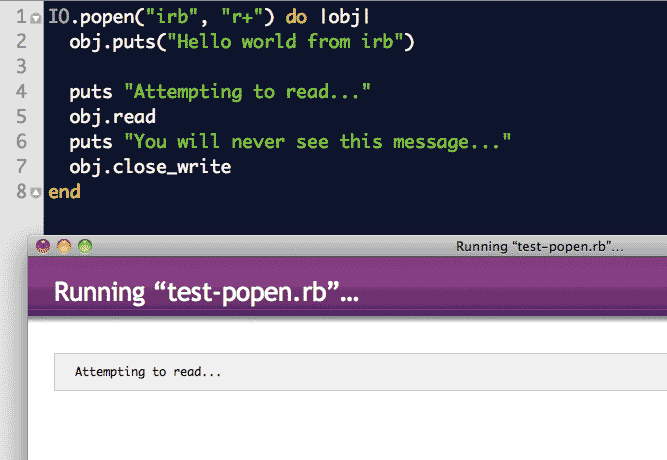
We're not writing many user-input interactive programs right now so I leave out further explanation of of input/output streams for now. The concepts are common to most modern programming languages, though. If you attempt to use popen or any other kind of IO stream, just stick to this basic template:
- If the external program has written anything to the pipe object, call the pipe's read method before the end of the block.
- Don't execute the read operation until after you've closed the pipe (pipe.close_write) to writing.
Example: Running SQLite3's command shell from a Ruby script
Note: This example makes more sense if you're familiar with the SQL chapter. And you'll need to install SQLite3 of course.
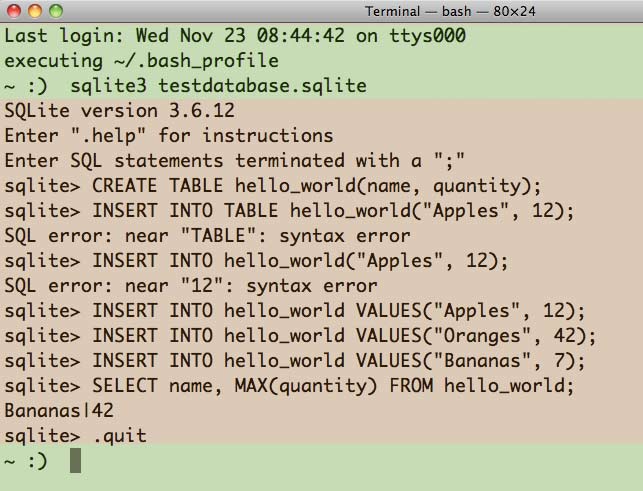
This is a screenshot of me running SQLite3 from the command-line and creating a new database file, creating a table, inserting values (and making syntax errors), and selecting a row (the Terminal area before I've entered the SQLite3 environment and after I've exited is highlighted in a different color):
In the following example, I demonstrate how to run SQLite3 from the command line within Ruby. Of course, there's really no reason to do this since there's a perfectly good SQLite3 gem. But this is just a demonstration. The following script will:
- Read from a XML file of tweets
- Parse that file using the crack gem
- Use IO.popen to run sqlite3's command-line interface and to open a database file called test.sqlite
- Run the sqlite3 commands needed to create a new table with columns for every field contained in the tweets XML file
- Inside of the Ruby context, iterate through each parsed tweet and store it in the sqlite3 database
- Close the pipe to write operations and read its standard output
- Inside the Ruby context, loop through and print the result of the sqlite3 SELECT query.
require 'rubygems'
require 'open-uri'
require 'crack'
url = 'http://ruby.bastardsbook.com/files/tweet-fetcher/tweets-data/USAGov-tweets-page-1.xml'
statuses = Crack::XML.parse(open(url))['statuses']
puts "\t\n(Ruby):\tDownloaded #{statuses.length} statuses\n"
shell_output = ""
IO.popen('sqlite3 test.sqlite', 'r+') do |pipe|
pipe.puts("DROP TABLE IF EXISTS tweets;")
status_fields = statuses.first.keys
pipe.puts("CREATE TABLE tweets(#{status_fields.map{|s| "`#{s}`"}.join(',')});")
statuses.each do |status|
# create string of field values, using a poor man's quote-sanitizer
values = status_fields.map{|key| "'" + status[key].to_s.gsub(/'{1,}/, "''") + "'"}
q = "INSERT INTO tweets VALUES(#{values.join(',')});"
puts "\t\n(Ruby):\tTrying query: #{q}\n\n"
pipe.puts q
end
pipe.puts("SELECT text FROM tweets WHERE retweet_count > 10;")
pipe.close_write
shell_output = pipe.read
end # close pipe
puts "\n\n\n Output of our sqlite3 work:"
sleep 1
shell_output.split("\n").each{|row| puts "#{row}\n\n"}When standard output is non-existent
Just like in Ruby, not all command shell programs output to screen. For example, the Windows/Mac/Unix shell command to change to the parent directory:
cd ..
This command runs silently. The result of cd is that you're in a new directory. No standard output is written, and thus, there is no output to screen. Contrast this with ls/dir, which would be of little use if it didn't output the contents of the directory.
The file copy method also runs silently: in Windows, this is:
copy source.txt destination.txt
In Mac/Unix:
cp source.txt destination.txt
Trying to execute this in Ruby (I first create a file named source.txt):
source_name = "source.txt"
dest_name = "dest.txt"
# file created for demonstration purposes
File.open(source_name, 'w'){|f| f.write("Hello text file 1234")}
# copy file using your system's command line:
shell_output = `cp #{source_name} #{dest_name}`
# Here, I make the mistake of expecting shell_output to hold the
# destination file's name. But again, it holds *nothing*
File.open(shell_output, 'r'){|f| puts f.read}
#=> Errno::ENOENT: No such file or directory -
If we want to read the contents of the destination file, we have to design our Ruby script to refer to the name of that destination file. So change the final line of the previous snippet to:
# ... dest_name has been previously defined as "dest.txt"
File.open(dest_name, 'r'){|f| puts f.read}
As expected:
Hello text file 1234
Just remember that since you're operating within the Ruby environment to use the same design principles you've been using to make effective Ruby scripts. The command-line operations are just an additional layer.
Ruby and Python

Ruby is a great programming language but it's not everyone's preferred working language. And sometimes very useful programs written in another language, such as Python, haven't been ported over to Ruby.
In an ideal world, you should just take the time to learn the other language. But when time is short, you can get by with reading the non-Ruby program's documentation to understand what's supposed to go in and what's supposed to come out. And then you write a Ruby wrapper around it.
Python and Ruby are frequently compared against each other because both are very popular right now and both are behind powerful web frameworks: Django for Python and Ruby on Rails.
You won't go wrong with learning either of them, as both share so many features and strengths that they also have a lot of the same kind of functional software. But you might run into a situation in which a program hasn't been ported over.
In this section, I cover the basics of running Python from the command-line. Then I demonstrate how to use Ruby to work with a handy Python script for taking screenshots of websites.
"Hello world", in Python
To run a Ruby script straight from the command-line, you simply type "ruby" and then the name of the script:
We can run Python scripts in the same way:
The following Ruby script creates a new text file named "hello-world.py" with a single print command. Then it executes the Python script from the command-line using the backtick method:
PYNAME = 'hello-world.py'
File.open(PYNAME, 'w'){|f| f.write "print 'Hello world. I am a python!'" }
python_output = `python #{PYNAME}`
puts "The output from #{PYNAME} is: #{python_output}"The output:
The output from hello-world.py is: Hello world. I am a python!
Again, the python program executes in its own subprocess. The Ruby script waits for it to finish and then outputs the result of the python script to screen. In this case, the output of the Python script is the print command.
Webpage screenshots in Python
Scraping websites is handy for collecting data. But sometimes we're interested in the visual layout of a website. Check out this 10-month timelapse of the New York Times homepage by Phillip Mendonça-Vieira:
For that kind of extensive documentation, we don't want to take screenshots by hand. Paul Hammond has written a handy command-line utility called webkit2png, which is much faster than opening up a browser and visiting a website just to take a screenshot.
Unfortunately, webkit2png is written in Python. But since it's a command-line tool, we can still control its input and output in a Ruby script. Think of it as a method named webkit2png.
This most likely does not work on Windows or Linux. From the webpage:
Check your computer has Mac OS X 10.2 or later, Safari 1.0 or later, and PyObjC 1.1 or later. If you have Mac OS X 10.5 Leopard or later everything you need is installed already.
To take a screengrab of the New York Times homepage and save it to a particular directory, this is specified syntax for the command-line operation of webkit2png:
python webkit2png.py --dir=some_directory http://www.nytimes.com
How can we do this for more than one website without manually typing this shell command over and over? And if we don't want to learn a lick of Python? Build a collection of URLs in Ruby and use a Ruby loop to iterate through, calling `python webkit2png.py` on each URL.
In the following example, I scrape this Nieman Lab article, "Top 15 newspaper sites of 2008", read the link for each newspaper, and then execute webkit2png on each URL:
require 'rubygems'
require 'nokogiri'
require 'open-uri'
require 'fileutils'
DIR = 'data-hold/screenshots/newspapers'
FileUtils.makedirs(DIR)
URL = "http://www.niemanlab.org/2009/02/top-15-newspaper-sites-of-2008/"
Nokogiri::HTML(open(URL)).css("strong a").each do |a|
host = URI.parse(a['href']).host.split('.')[-2]
shell_cmd = "python webkit2png.py --dir=#{DIR} --filename=\"#{host}\" #{a['href']}"
puts shell_cmd
`#{shell_cmd}`
endBecause the webkit2png does not return output to the screen, I have to use a Ruby puts command in order to see the progress of the script. The output:
python webkit2png.py --dir=data-hold/screenshots/newspapers --filename="nytimes" http://www.nytimes.com
python webkit2png.py --dir=data-hold/screenshots/newspapers --filename="usatoday" http://www.usatoday.com
python webkit2png.py --dir=data-hold/screenshots/newspapers --filename="washingtonpost" http://www.washingtonpost.com
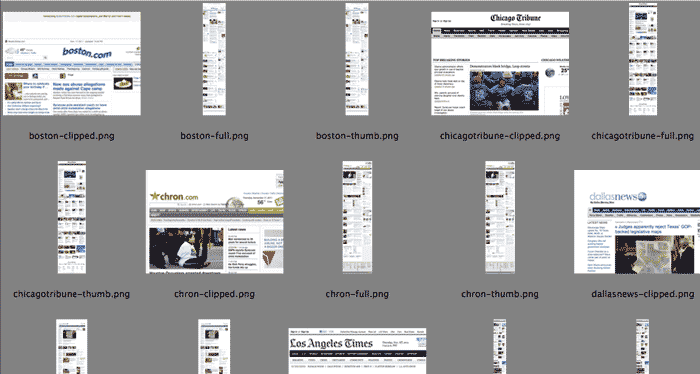
The output that's actually interesting is the files it creates; by default webkit2png will create three files for each website: two thumbnails and a full-size screenshot:
This script takes enough time to execute that you'll notice the Python icon pop-up in your Mac OS X dock:
Auto-optimized-optical character recognition
Even as more and more records are created digitally, it's safe to say that we'll still deal with printed text for the foreseeable future. Scanners allow us to save paper records in a digital format, but they only create a photograph of the record. Any text content is inaccessible for computerized tasks such as searching and Ctrl-C-type copy-and-pasting.
However, optical character recognition (OCR) software can "read" these document images and take a crack at extracting digital text. You see this in action when depositing checks into modern ATMs that can detect and automatically credit your account for the written amount.
OCR software exists for personal computer users, too. Adobe Acrobat Professional allows you to batch-OCR files and store the extracted text as meta-information in a PDF. There are also online-services that will convert uploaded files.
However, commercial packages can be expensive. Fortunately, the excellent Tesseract OCR program, now maintained by Google, is free for use.
Tesseract: open-source OCR
Tesseract is an OCR engine originally developed by HP Labs and is now maintained as a Google Project. It is widely used in many translation software packages, including DocumentCloud, because it is free and performs very well.
In other words, Tesseract is a prime example of a program that performs a very useful function at such a level that you won't be able to code yourself in a reasonable amount of time.
In the course of writing this section, I've realized that Tesseract 3.0 is now widely available. The code used in this section works fine, but version 3.0 may have more features that I don't cover here.
You can download it from the Tesseract homepage. Mac OS X users who have installed Homebrew can install it with this shell command:
brew install tesseract
To run Tesseract, you give it the name of the TIF image and the name of the textfile to store the extracted text.
Here is an image of the table of contents for Edward Tufte's Data Analysis for Politics and Policy (available as a free PDF at Tufte's website):

Using tesseract from the command line requires giving the program two arguments: 1) the name of the image and 2) the name for the resulting text file
The resulting text file contains:
Contents PREFACE CHAPTER 1 INTRODUCTION TO DATA ANALYSIS Introduction, Causal Explanation, 2 An Example: Do Automobile Safety Inspections Save Lives?, 5 Developing Explanations for the Observed Relationship, 18 Costs and Unquantifiable Aspects, 29
As you can see, it's not perfect, but it almost gets everything. Not too bad for a free one-line, out-of-the box solution.
But if you're dealing with hand-scanned documents, you more likely to see scans of this quality:

Tesseract actually handles the crooked text well. But it completely misses the highlighted area in the document:
Introduction
Students of political and social problems use statistical tech-
niques to help
test theories and explanations by confronting them with empirical
evidence,
summarize a large body of data into a small collection of typical
values,
confirm that relationships in the data did not arise merely because
of happenstance or random error,
discover some new relationship in the data, and
inform readers about what is going on in the data.
The use of statistical methods to analyze data does not make a
study any more "scientific," “rigorous," or "objective.” The e
ntitative anal sis is not to sanctif a set of findin _
uan itative techniques will be more likely to illuminate if t e a a
analyst is guided in methodological choices by a substantive under-
standing of the problem he or she is trying to learn about. Good
procedures in data analysis involve techniques that help to (a) answer
the substantive questions at hand, (b) squeeze all the relevant in-
Tesseract performs best with well-aligned black-and white images. It's not such a big deal to go into your favorite image editor to rotate the scan into proper alignment and convert it to grayscale:

As you can see, the translation of the highlighted area comes out much better here:
Introduction
Students of political and social problems use statistical tech-
niques to help
test theories and explanations by confronting them with empirical
evidence,
summarize a large body of data into a small collection of typical
values,
confirm that relationships in the data did not arise merely because
ol' happenstance or random error,
discover some new relationship in the data, and
inform readers about what is going on in the data,
The use of statistical methods to analyze data does not make a
study any more "scientific," "rigorous," or "objective" The purpose
of quantitative analysis is not to sanctify a set of findings. Unfortu-
nately, some studies, in the words of one critic, “use statistics as
a drunk uses a street lamp, for support rather than illumination."
Quantitative techniques will be more likely to illuminate if the data
analyst is guided in methodological choices by a substantive under-
standing of the problem he or she is trying to learn about. Good
procedures in data analysis involve techniques that help to (a) answer
the substantive questions at hand, (b) squeeze all the relevant in-
But it's a hassle to do this manual image-editing for hundreds of pages. This is where Ruby programming can make life easier by creating a workflow that optimizes the image for OCR and then runs tesseract on it. How can Ruby do the image-optimization operations (straightening the text and converting to black-and-white)? By using more external software.
ImageMagick and the RMagick gem
ImageMagick is a cross-platform image manipulation library that includes routine image editor tasks such as cropping, resizing, rotating, and format-converting of images, as well as a ton of other more advanced features, limited only by your ability to do linear algebra.
Sure, having a graphical interface, such as Adobe's Photoshop or the open-source GIMP to manipulate graphics is ideal. Because you typically want to see the effects of each step as you do them, instead of having to picture it in your head.
But when the image operations require little artistry – such as creating thumbnails for thousands of images – ImageMagick is an invaluable tool. For our Tesseract situation, we only need to straighten and decolor a bunch of document images. ImageMagick can handle the latter task easily. As for straightening the image, its deskew function is going to be faster than rotating an image by mouse-drag, as long as the crookedness isn't at a severe angle.
You can install ImageMagick by downloading an installer package from its homepage. Mac OS X users who have installed Homebrew can install it with this shell command:
brew install imagemagick
The RMagick gem
As ImageMagick is cross-platform, you need a Ruby-specific interface to access its functions. Rather than write your own series of Ruby command-line calls, just install the RMagick gem.
As with other gems, the installation involves typing this into the command-shell:
gem install rmagick
But depending on how well the ImageMagick installation went for you, you might run to any number of errors. Even if it goes smoothly, the installation will take longer to run through than with other gems.
Consult the RMagick FAQ, Google and StackOverflow if you encounter difficulties.
Tesseracting + ImageMagcking
To review, you'll have to install the following software in order to create a Ruby script that optimizes scanned images and uses Tesseract to extract their textual content:
- The ImageMagick, a library used for command-line image manipulation
- The RMagick gem, which provides a Ruby interface for ImageMagick
- Tesseract, an open source OCR program that runs from the command-line
Here's example code. Understanding it requires being familiar with RMagick, but there's not much more to it than that. Here is what the code does:
- Opens an image file
- Optimizes the image for OCR by straightening it and creating a grayscale version that is saved to disk as a TIFF
- Executes tesseract from the command line
- Reads the contents of the text file created by tesseract
require 'rubygems'
require 'rmagick'
def tessrack(oimg_name, do_gray=true, keep_temp=true)
fname = oimg_name.chomp(File.extname(oimg_name))
# create a non-crooked version of the image
tiff = Magick::Image::read(oimg_name).first.deskew
# convert to grayscale if do_gray==true
tiff = tiff.quantize(256, Magick::GRAYColorspace) if do_gray == true
# create a TIFF version of the file, as Tesseract only accepts TIFFs
tname = "#{fname}--tesseracted.tif"
tiff.write(tname){|t| t.depth = 8}
puts "TR:\t#{tname} created"
# Run tesseract
tc = "tesseract #{tname} #{fname}"
puts "TR:\t#{tc}"
`#{tc}`
File.delete(tname) unless keep_temp==true
File.open("#{fname}.txt"){|txt| txt.read}
end
txt = tessrack("data-hold/tufte-intro.tif")
puts txt
Further discussion
There are many other practical uses for image manipulation than I can cover here. I plan to include more examples in a separate chapter on RMagick.